



本文全面解析大模型技术栈,涵盖Agents、提示词、LLM、AIGC、RAG、多模态等核心技术,详细解释原理与应用场景,提供从基础到商业部署的完整学习路径,帮助小白和程序员系统掌握大模型开发知识。
1、Agents
智能体是什么?
Agent 是什么,直译过来就是代理,但在国内人工智能领域通常被译为智能体。从智能体这个名字可以大概想象出这个 Agents 可能与智能相关,此概念出现已经有相当长时间了。随着大模型的爆发现在 Agents 的驱动核心为大模型,似乎智能体(Agents)时代真要来临了。
大模型大大降低了智能体实现的门槛,但如何用好智能体似乎各方都还在摸索中。目前智能体的应用中使用最广泛最多的应该还是在编程领域代码助手比较火爆,如 Cursor 等都是 AI 智能体。
现在大模型主要有本文大模型、多模态大模型,可生成文字、逻辑推理、编写代码、生成图片视频等等能力。光有这些模型基础能力还不能够被称为智能体,智能体:顾名思义是一系列能力的集合体。在不同环境中其智能体的能力也不一样,智能体=大模型+工具集。
在除了大模型的生成能力、逻辑推理能力、再加上其函数(工具)调用的能力呢,似乎已经看到了智能体的雏形。
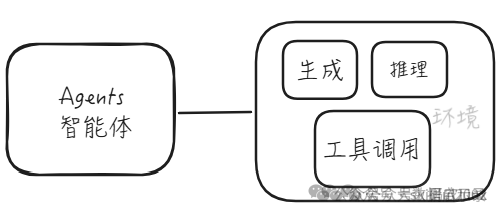
智能体 = 推理 + 生成 + 工具调用
智能体的两种模式
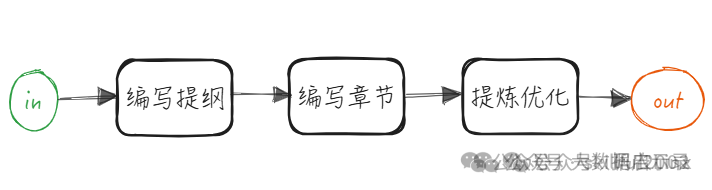
串行 Workflow 模式: 初级智能体,此模式下智能体只能执行某些经过编排好的能力实现固定功能。
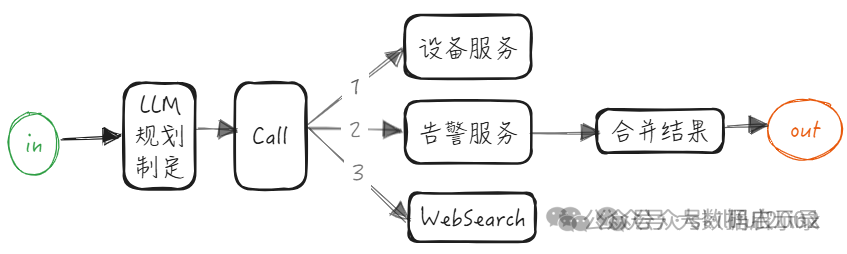
智能规划模式: 高级智能体,完全由智能体规划任务,决定任务如何执行,是调用两个服务还是调用三个服务取决于任务还有规划的制定。
已经有了高级智能体为什么还要去实现初级智能体,因为目前模型的意图识别、推理、规划能力还达不到指哪打哪 100%可靠的程度,这时候智能度越高越复杂的智能体可能也意味着出错的概率越大。所以使用简单又能够满足业务需求的初级智能体或许是更好的选择。
目前好用的 Agent 平台是 Coze、Dify、MarsCode、FastGPT、AutoGpt…
2、Prompt
Prompt 是什么?
