



文章详细介绍了kohya_ss这一Stable Diffusion模型微调工具,重点讲解LoRA训练方法。涵盖本地安装步骤和云端使用方案,对比四种微调方法,指出LoRA是当前主流方案。提供关键参数设置和显卡优化建议,为不同需求用户提供本地部署和云端使用两种选择,适合小白入门学习。
目 录
前言
这篇文章来聊一聊关于kohya_ss工具
kohya_ss是一个专为Stable Diffusion模型训练设计的工具,主要用于使用LoRA方法对模型进行微调和训练。
功能与用途
- LoRA模型训练:kohya_ss允许用户通过LoRA(低秩适应)方法对Stable Diffusion模型进行微调。这种方法可以在不修改原始模型参数的情况下,插入新的网络层,从而实现轻量化的模型调校。
- 可视化界面:该工具提供了一个用户友好的可视化界面,用户可以通过图形界面轻松配置训练参数,进行数据处理和模型训练,适合初学者使用。
- 环境配置:kohya_ss支持在多种操作系统上运行,包括Linux和MacOS,用户需要配置Python环境和相关依赖库。
- 训练流程:用户可以通过简单的步骤进行模型训练,包括数据准备、参数设置和训练启动。该工具还支持对训练过程中的错误进行分析和处理。
kohya_ss
kohya_ss是用来训练LoRA模型的一个工具,目前已经集成了GUI界面,对于新手来说非常友好,毕竟总要比改文本内的参数更加直观吧?
下面是关于kohya_ss的安装教程,整个过程还是比较简单的。
安装步骤
需要找一个文件夹(不要出现中文),在地址栏输入cmd,按回车打开命令行窗口
然后依次复制以下命令到终端并按回车;
git clone --recurse-submodules https://github.com/bmaltais/kohya_ss.git
