




这是个博客的笔记。。。
https://www.sentiance.com/2018/05/03/loc2vec-learning-location-embeddings-w-triplet-loss-networks/
https://www.jiqizhixin.com/articles/2018-06-25-5
概述
场地映射算法的目标是根据位置测量数据,推测用户要去的目的地。本文开发了一种深度学习的解决方案,用于编码地理空间关系和描述位置周围情况的语义相似度模型。
模型的功能是输入一个经纬度坐标,通过模型的计算将其编码为一定维度的向量。其中,本文是以点附近的要素栅格化做CNN来建模,类似word2vec的embedding技术。
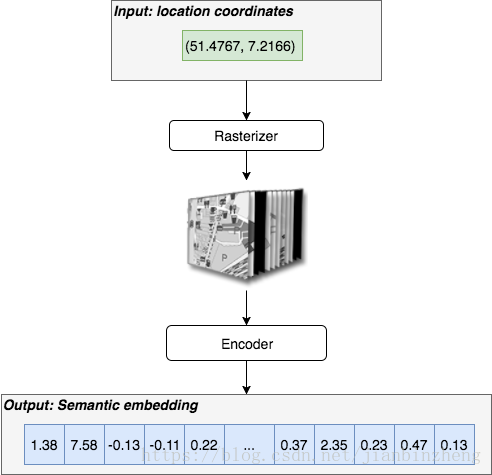
GIS数据栅格化
首先要考虑的是如何表达位置的环境信息。
本文通过将点附近的地理要素栅格化,形成12个栅格图层作为位置信息。
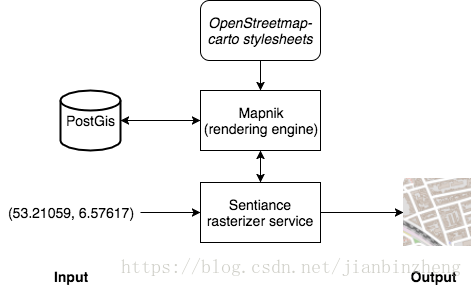
存在PostGIS中的OSM数据,由Mapnik渲染为OpenStreetmap-carto stylesheets样式的栅格地图。另外做个数据增强,空间上的旋转和平移等。

相似表示
语义相似的图像块对应于该空间中互相接近的嵌入向量
地理学第一定律:在地表空间中,所有事物是相互联系的,但是距离近的事物比距离远的事物间的联系更密切。
自监督学习:三重网络
三重网络:一种自监督学习方法,锚点,正例,反例,在embedding空间中使锚点和正例尽可能相近,和反例尽可能远离
在栅格化数据中数据增强的“平移旋转”的图像,作为正例。远离的位置,作为反例。
为防止神经网络只学习到简单的变换,在训练过程中为每个正实例随机启动或禁用了 12 个通道中的某些通道。这会迫使网络认为正例图像块与锚图像是近似的,即使该信息的某个随机子集是不同的(比如没有建筑、没有道路等)。
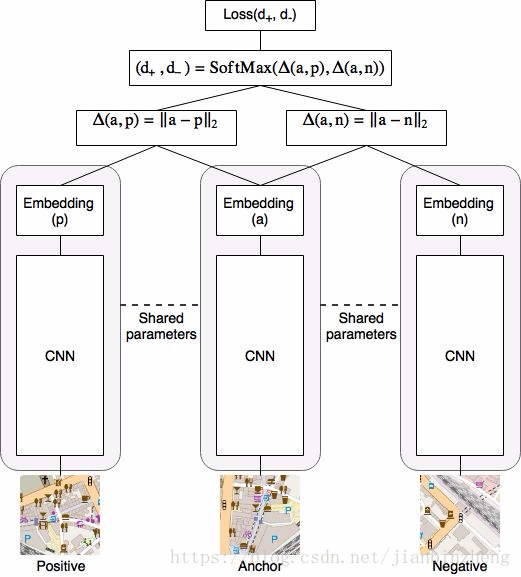
d+=e▵(a,p)e▵(a,p)+e▵(a,n) d + = e △ ( a , p ) e △ ( a , p ) + e △ ( a , n )
d−=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









