



昨天发了单智能体的文章后,不少朋友留言说有些基础概念不太清楚,比如State到底是什么、节点之间怎么传递数据、为什么要用TypedDict等等。今天咱们就把这些知识点彻底讲透,保证你看完就能上手写代码。
说实话,我刚学LangGraph的时候也是一头雾水。什么State、Node、Edge,听着挺玄乎的。但真正理解了State的运作机制后,突然就开窍了——原来整个框架就是围绕"状态"这个核心在转。无论是单智能体还是多智能体这些都是基础。
一、先把环境准备好
咱们先把开发环境搞定,后面代码都能直接跑起来。打开终端,依次执行:
# 安装核心包
创建一个langgraph_demo.py文件,把API Key配置好:
import os
好了,准备工作完成。接下来进入正题。
二、State到底是个啥?
很多教程上来就讲概念,我换个思路。咱们先看一个实际场景:
假设你要做一个简单的计算器程序,流程是这样的:
- 用户输入一个数字,比如10
- 第一步:给这个数字加1
- 第二步:用上一步的结果减2
- 最后输出结果
传统写法可能是这样:
defcalculator(x):
这没问题,但如果流程复杂了呢?比如有10个步骤,每个步骤可能用到前面多个结果,代码就会很乱。
LangGraph的解决方案是:用一个共享的"状态"(State)来存储所有中间结果。每个处理步骤只需要:
- 读取State中需要的数据
- 处理完后,把结果写回State
- 不用管其他步骤的数据
这就是State的核心思想:一个在整个流程中共享的数据容器。
三、第一个例子:用字典做State
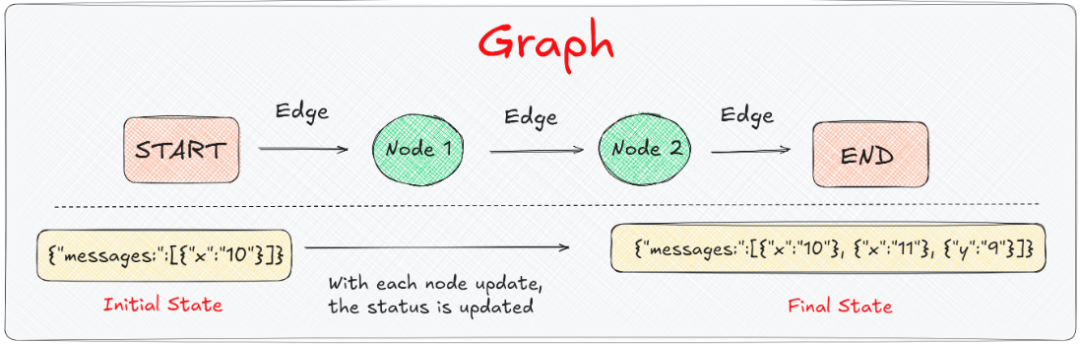
咱们把刚才的计算器用LangGraph实现一遍。完整代码如下,每行都加了注释:
from langgraph.graph import StateGraph, START, END
运行这段代码,你会看到:
加法节点收到的state: {‘x’: 10}
减法节点收到的state: {‘x’: 11}
最终状态: {‘x’: 11, ‘y’: 9}
看到了吗?关键点来了:
- addition节点只返回了
{"x": 11},但y没有丢 - subtraction节点返回了
{"y": 9},x也还在 - 最终状态包含了所有的更新
这就是LangGraph的魔法:节点只需要返回它要更新的部分,其他数据会自动保留。
看看图长什么样
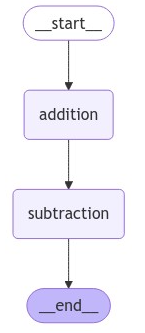
代码能跑是一回事,理解结构又是另一回事。咱们把这个图可视化出来:
from IPython.display import Image, display
你会看到一个流程图,清楚地显示了节点的连接关系。开发的时候这个功能特别有用,能一眼看出逻辑对不对。
四、进阶:用TypedDict让代码更严谨
用字典虽然灵活,但有个大问题:如果你不小心写错了key的名字,程序运行到那里才会报错。
比如这样:
defbuggy_function(state):
用了TypedDict后,IDE会给你代码提示,写错了key名编辑器就会提醒你。虽然代码多了几行,但避免了很多低级错误。
五、Reducer:状态更新的幕后功臣
现在来解答一个关键问题:为什么节点只返回部分数据,State就能自动合并?
