



 文章讨论了递归实现斐波那契数列和链式二叉树时,由于计算机与人类思维的差异导致的不同时间复杂度,提醒开发者在编程时要考虑计算机执行过程,以优化性能。
文章讨论了递归实现斐波那契数列和链式二叉树时,由于计算机与人类思维的差异导致的不同时间复杂度,提醒开发者在编程时要考虑计算机执行过程,以优化性能。
在递归中,我们有时是相同的思路,但很可能导致截然不同的两种完全不同的时间复杂度
今天,我将以递归实现斐波那契数列和递归实现链式二叉树的时间复杂度的问题进行相关的讨论
这其实是一个数学问题,这道题题很简单就是通过递归实现二叉树的深度的求解(这里我不再多做赘述)
这里我主要讨论的是


这里我主要讨论的是这两种写法的区别,为什么第一个会执行通过,而第二个会超时呢;
首先我们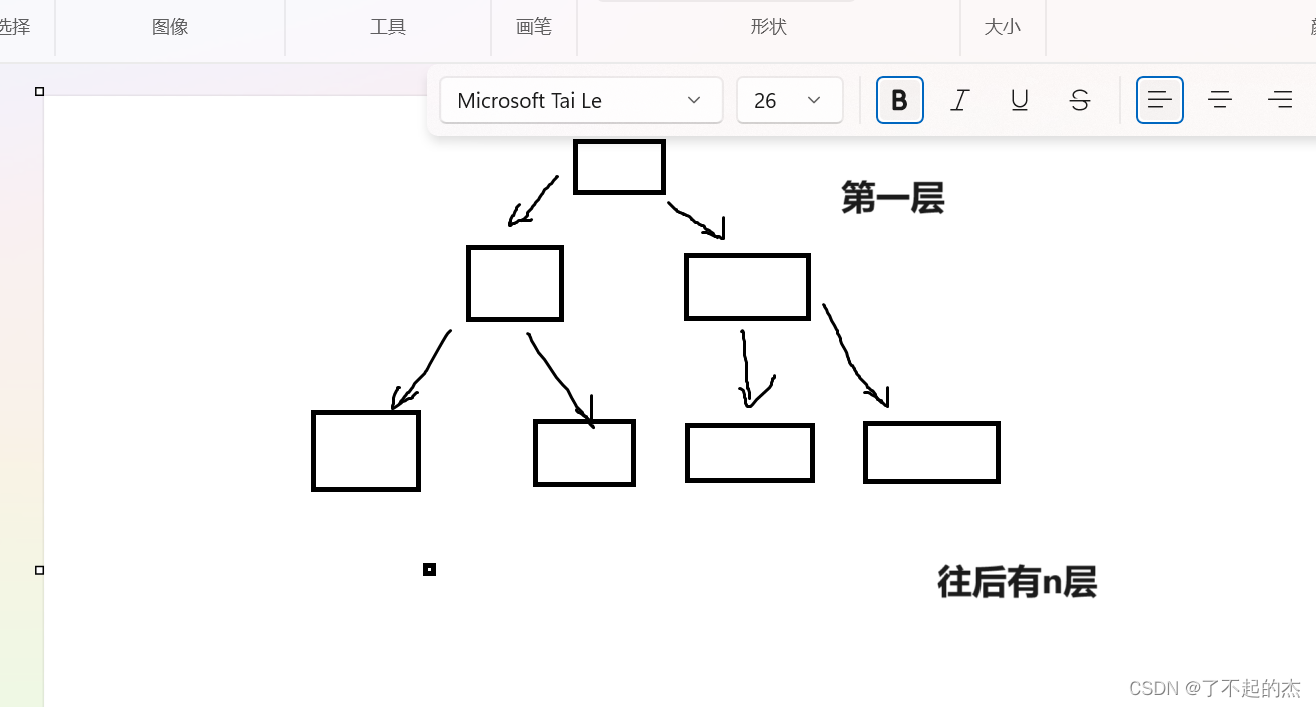
如果是采用第一种计算毫无疑问,因为建立了n个函数栈帧,所以第一种写法的复杂度是o(n),而第二种就完全不同,我们来分析一下第二种的复杂度
首先呢,第一层肯定只调用了一次毫无疑问(这里我先说明第一种写法就是链式二叉树的每一个节点都只调用的一次),然后第二层呢?首先我们建立函数栈帧,使得maxDepth(root->left)和maxDepth(root->right)都调用了一次进行了比较,这时,函数栈帧已经销毁,我们得到了他们的大小关系,但是,计算机并没有保留他们最后返回的值,因此,我们还要对其中更深的子树深度进行计算,所以说我又要调用一次第二层中的一个子树(left或者right),这样我们会得到一个结论,假设地n层背=被调用了m次,那么,第n+1层就会有子树背=被调用了2*m次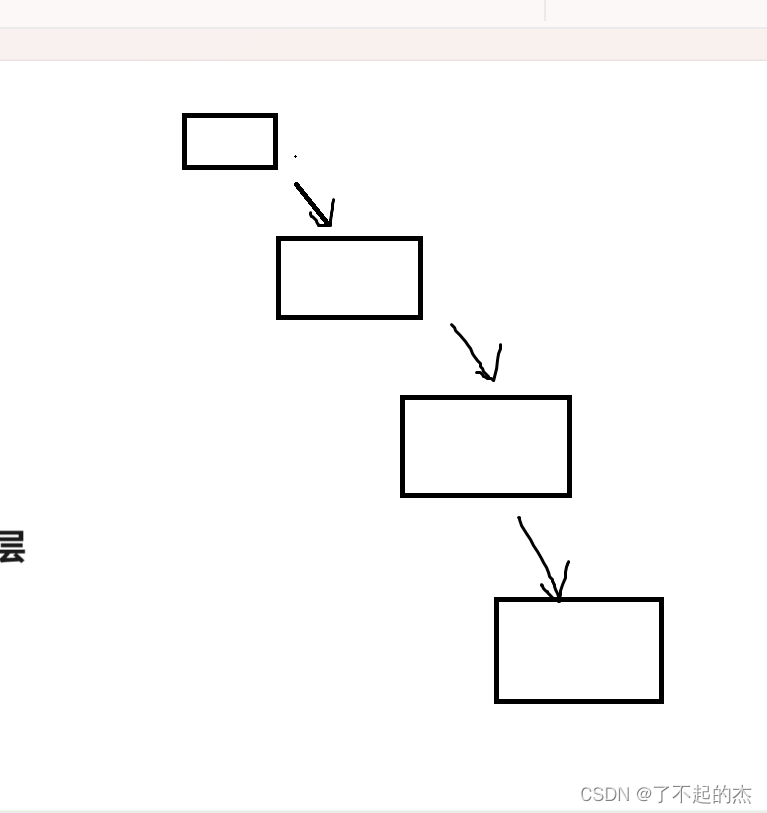
若一个二叉树如上图,那么导致的时间复杂度就会从o(n)变成o(2^n)这样就会使得时间超时
同样的道理,对于斐波那契数列,an和a(n-1)都会使得建立a(n-2)的函数栈帧,所以an,a(n-1)使得a(n-2)被算两次,a(n-1)和a(n-2)又会使得a(n-3)被算四次,以此类推,也会是o(2^n)
总结:很多时候,你的大脑觉得一致思想有时和计算机的思考方式不同,因此,写代码时,多从计算机的角度去思考,可能会使得我们的性能提升很大!





















 到【灌水乐园】发言
到【灌水乐园】发言








