




 本文介绍了无向图和有向图的连通性概念,包括顶点连通性、连通图、连通分量、弱连通图、单向连通图和强连通图。重点讲解了GraphX如何利用节点ID标识连通分量,并通过Pregel算法实现连通图的识别,以及在实际案例中应用,如关键词聚类。
本文介绍了无向图和有向图的连通性概念,包括顶点连通性、连通图、连通分量、弱连通图、单向连通图和强连通图。重点讲解了GraphX如何利用节点ID标识连通分量,并通过Pregel算法实现连通图的识别,以及在实际案例中应用,如关键词聚类。
图的连通性介绍
无向图
- 顶点的连通性
在一个无向图 G 中,若从顶点 i 到顶点 j 有路径相连(当然从 j 到 i 也一定有路径),则称 i 和 j 是连通的。 - 连通图
在一个无向图 G 中,如果图中任意两点都是连通的,那么图被称作连通图 - 连通分量
无向图G的极大连通子图称为G的连通分量( Connected Component),这里的极大是指顶点个数极大。任何连通图的连通分量只有一个,即是其自身,非连通的无向图有多个连通分量
有向图
- 弱连通图
有向图的底图(无向图)是连通图,则是弱连通图。简单来说就是把所有有向边变成无向边,若此时图连通,则是弱连通图。 - 单向连通图
有向图中,任意结点对中,至少从一个到另一个是可达的,就是单向连通。如下图,A能够到C,但C不能到A
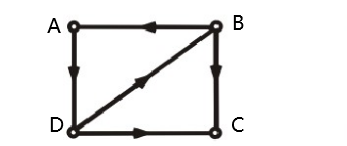
- 强连通图
有向图中,强连通图是任意对中都互相可达。 - 强连通分量
有向图的极大强连通子图,称为强连通分量。对于一个有向图,它不一定是强连通的,但可以分为几个极大的强连通子图。
下图中,子图{1,2,3,4}为一个强连通分量,因为顶点1,2,3,4两两可达。{5},{6}也分别是两个强连通分量
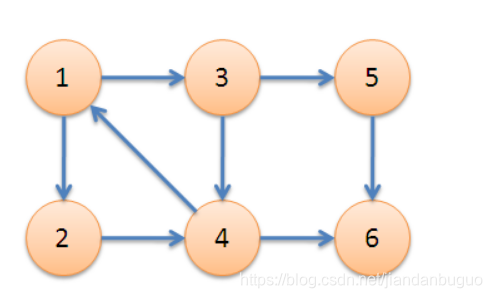
ConnectedComponents
简介
ConnectedComponents即连通分量。Graphx用图中顶点的id来标识节点所属的连通体,同一个连通体的编号是采用该联通体中最小的节点id来标识的。
寻找连通图在一些场景中是图计算的核心应用。比如:以关键词集合识别集群。以每个定点表示每一项(ltem),以边代表它们之间的联系,或者认为他们之间具有相似性。
核心思想
用节点的id来表示连通分量,将自身id传递给邻居节点(即一个Edge两端的节点),能够发送消息的在同一个连通分量中。消息的内容是将节点id发送给比当前id大的id,这样就能够保证同一连通分量中的分支id是最小的,同时发送消息部分方向。
过程如下:
- ①首先初始化图,将图中顶点id作为顶点的属性,开始状态是每个节点单独作为一个连通分量,分量id是节点id;
- ②对于每条边,如果边两端节点属性相同(说明两个节点位于同一连通分量中),不需要发送消息,否则将较小的属性发送给较大属性的节点;
- ③同一个节点对于收到的多个消息,只接收最小的消息;
- ④节点将自身属性记录的id与收到的消息中的id进行比较,采用最小的id更新自己的属性。
- 迭代②③④
源码
object ConnectedComponents {
/**
* 返回一个图,图中节点的属性是当前连通分量中最小的顶点id
* */
def run[VD: ClassTag, ED: ClassTag](graph: Graph[VD, ED], maxIterations: Int): Graph[VertexId, ED] = {
// 规定最大迭代次数必须大于0
require(maxIterations > 0, s"Maximum of iterations must be greater than 0," +
s" but got ${maxIterations}")
// 初始化图:将图中顶点的id作为顶点属性
val ccGraph = graph.mapVertices { case (vid, _) => vid }
// 一条边上两个顶点,将id较小的顶点的属性发送给id较大的顶点,目的是使最终连通分支的id属性为最小的节点id
// 如果边的两个顶点属性相同,则说明已经在同一个连通分支,不需要发送消息
def sendMessage(edge: EdgeTriplet[VertexId, ED]): Iterator[(VertexId, VertexId)] = {
if (edge.srcAttr < edge.dstAttr) {
Iterator((edge.dstId, edge.srcAttr))
} else if (edge.srcAttr > edge.dstAttr) {
Iterator((edge.srcId, edge.dstAttr))
} else {
Iterator.empty
}
}
// 初始化消息,初始给定一个最大值,然后较大的节点id在接收到较小节点id时能够更新自己的属性
val initialMessage = Long.MaxValue
// Pregel是另一个算法详情见代码结束下方链接
val pregelGraph = Pregel(ccGraph, initialMessage,
maxIterations, EdgeDirection.Either)(
// 比较当前属性值和接受到的id,取小的并更新属性
vprog = (id, attr, msg) => math.min(attr, msg),
sendMsg = sendMessage,
// 合并消息,接受多条消息时,先比较取最小的,在进行更新属性操作
mergeMsg = (a, b) => math.min(a, b))
// 用于取消缓存
ccGraph.unpersist()
pregelGraph
} // end of connectedComponents
// 当迭代次数没写时,代用该方法默认传入int类型的最大值
def run[VD: ClassTag, ED: ClassTag](graph: Graph[VD, ED]): Graph[VertexId, ED] = {