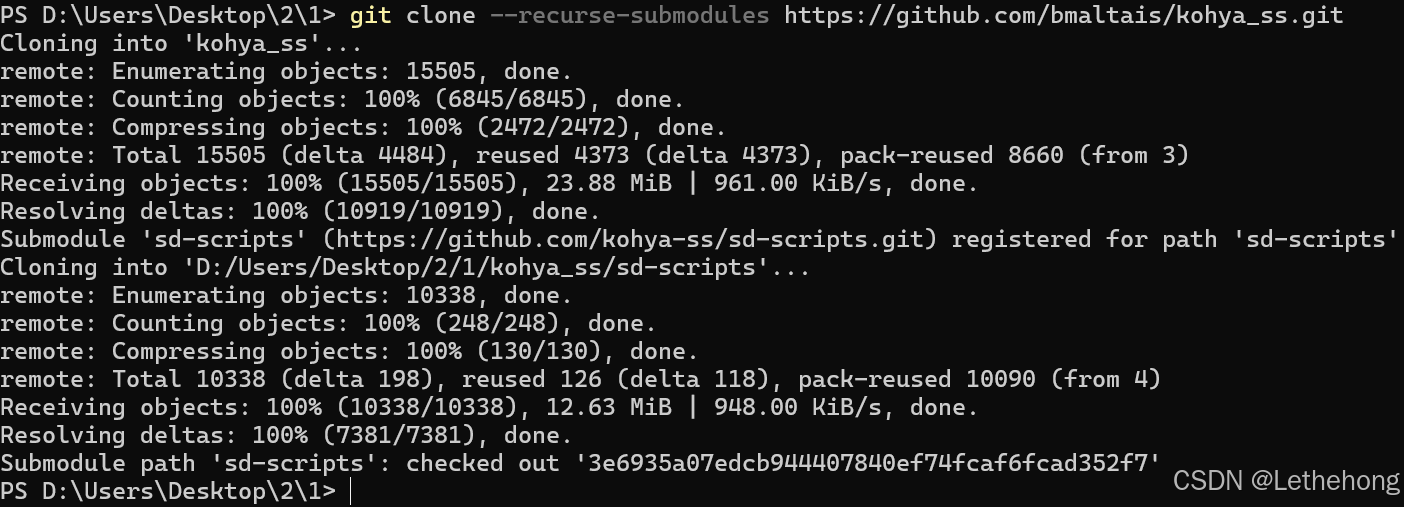
cd kohya_ss
python -m venv venv
.\venv\Scripts\Activate.bat

python.exe -m pip install--upgrade pip
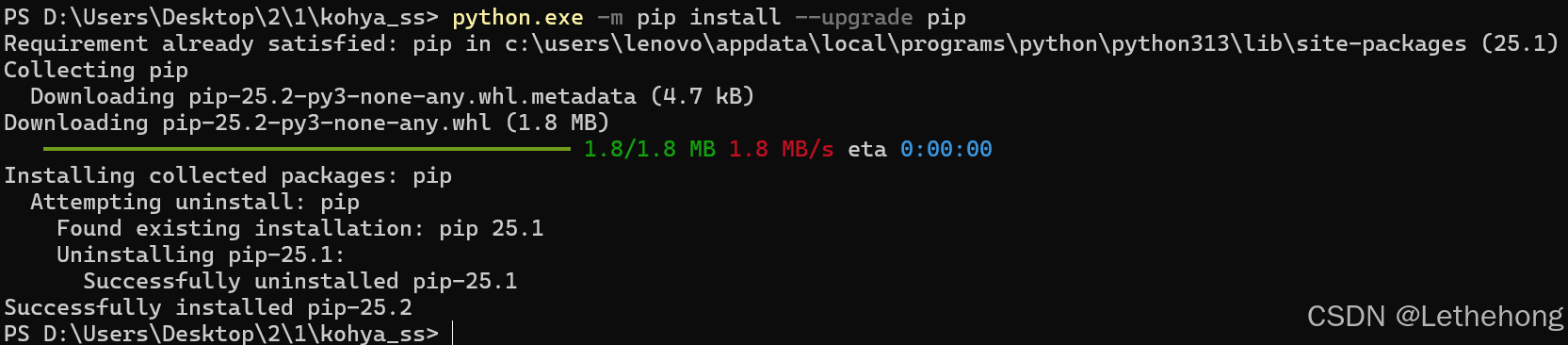
pip install
https://github.com/Nuullll/intel-extension-for-pytorch/releases/download/v2.1.10%2Bxpu/intel_extension_for_pytorch-2.1.10+xpu-cp310-cp310-win_amd64.whl
https://github.com/Nuullll/intel-extension-for-pytorch/releases/download/v2.1.10%2Bxpu/torch-2.1.0a0+cxx11.abi-cp310-cp310-win_amd64.whl
https://github.com/Nuullll/intel-extension-for-pytorch/releases/download/v2.1.10%2Bxpu/torchaudio-2.1.0a0+cxx11.abi-cp310-cp310-win_amd64.whl
https://github.com/Nuullll/intel-extension-for-pytorch/releases/download/v2.1.10%2Bxpu/torchvision-0.16.0a0+cxx11.abi-cp310-cp310-win_amd64.whl