即:提示词。Prompt 是给予提供语言模型(LLM)的输入或查询,作为模型生成后续文本的起点或上下文,它指示模型应生成何种类型的响应或输出。 它可以是一个问题、一个指令、一个句子片段、一个故事的开头,或者任何形式的文本输入。模型会基于 Prompt 的内容和自身的预训练知识,生成与之相关的、连贯的、符合预期的文本输出。 Prompt 是一种通过设计特定的提示词或句子,引导模型生成更符合用户意图的输出的方法。例如,我们可以为模型添加一些关于期望回答的提示信息,以帮助模型更好地理解问答的结构和规则。
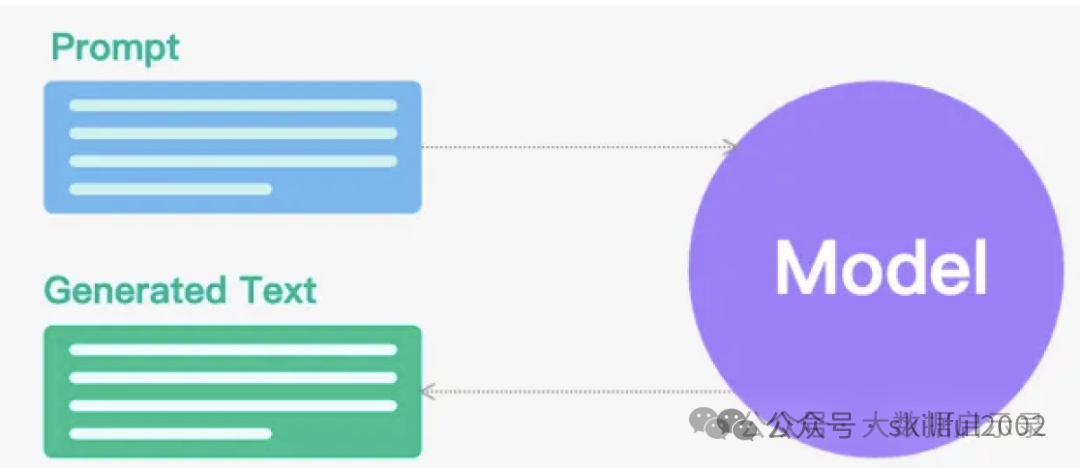
Prompt 的组成包四个元素:
- Instruction(指令,必需):告诉模型该怎么做,如何使用外部信息(如果提供),如何处理查询并构建 Out。