答案是Reducer函数。每个State的key背后都有一个Reducer,默认行为是"覆盖"。我画个图帮你理解:
当前State: {“x”: 10}
节点返回: {“x”: 11}
Reducer执行: 把x从10改成11
结果State: {“x”: 11}
当前State: {“x”: 11}
节点返回: {“y”: 9}
Reducer执行: x不变,新增y
结果State: {“x”: 11, “y”: 9}
默认的Reducer很简单,就是更新或新增。但我们可以自定义更复杂的行为。
六、实战:维护消息列表
聊天机器人需要记住对话历史,每次都要往消息列表里追加新消息。如果用默认的Reducer(覆盖),每次都会丢失之前的对话。
这时候就需要operator.add这个Reducer:
import operator
运行结果:
node2收到的消息: [{'role': 'user', 'content': '你好'}]
看到了吗?用了operator.add之后,每次返回的消息列表会追加到现有列表中,而不是覆盖。这就是Reducer的威力。
七、接入真实的AI模型
铺垫了这么多,终于到激动人心的部分了——接入GPT做一个真正能聊天的机器人!
完整代码如下,建议你创建一个新文件chatbot.py:
import os
运行这段代码,你就有了一个能对话的AI助手!
不过这个版本有个问题:每次对话都是独立的,没有记忆。要实现带记忆的版本,需要这样改:
defchat_with_memory():
现在你可以这样聊:
你: 我叫小明
AI: 你好小明!很高兴认识你…
你: 我刚才说我叫什么?
AI: 你刚才说你叫小明。
看,AI能记住之前的对话了!
八、add_messages的秘密
可能你注意到了,我们用的是add_messages而不是operator.add。这两个有什么区别?
operator.add很简单粗暴:直接把两个列表拼起来。
add_messages更聪明:
- 每条消息都有唯一ID
- 如果新消息的ID和已有消息相同,就更新那条消息
- 如果ID不同,就追加新消息
看个例子:
from langgraph.graph.message import add_messages
这个特性在人机协作场景特别有用。比如用户可以修改AI的回复,然后继续对话。
九、源码解析:add_messages是怎么实现的?
有些同学喜欢刨根问底,咱们快速过一下核心逻辑(不想看可以跳过):
defadd_messages(left, right):
核心就是用ID来判断是更新还是追加。简单但很实用。
十、完整项目:支持多轮对话的智能助手
最后把所有知识点整合一下,做个功能完整的聊天助手:
import os
这个版本包含了:
- ✅ 完整的对话历史管理
- ✅ 系统提示词设置
- ✅ 异常处理
- ✅ 友好的交互界面
直接运行就能用!
十一、常见问题答疑
Q1: State可以存储什么类型的数据?
A: 理论上任何Python对象都行:字典、列表、自定义类、甚至函数。但建议用简单的数据结构,方便序列化和持久化。
Q2: 节点函数可以不返回任何东西吗?
A: 可以。如果节点只是做一些副作用操作(比如打印日志),可以返回空字典{}或者None。
Q3: 怎么调试State的变化?
A: 在每个节点函数里加print(state),就能看到每一步State的变化情况。
Q4: TypedDict是必须的吗?
A: 不是必须的,但强烈推荐。它能帮你在开发阶段就发现很多类型错误。
Q5: 对话历史会越来越长,怎么办?
A: 这是个好问题。可以定期裁剪历史,只保留最近N条消息。或者用摘要技术压缩历史信息。后面的文章会详细讲。
十二、总结
今天我们深入学习了LangGraph的核心——State管理:
- State是什么:在整个流程中共享的数据容器
- 基本用法:节点读取State,处理后返回更新的部分
- TypedDict:让代码更严谨,避免运行时错误
- Reducer机制:控制State的更新方式(覆盖、追加等)
- add_messages:智能管理消息列表的专用Reducer
- 实战应用:构建带记忆的聊天机器人
掌握了这些,你就能灵活构建各种LangGraph应用了。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











