 Kafka与Zookeeper的Leader选举解析
Kafka与Zookeeper的Leader选举解析





 本文探讨了Kafka与Zookeeper在Leader选举中的不同之处。Zookeeper的内部选举确保集群中的一台机器成为领导者,而Kafka利用Zookeeper的分布式锁功能进行副本间的选举。两者数据同步的对象也不同,Zookeeper同步单个Znode,而Kafka在不同副本间同步数据。此外,介绍了cursor框架提供的两种选举方式,包括leaderLatch和leaderElection。
本文探讨了Kafka与Zookeeper在Leader选举中的不同之处。Zookeeper的内部选举确保集群中的一台机器成为领导者,而Kafka利用Zookeeper的分布式锁功能进行副本间的选举。两者数据同步的对象也不同,Zookeeper同步单个Znode,而Kafka在不同副本间同步数据。此外,介绍了cursor框架提供的两种选举方式,包括leaderLatch和leaderElection。
在kafka中,同个topic下的partition分布在多个broker中,topic下的partitions使用zookeeper进行分布式协调,可以说kafka与zk是牢牢联系在一起的。但其中,都存在leader选举、主从复制、同步有效个数(zk是超过一半,kafka则是在isr列表中个数),在学习的初始造成一些混淆与困惑。
认清zookeeper的leader选举的内与外
内
一般书籍或者网络上提到zk的leader选举,指是的zk集群内部多台zk机器的选举。zk集群中多台机器都会存在全量数据,有且只有一台机器是zk集群的leader,负责zk集群的写入,事务提交等工作。但leader宕机时候,zk切换到leader选举模式(平时是数据同步,即进行数据复制模式),每台机器都根据zxid和serverId投票出新的leader。zk在cap理论模型中,支持的是ap,也即会存在不可用的风险,这也是被诟病作为服务治理配置中心的缺点。且客户端在连接的zk节点(客户端可以连接zk集群中任何一台机器,读的时候在连接的机器上进行,写的时候由连接的机器转发到leader进行)断开时候,客户端重连新的zk机器,也只会选择zxid不小于当前客户端缓存的机器。
外