run(graph, Int.MaxValue)
}
}
案例
数据准备
people.csv
4,Dave,25
6,Faith,21
8,Harvey,47
2,Bob,18
1,Alice,20
3,Charlie,30
7,George,34
9,Ivy,21
5,Eve,30
10,Lily,35
11,Helen,35
12,Ann,35
links.csv
4,Dave,25
6,Faith,21
8,Harvey,47
2,Bob,18
1,Alice,20
3,Charlie,30
7,George,34
9,Ivy,21
5,Eve,30
10,Lily,35
11,Helen,35
12,Ann,35
图结构如下
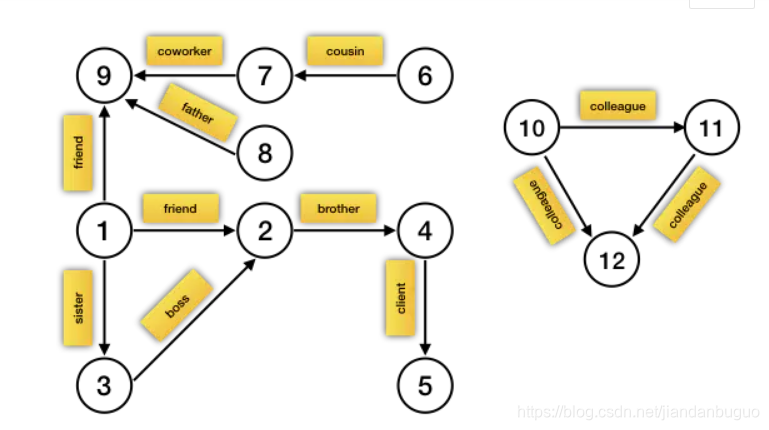
代码:
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// 定义一个Person样例类
case class Person(name: String, age: Int)
object ConnectedComponents {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ConnectedComponentsDemo").setMaster("local[*]")
val sc = new SparkContext(conf)
val people = sc.textFile("in/people.csv")
// vertices
val peopleRDD: RDD[(VertexId, Person)] = people.map(line => line.split(","))
.map(row => (row(0).toLong, Person(row(1), row(2).toInt)))
val links = sc.textFile("in/links.csv")
// edges
val linksRDD: RDD[Edge[String]] = links.map({line =>
val row = line.split(",")
Edge(row(0).toInt, row(1).toInt, row(2))
})
val peopleGraph: Graph[Person, String] = Graph(peopleRDD, linksRDD)
// spark graphX已经封装了connectedComponents,直接使用即可
val cc = peopleGraph.connectedComponents()
// 按照连通分量id排序输出
cc.vertices.collect().sortBy(x=>x._2).foreach(println)
}
}
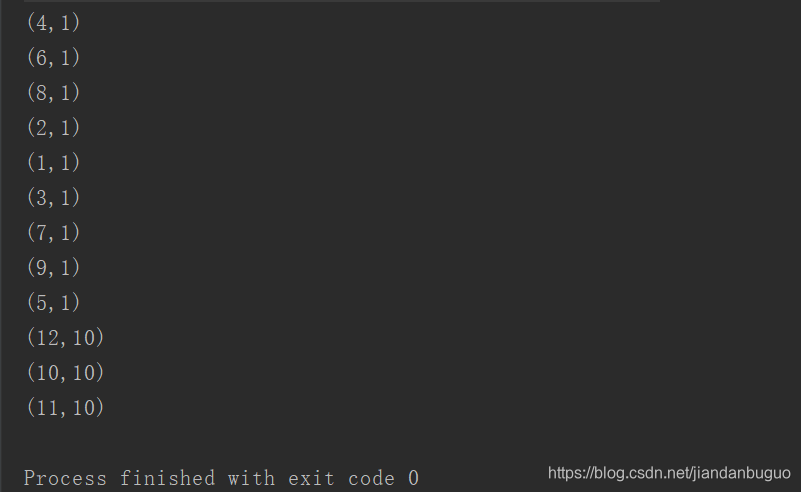
有结果可见,新的graph会将原来的graph的属性丢失,若想要显示,可以join原来的graph
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// 定义一个Person样例类
case class Person(name: String, age: Int)
object ConnectedComponents {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ConnectedComponentsDemo").setMaster("local[*]")
val sc = new SparkContext(conf)
val people = sc.textFile("in/people.csv")
// vertices
val peopleRDD: RDD[(VertexId, Person)] = people.map(line => line.split(","))
.map(row => (row(0).toLong, Person(row(1), row(2).toInt)))
val links = sc.textFile("in/links.csv")
// edges
val linksRDD: RDD[Edge[String]] = links.map({line =>
val row = line.split(",")
Edge(row(0).toInt, row(1).toInt, row(2))
})
val peopleGraph: Graph[Person, String] = Graph(peopleRDD, linksRDD)
// spark graphX已经封装了connectedComponents,直接使用即可
val cc = peopleGraph.connectedComponents()
// 与原来的图join,cc代表新图的属性,p_id代表就图的属性(Person)
val newGraph = cc.outerJoinVertices(peopleRDD)((id, cc_id, p_id)=>(cc_id,p_id.get.name,p_id.get.age))
cc.vertices.map(_._2).collect.distinct.foreach( // 获取连通分量的id
id =>{
// subgraph用于截取满足条件的子图
val sub = newGraph.subgraph(vpred = (id1, id2) => id2._1==id)
println(sub.triplets.collect().mkString(","))
})
}
}


















 6603
6603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