继续安装
pip install-r requirements_windows.txt
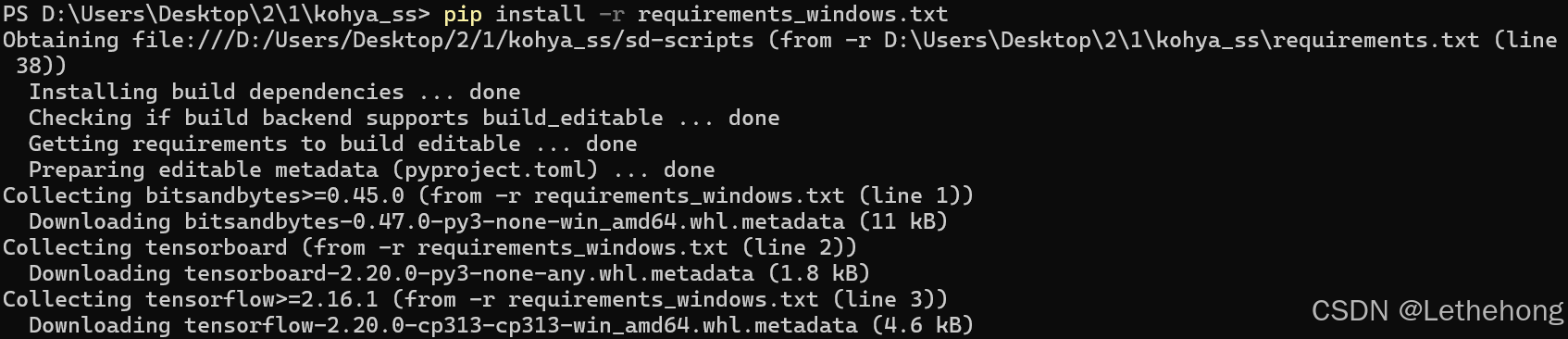
.\setup.bat
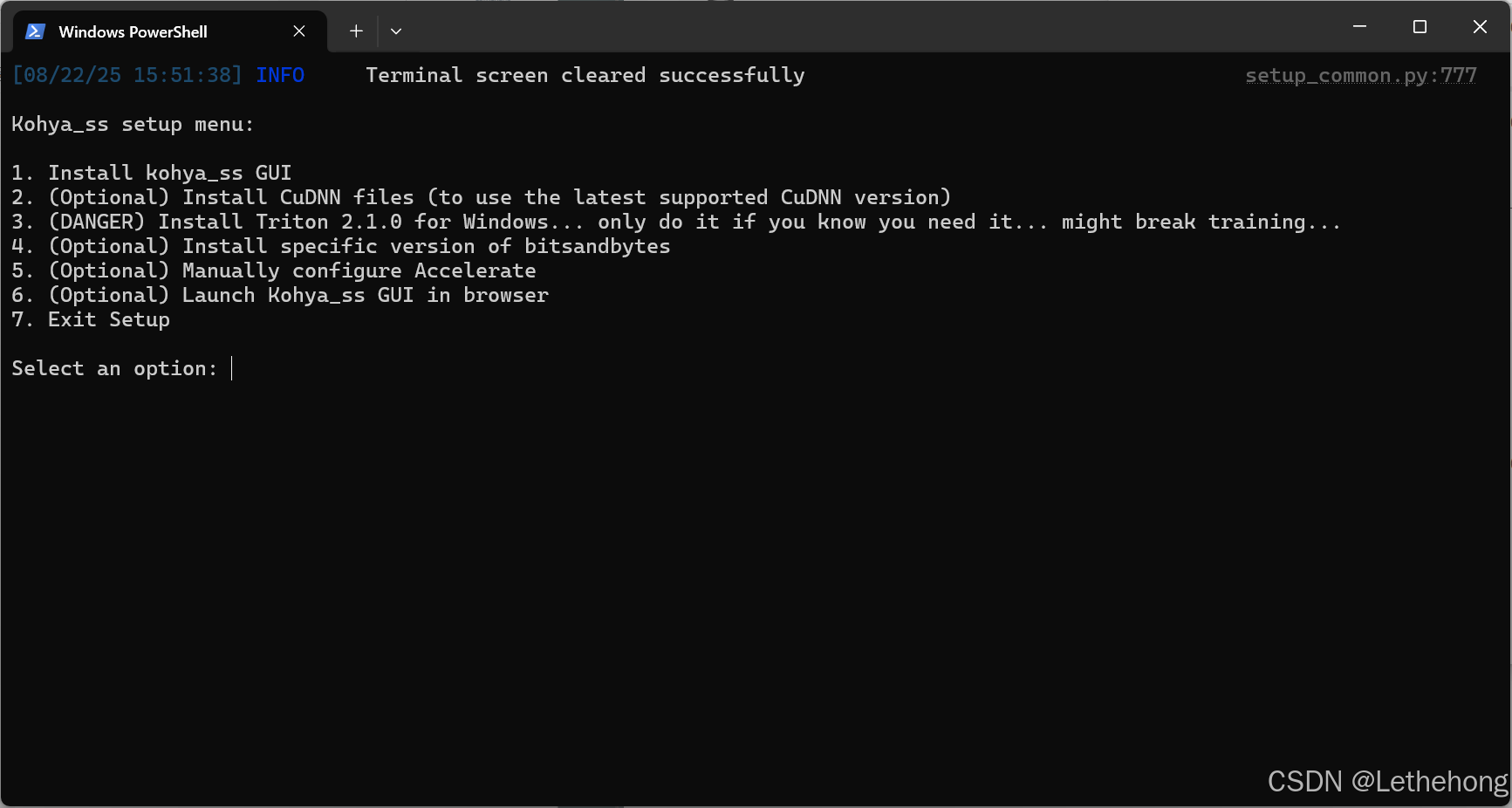
打开记事本,复制添加以下内容:
@echo off
chcp 65001
call venv\\Scripts\\activate.bat
python kohya_gui.py --use-ipex --inbrowser
@echo 启动完毕,请按任意键关闭
call pause
这样操作更简单:
创建启动器:
去kohya_ss文件夹根目录新建文本文档,把下面这段代码复制进去(记得改中文的话保留–language zh-CN参数):
@echo off
python webui.py --language zh-CN
保存时选择"所有文件",文件名改成start.bat。之后双击这个bat文件就能直接弹出网页训练界面。
显卡设置要点:
训练LoRA时注意这几个关键设置:
- 在【加速训练】选项卡里:混合精度选bf16,优化器千万别选带8bit的(比如adamw8bit就别用)
- 【高级参数】里必须把注意力模式改成sdpa
如果是A750显卡跑768x768分辨率,记得勾上"内存高效注意力"(A770 16G用户可以无视这点)
这些参数不按要求设的话,要么训练会报错,要么显存不够用。特别是优化器如果选错,训练过程会出现显存暴增的问题。
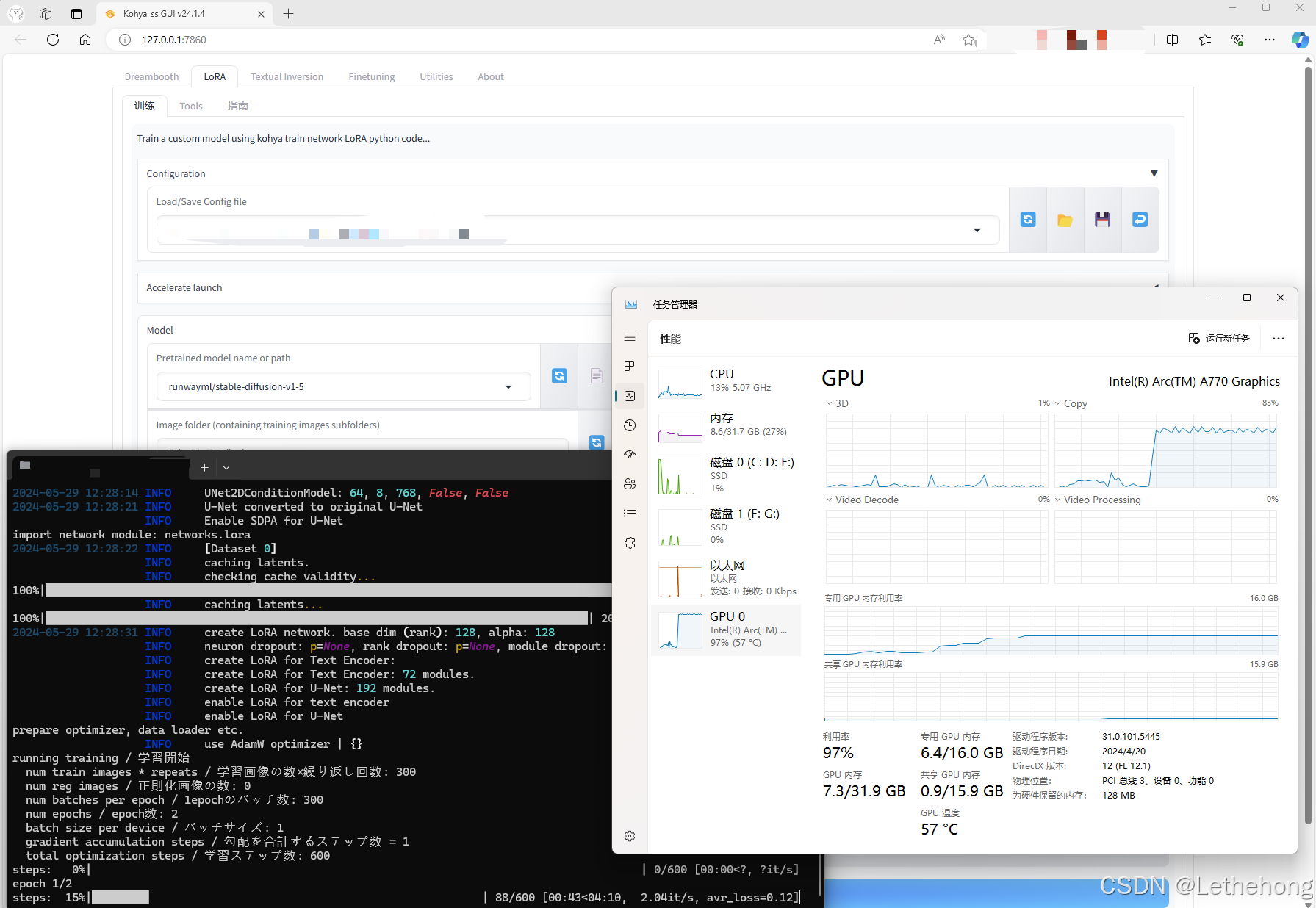
测试
参考资料
Nuullll:IPEX v2.1.10+xpu+oneapi