集群管理是zk输出给外部的能力,如kafka的partitions副本使用zk提供的集群管理功能,达到多个partition副本间能进行leader选举。外部的机器在kafka中的体现就是一个目录下的多个znode节点,如下图所示
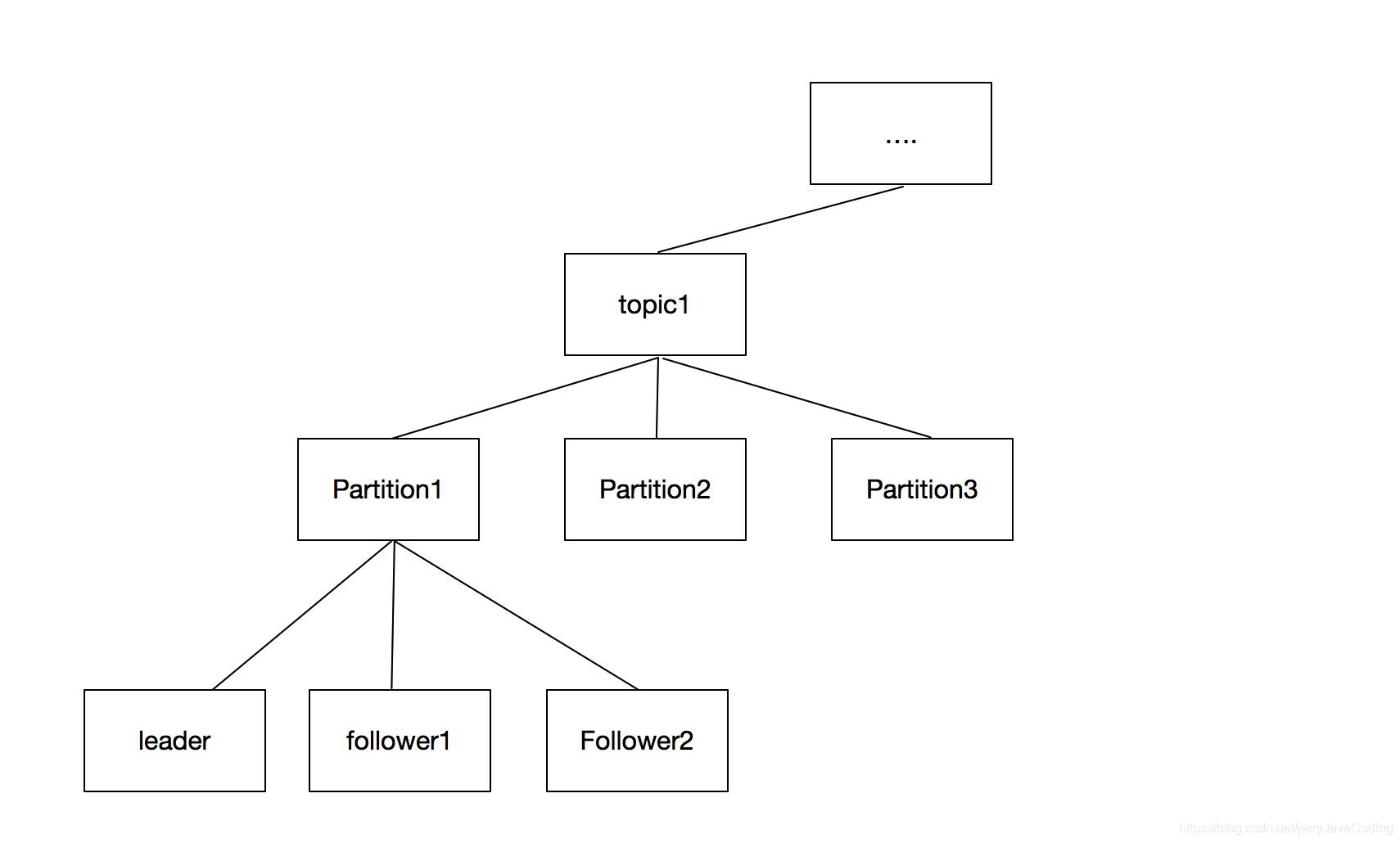
而上图所示的数据,在每个zk的集群节点机器上,都会冗余存储。kafka使用的leader选举并非是zk自身用于选举zk leader节点的方法(这是zk集群内部的能力,对于框架使用者不需要了解),而是使用类似zk提供的分布式锁能力,kafka各个副本节点只会有一个当选leader,当leader释放或者宕机,其他副本节点再重新当选leader。
zk与kafka数据同步的作用对象
zab协议是在zk集群节点上用于同步节点数据,所以同步的是同一个znode节点上的数据,比如将上图值为的“leader”的节点数据同步到集群中其他机器上的,同个目录结构上的”leader",使用类似两阶段提交的方式,由leader推行推送控制。
而kafka的主从同步是副本之间的,在zk中即是上图的“leader”节点将数据复制到“follower1”节点,不同的节点中复制不受zk管控,而且数据也不会存在zk中。kafka使用follower主动拉取leader的方式,定义isr列表进行同步,所以针对的是不同的znode之间的数据同步。
cursor提供的leader选举的两种方式
实际应用开发中使用cursor框架作为zk的客户端,提供了两种方式的leader选举
- leaderLatch
类似于java的countDownLatch,只有一个节点选中为leader,其他的节点处于await方法的阻塞中,当调用close或者失效时候断开给其他节点 - leaderElection
每个节点都能当选leader,当选后调用节点的takeLeadership方法,方法调用完后就会释放leader角色,如果希望能继续持有leader角色,就要写个死循环。该方法能对于领导权进行控制,在适当时候可以进行释放,相对于前者有更大的领导控制权(前者是当选后通知,其他一直处于阻塞)

















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









