




https://zhuanlan.zhihu.com/p/363866684
【Uplift】特征选择篇
本文主要参考论文《Feature Selection Methods for Uplift Modeling》介绍Uplift Modeling中的特征筛选问题,主要包括”Filter方法“和”Embed方法“。具体实现参考CausalML源码。
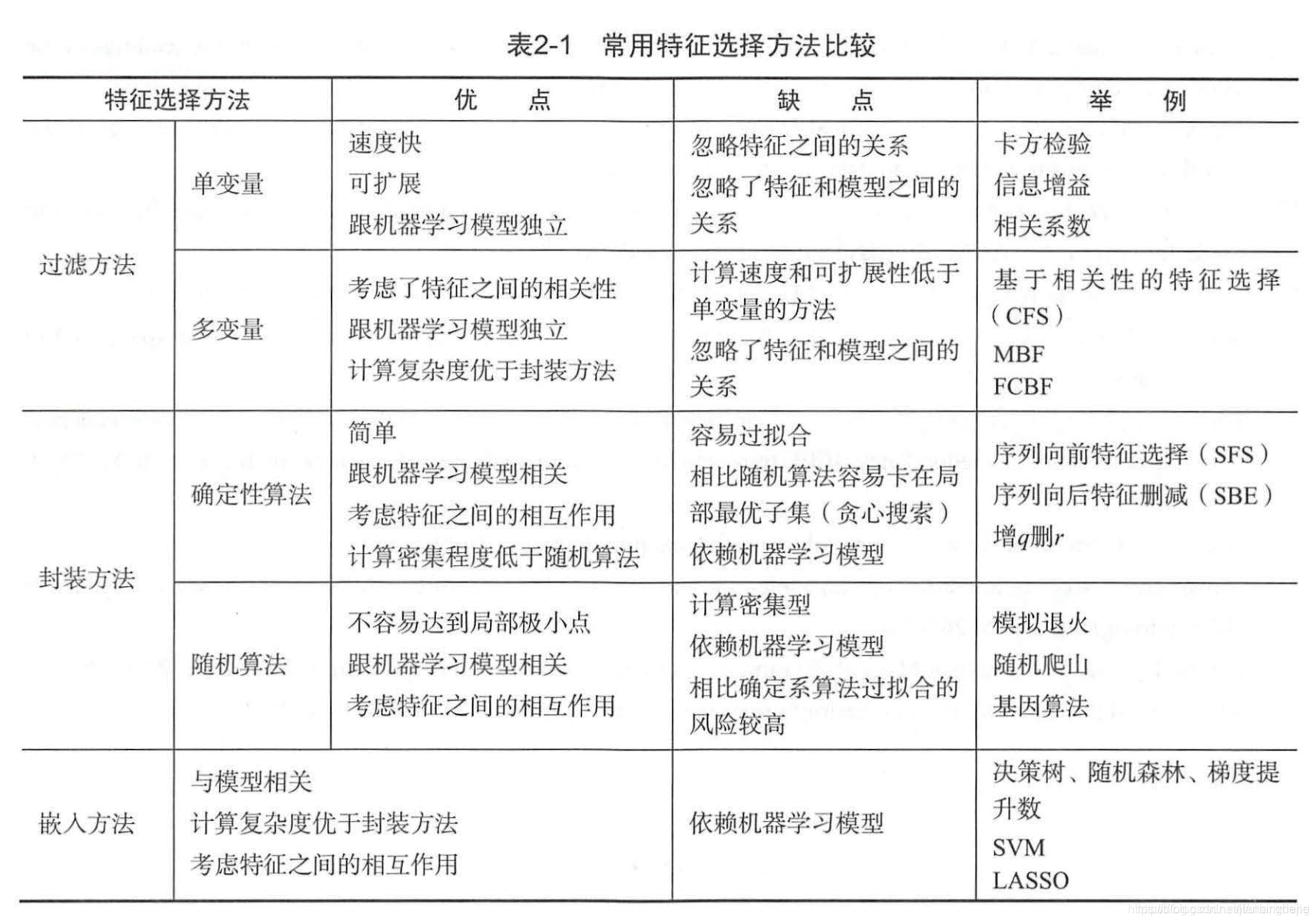
做好特征选择可以带来很多好处,包括计算效率、维护成本、可解释性、减少过拟合等。机器学习中有一系列进行特征选择的方法,主要可以分为3类,即”过滤方法“、”封装方法“、”嵌入方法“,下图是《美团机器学习实践》中的一个比较图。
简单说,”过滤方法“是通过特征变量和目标变量的一些指标计算并设定阈值做过滤;”封装方法“是通过不断尝试特征组合并借助模型效果来打分;”嵌入方法“是用模型训练过程中附带的关于特征重要性的描述作为依据。
Filter方法
过滤方法计算快,复杂度为 O ( m ⋅ n ) O(m\cdot n) O(m⋅n),m为特征数,n为样本数。
这里介绍了3种过滤方法,分别是F-filter、LR-filter、Bin-Based filter
F-filter和LR-filter
- F-filter首先用相关特征训练线性回归模型,特征包括”treatment、目标feature、二者交叉、常数项“,然后用交叉项系数的F-statistic作为得分
statsmodels.regression.linear_model.OLSResults.f_test
- LR-filter则基于逻辑回归模型,用交叉项系数的likelihood ratio test statistic作为得分
statsmodels.discrete.discrete_model.LogitResults.llf
Bin-Based方法
Step1:对目标特征排序,并按比例分为K组。
Step2:分别计算每组内,T组和C组中,outcome的分布散度,并求和。即
Δ = ∑ k = 1 K N k N D ( P k : Q k ) \Delta=\sum_{k=1}^{K} \frac{N_{k}}{N} D\left(P_{k}: Q_{k}\right) Δ=k=1∑KNNkD(Pk:Qk)
其中,假设outcome共有C类, P k = ( p k 1 , . . . , p k C ) P_k=(p_{k1},...,p_{kC}) Pk=(p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1452
1452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