- Context(上下文信息,可选):充当模型的附加知识来源。这些可以手动插入到提示中,通过矢量数据库 (Vector Database) 检索(检索增强)获得,或通过其他方式(API、计算等)引入。
- Input Data(需要处理的数据,可选):通常(但不总是)是由人类用户(即提示者)In 到系统中的查询。
- Output Indicator(要输出的类型或格式,可选):标记要生成的文本的开头。

Prompt 编写原则
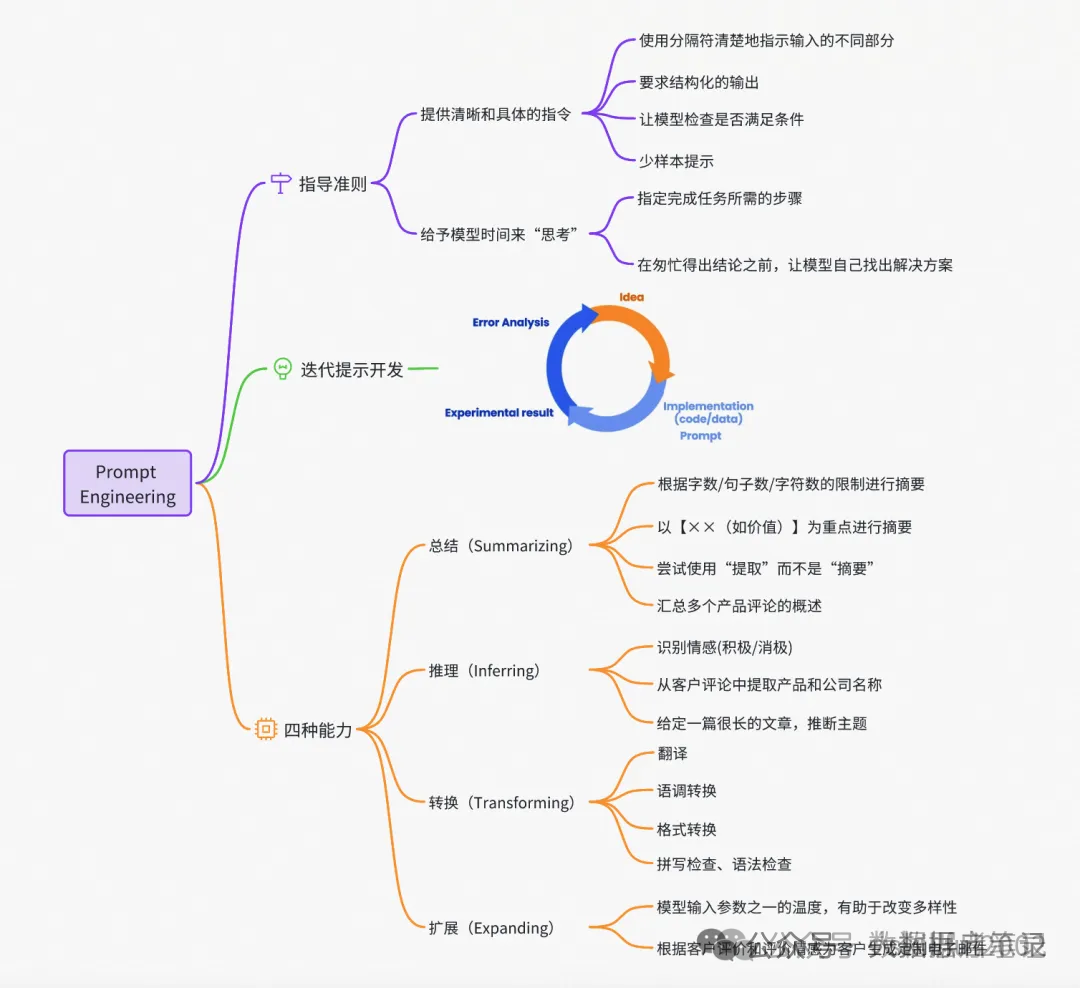
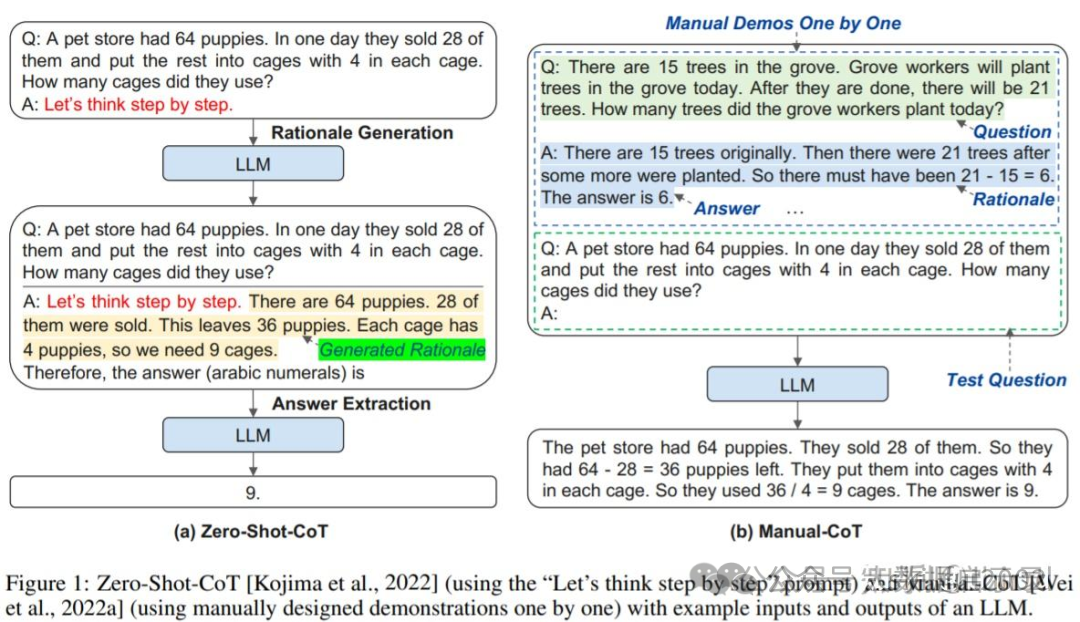
什么是 COT (Chain of Thought,CoT)?