大家觉得在本地搞这么操作跟相比直接给你提供一个Web平台训练,谁方便?接下来给大家展示一下蓝耘平台的kohya_ss
先说说蓝耘这个平台
如何注册蓝耘智算平台
1.点击注册链接:蓝耘智算平台
2.进入下面图片界面,输入手机号并获取验证码,输入邮箱,设置密码,点击注册在这里插入图片描述
蓝耘是一家专业的GPU算力云服务提供商,基于行业领先的灵活的基础设施及大规模的GPU算力资源,为客户提供开放、高性能、高性价比的算力云服务,助力客户AI模型构建、训练和推理的业务全流程。
这里给大家送给福利。千万 Token 资源包福利都在送,感兴趣的赶紧来吧
https://console.lanyun.net/#/register?promoterCode=18586cc762
风吟kohya_ss-v2
说白了,就是专门提供GPU算力的云服务商。我之前用过他们的服务训练一些小模型,感觉还不错。这次蓝耘新发布了风吟kohya_ss-v2,直接web部署一站式使用,非常方便,并且响应速度确实挺快的。
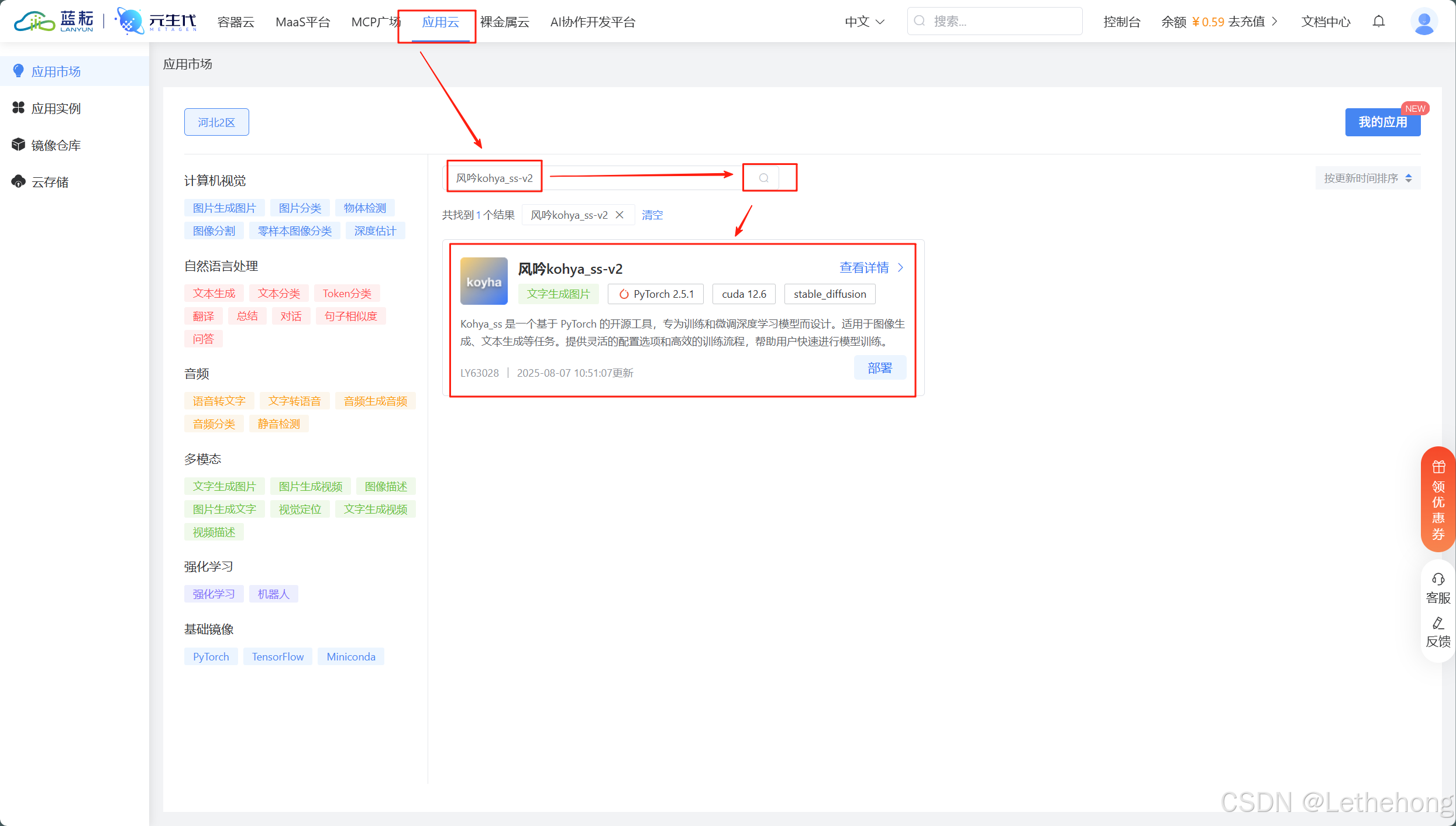
选择GPU和添加端口后,点击立即购买
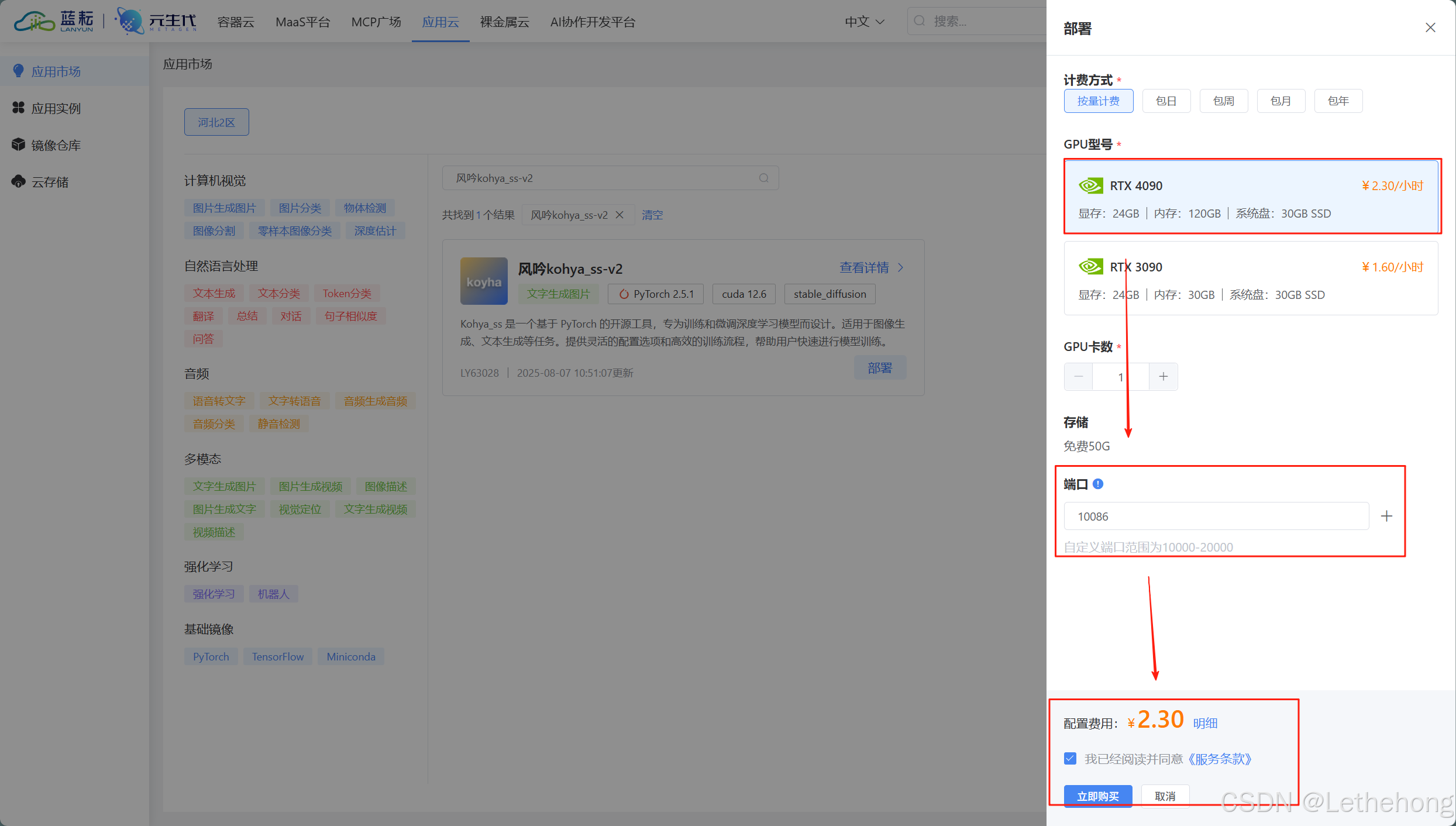
等待创建,然后开启
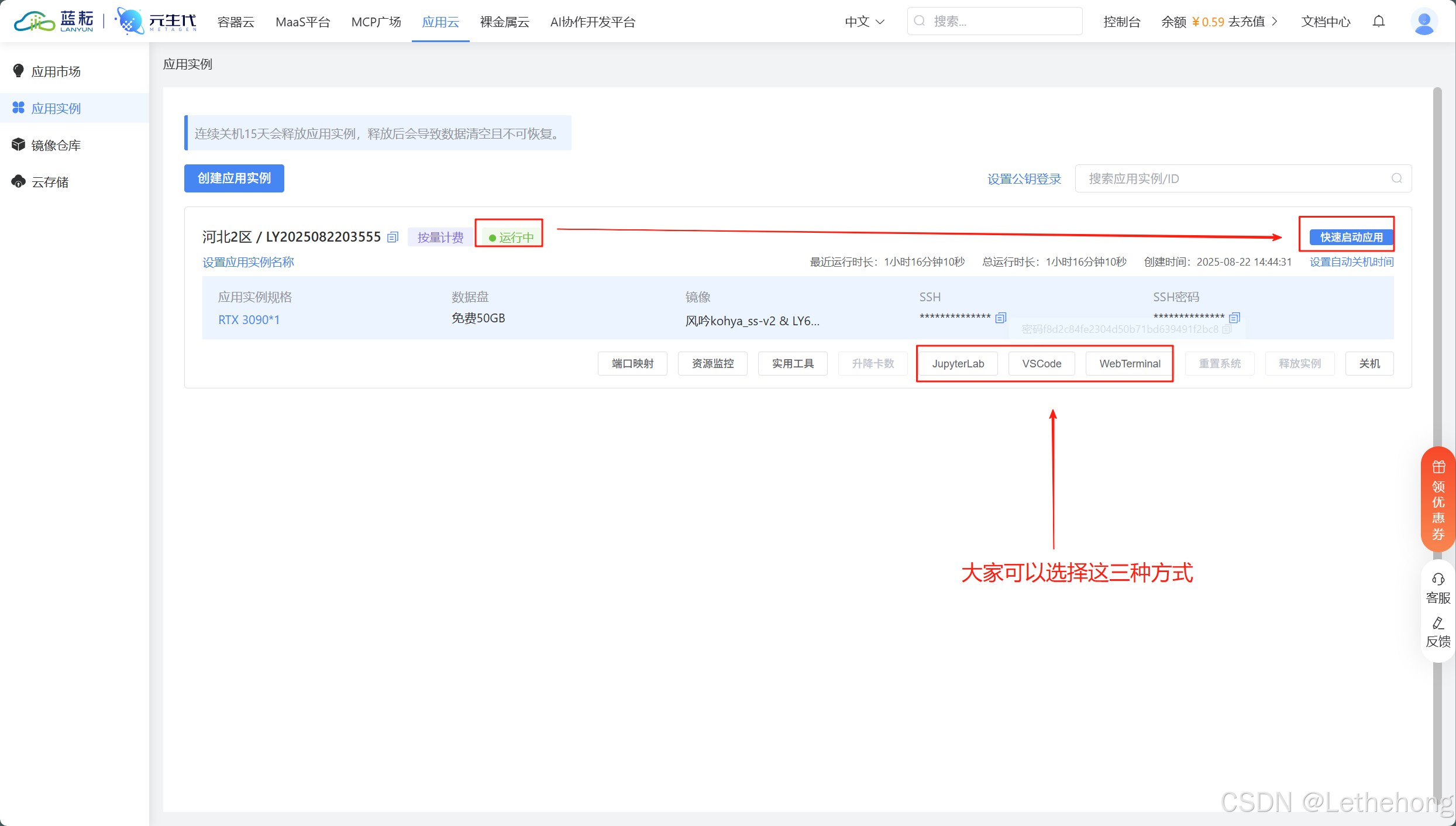
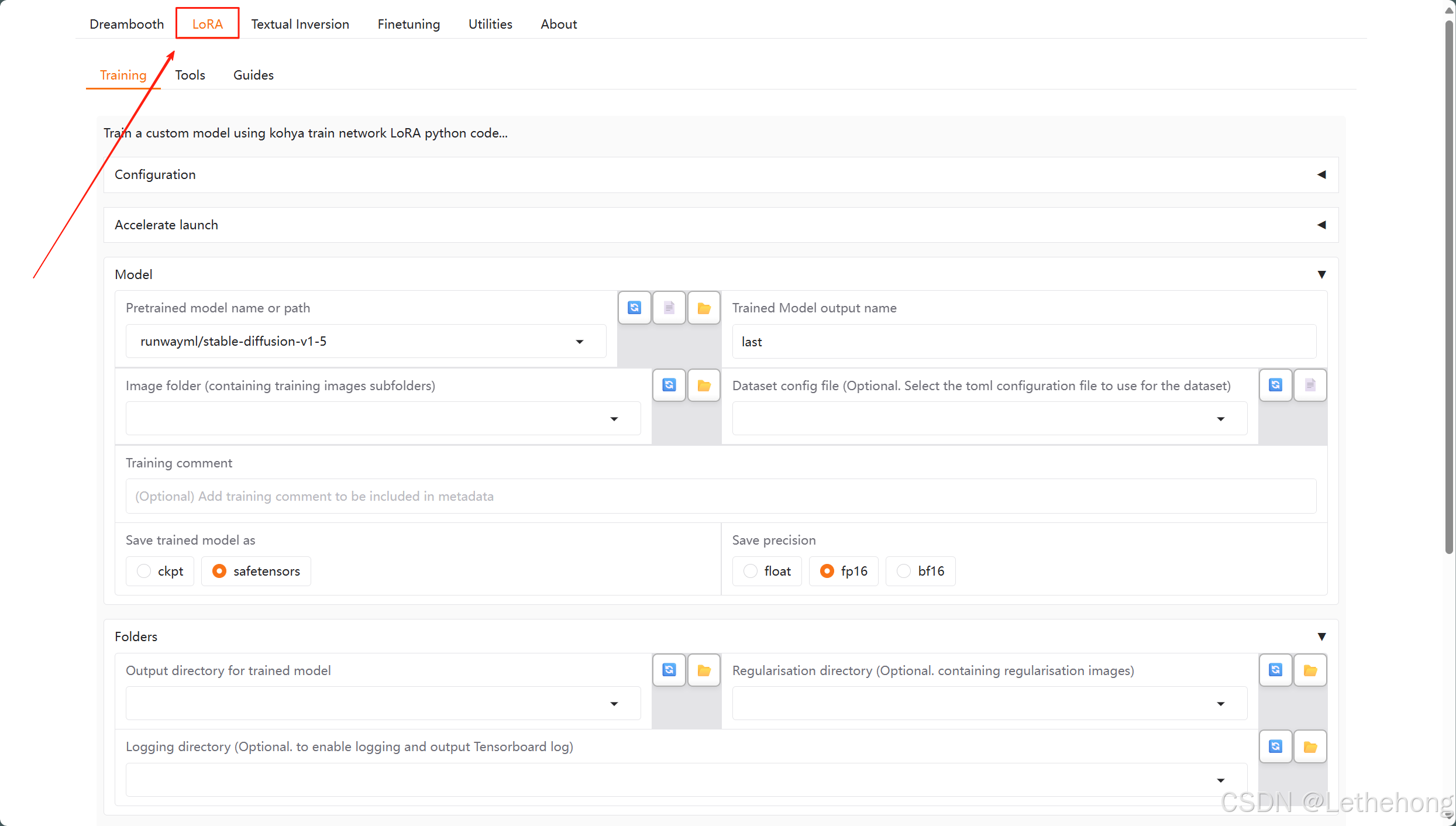
启动GUI后,进入页面:
stable diffusion模型微调方法
主要有 4 种方式:Dreambooth, LoRA(Low-Rank Adaptation of Large Language Models), Textual Inversion, Hypernetworks。它们的区别大致如下:
- Textual Inversion (也称为 Embedding),它实际上并没有修改原始的 Diffusion 模型, 而是通过深度学习找到了和你想要的形象一致的角色形象特征参数,通过这个小模型保存下来。这意味着,如果原模型里面这方面的训练缺失的,其实你很难通过嵌入让它“学会”,它并不能教会 Diffusion 模型渲染其没有见过的图像内容。
- Dreambooth 是对整个神经网络所有层权重进行调整,会将输入的图像训练进 Stable Diffusion 模型,它的本质是先复制了源模型,在源模型的基础上做了微调(fine tunning)并独立形成了一个新模型,在它的基本上可以做任何事情。缺点是,训练它需要大量 VRAM, 目前经过调优后可以在 16GB 显存下完成训练。
- LoRA 也是使用少量图片,但是它是训练单独的特定网络层的权重,是向原有的模型中插入新的网络层,这样就避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法, LoRA 生成的模型较小,训练速度快, 推理时需要 LoRA 模型+基础模型,LoRA 模型会替换基础模型的特定网络层,所以它的效果会依赖基础模型。
- Hypernetworks 的训练原理与 LoRA 差不多,目前其并没有官方的文档说明,与 LoRA 不同的是,Hypernetwork 是一个单独的神经网络模型,该模型用于输出可以插入到原始 Diffusion 模型的中间层。 因此通过训练,我们将得到一个新的神经网络模型,该模型能够向原始 Diffusion 模型中插入合适的中间层及对应的参数,从而使输出图像与输入指令之间产生关联关系。
总儿言之,就训练时间与实用度而言,目前训练LoRA性价比更高,也是当前主流的训练方法。
