







 本文介绍了傻瓜式爬虫工具web scraper的使用方法,包括基本使用步骤、如何进行翻页抓取和抓取二级页面信息。以抓取知乎大V的文章为例,详细阐述了从获取链接到进入详情页的完整过程。
本文介绍了傻瓜式爬虫工具web scraper的使用方法,包括基本使用步骤、如何进行翻页抓取和抓取二级页面信息。以抓取知乎大V的文章为例,详细阐述了从获取链接到进入详情页的完整过程。
傻瓜式爬虫工具web scraper

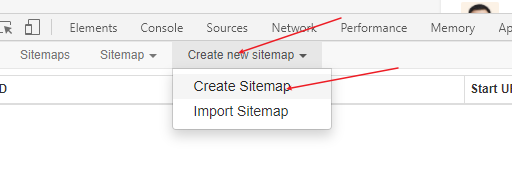
1、 基本使用
举例:抓取知乎大V发布的文章
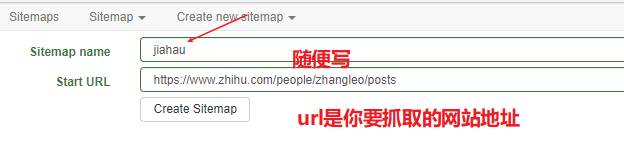
我们想吧这些都抓取下来 地址:https://www.zhihu.com/people/zhangleo/posts






超链接公式=HYPERLINK(d2,“点击查看”)
2、翻页抓取方法

#做翻页怎么做
# 其实特别简单 只需要改url就可以了
# 1.找到有规律的链接作为URL
知乎上总共有四页
https://www.zhihu.com/people/zhangleo/posts?page=[1-4:1]
https://www.zhihu.com/people/zhangleo/posts?page=2
https://www.zhihu.com/people/zhangleo/posts?page=3
https://www.zhihu.com/people/zhangleo/posts?page=4
# 后面的page也不一样
# 找到差值 就是页面间的数字相差 1

https://www.zhihu.com/people/zhangleo/posts?page=[1-4:1]

翻页url里写页数
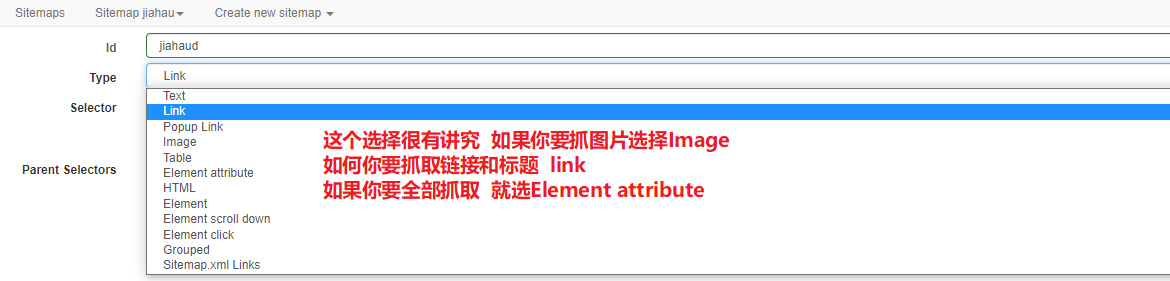
3、抓取二级页面信息



这是第一步 选好了 点后抓取局部的 点击wwww任意地方


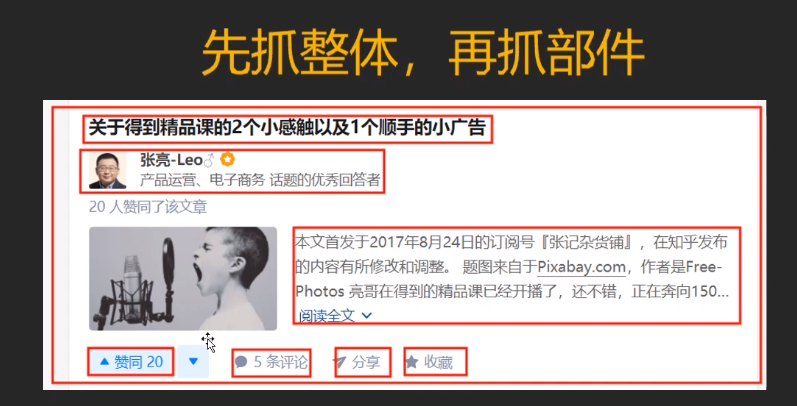
爬取二级页面的内容


制作翻页器
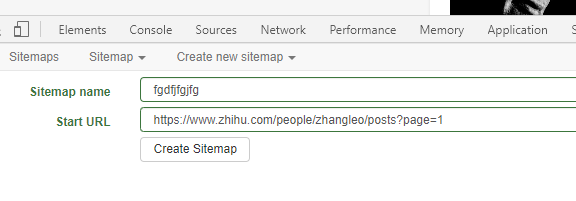
这一页还是一样 url添加第一页的URL
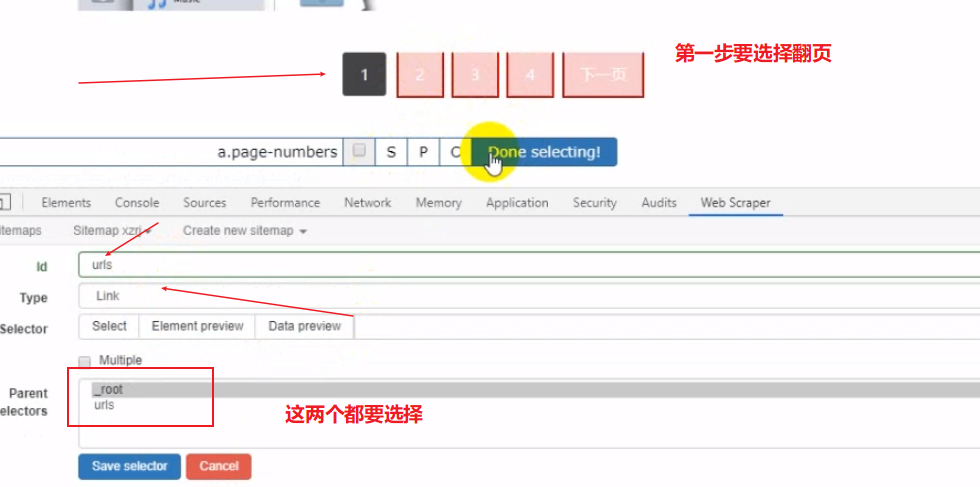
第一步要选择翻页数字link类型
第二部才选择内容部分
进入详情页的方法
第一步 首先按正常来获取链接地址(标题栏)
第二部 进入你刚才创建的链接下面 比如:links 点击灰色的地方
1.进入links 之后 不要点击Add New Selector 选项 因为我们要的数据在第二层上面 所以
先点击链接跳转到需要的页面 :::注意 如果页面 打开新的话 我们就需要Url复制 黏贴到刚才的项目中
2. 然后点击add new selecotr 选择自己需要的那些数组

















 4201
4201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