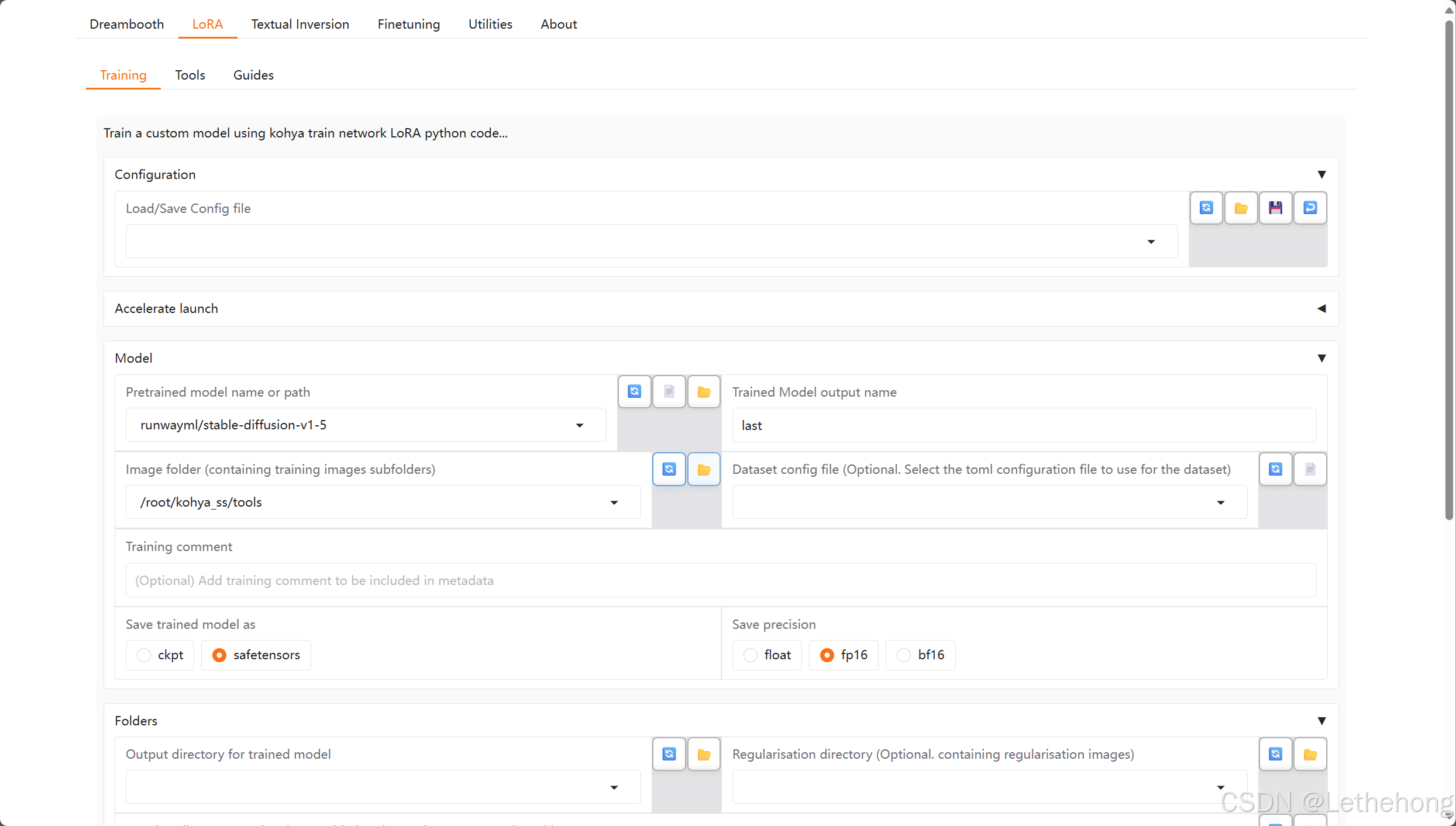
选择最上面的LoRA选项卡,然后需要在页面 内配置一些参数。
比较关键的几个参数如下:
- Model–>Pretrained model name or path: 这里配置你的SD基础模型,我们这里用的1.5,需要指定其路径;关于SD1.5模型的下载,在1.1步骤中也有响应链接;
- Model–>Trained Model output name:给你的模型起个名字;
- Model–>Image folder (containing training images subfolders):训练图像数据集的目录;
- Folders–>Output directory for trained model:训练结果的保存路径;
- Folders–>Logging directory (Optional. to enable logging and output Tensorboard log):训练日志的保存路径;
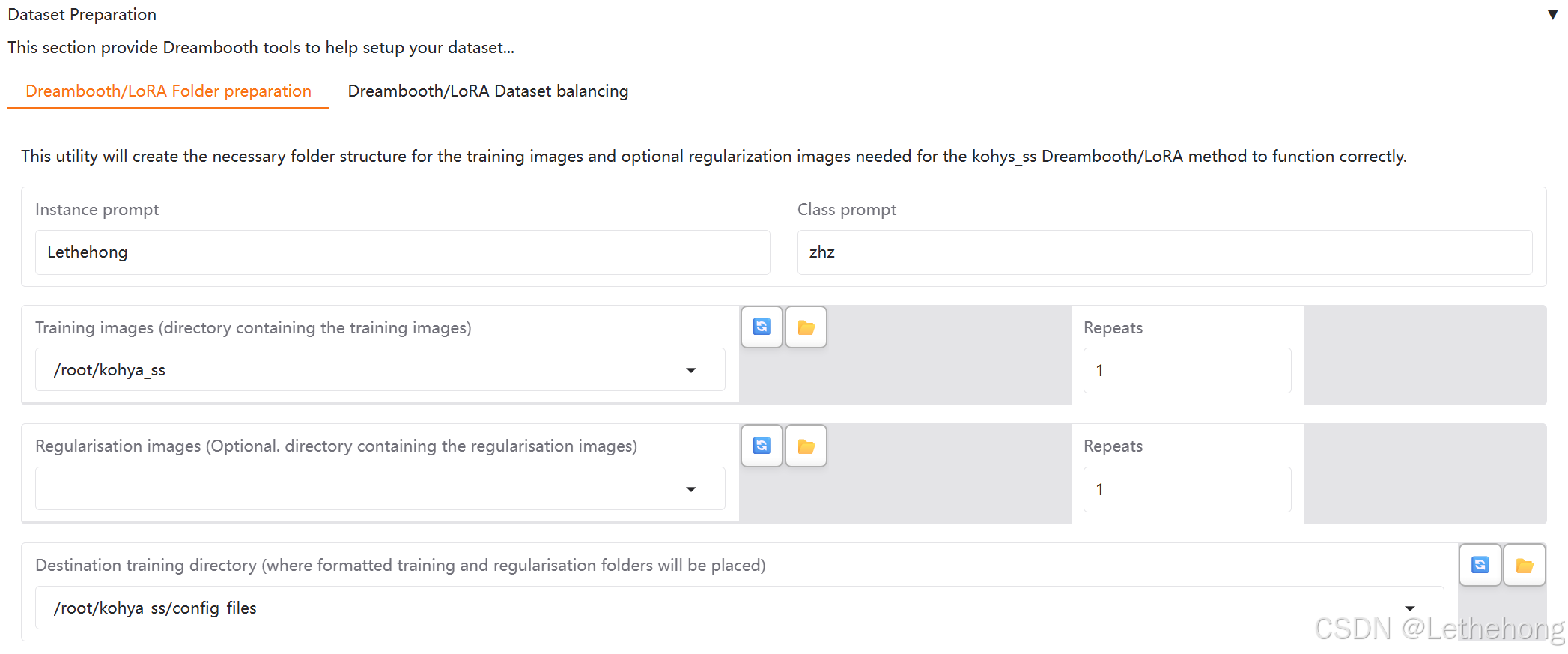
- Dataset Preparation→Instance prompt:实例级别的提示词;
- Dataset Preparation→Class prompt:类别提示词;
- Dataset Preparation→Training images (directory containing the training images):原始训练图像路径(后续将生成新路径并填入下方 Model→Image folder 中);
- Dataset Preparation→Repeats:每张图像的重复训练次数。
这是在JupyterLab训练的结果
结果
赛博科技——kohya_ss
云端算力推荐一家价格便宜 ,稳定的平台。算力自由,4090卡时 1.38元
kohya_ss 总结
这篇文章主要介绍了 kohya_ss —— 一个专门用于 Stable Diffusion LoRA 微调训练 的工具,重点讲了本地部署和蓝耘智算平台的云端一键使用方案。
工具概览
kohya_ss 是一个专门用于Stable Diffusion 模型微调的工具,核心功能是基于LoRA(低秩适应) 方法进行训练。它提供了图形化界面 (GUI),大幅降低了新手的使用门槛。整体上,它具有以下特点:
- 轻量化:LoRA 插入少量参数层,不会修改原始模型,节省显存和存储空间。
- 跨平台:支持 Windows、Linux、MacOS。
- 简单流程:数据准备 → 参数设置 → 启动训练。
本地安装 vs 云端使用
本地安装(Windows)
- 主要步骤包括:拉取仓库、配置虚拟环境、安装依赖、运行 setup.bat 并手动设置加速。
- 训练时需注意:
混合精度建议 bf16;
注意力模式改为 sdpa;
避免使用 8bit 优化器(会导致显存暴增)。 - 优点:完全本地可控,适合长期学习和自定义环境。
- 缺点:依赖硬件配置(显卡显存不足可能失败)。
云端使用(蓝耘风吟 kohya_ss-v2)
- 提供现成的 Web 界面,用户只需注册、选择 GPU,即可一键开启训练。
- 优点:免去环境配置,快速上手,适合临时或高算力需求场景。
- 缺点:长期使用成本较高,需依赖平台算力服务。
Stable Diffusion 微调方法对比
| 方法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Textual Inversion | 学习额外 embedding,不改原模型 | 占用小,加载快 | 难以学会模型未见过的内容 | 定制 prompt 词汇 |
| Dreambooth | 微调整个模型参数 | 效果强大,可生成全新风格 | 显存需求高(16G+),耗时长 | 全面风格迁移 |
| LoRA | 插入轻量层参数 | 训练快,文件小,推理方便 | 效果依赖基础模型 | 主流方案,性价比最高 |
| Hypernetworks | 独立网络插入中间层 | 理论灵活 | 官方支持少,使用较少 | 研究或尝试性应用 |
LoRA 训练的关键参数
模型相关:
- 预训练模型路径 (SD1.5/SDXL 等)
- 输出模型名称
- 输出目录、日志路径
数据集相关:
- 训练图像目录
- Instance prompt(实例提示词)
- Class prompt(类别提示词)
- Repeats(每张图的重复次数)
总结
整体来看,LoRA 是当前主流的 Stable Diffusion 微调方法,兼顾训练效率和实际效果。
- 如果你有合适显卡:本地搭建 kohya_ss 环境,长期使用更灵活。
- 如果你缺少算力或怕麻烦:蓝耘等云平台的风吟 kohya_ss-v2提供一站式训练,节省环境配置时间。
数据集相关:
- 训练图像目录
- Instance prompt(实例提示词)
- Class prompt(类别提示词)
- Repeats(每张图的重复次数)
换句话说:本地适合深度玩家,云端适合快速上手。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!



















 2884
2884



 到【灌水乐园】发言
到【灌水乐园】发言