一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。一般而言指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
以是否包含示例为区分,可以将 CoT 分为 Zero-Shot-CoT 与 Few-Shot-CoT,在上图中,Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。而 Few-Shot-Cot 则在示例中详细描述了“解题步骤”,让模型照猫画虎得到推理能力。 思维链的关键为,对于同类型的问题,提供推理过程示例以引发大模型的深度思考,从而参考示例实现推理。
COT 的关键在于示例的推理过程。思维链(CoT)提示通过中间推理步骤实现复杂的推理能力。你可以将它与少量提示结合起来,在需要推理才能做出反应的更复杂的任务中获得更好的结果。
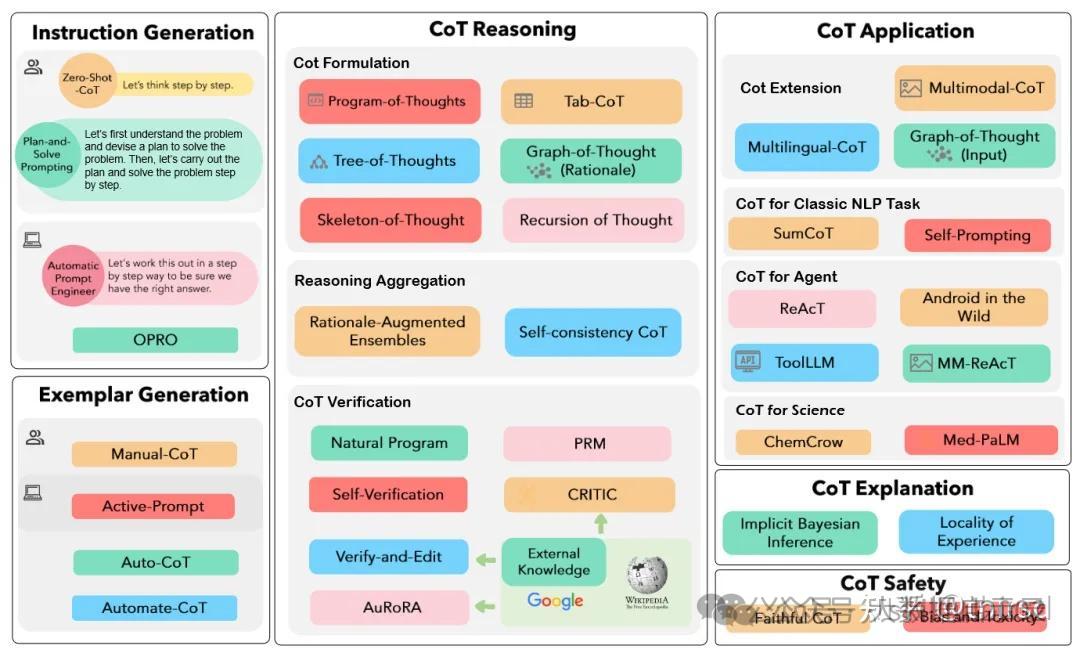
如果对使用 CoT 的好处做一个总结,那么可以归纳为以下四点:
- 增强了大模型的推理能力:CoT 通过将复杂问题分解为多步骤的子问题,相当显著的增强了大模型的推理能力,也最大限度的降低了大模型忽视求解问题的“关键细节”的现象,使得计算资源总是被分配于求解问题的“核心步骤”;
- 增强了大模型的可解释性:对比向大模型输入一个问题大模型为我们仅仅输出一个答案,CoT 使得大模型通过向我们展示“做题过程”,使得我们可以更好的判断大模型在求解当前问题上究竟是如何工作的,同时“做题步骤”的输出,也为我们定位其中错误步骤提供了依据;
- 增强了大模型的可控性:通过让大模型一步一步输出步骤,我们通过这些步骤的呈现可以对大模型问题求解的过程施加更大的影响,避免大模型成
- 增强了大模型的灵活性:仅仅添加一句“Let’s think step by step”,就可以在现有的各种不同的大模型中使用 CoT 方法,同时,CoT 赋予的大模型一步一步思考的能力不仅仅局限于“语言智能”,在科学应用,以及 AI Agent 的构建之中都有用武之地。 高级的 Prompt 技术,主要有 零样本提示、少样本提示、链式思考(CoT)提示、链式提示、思维树 (ToT)、Active-Prompt。力。
Prompt 类型
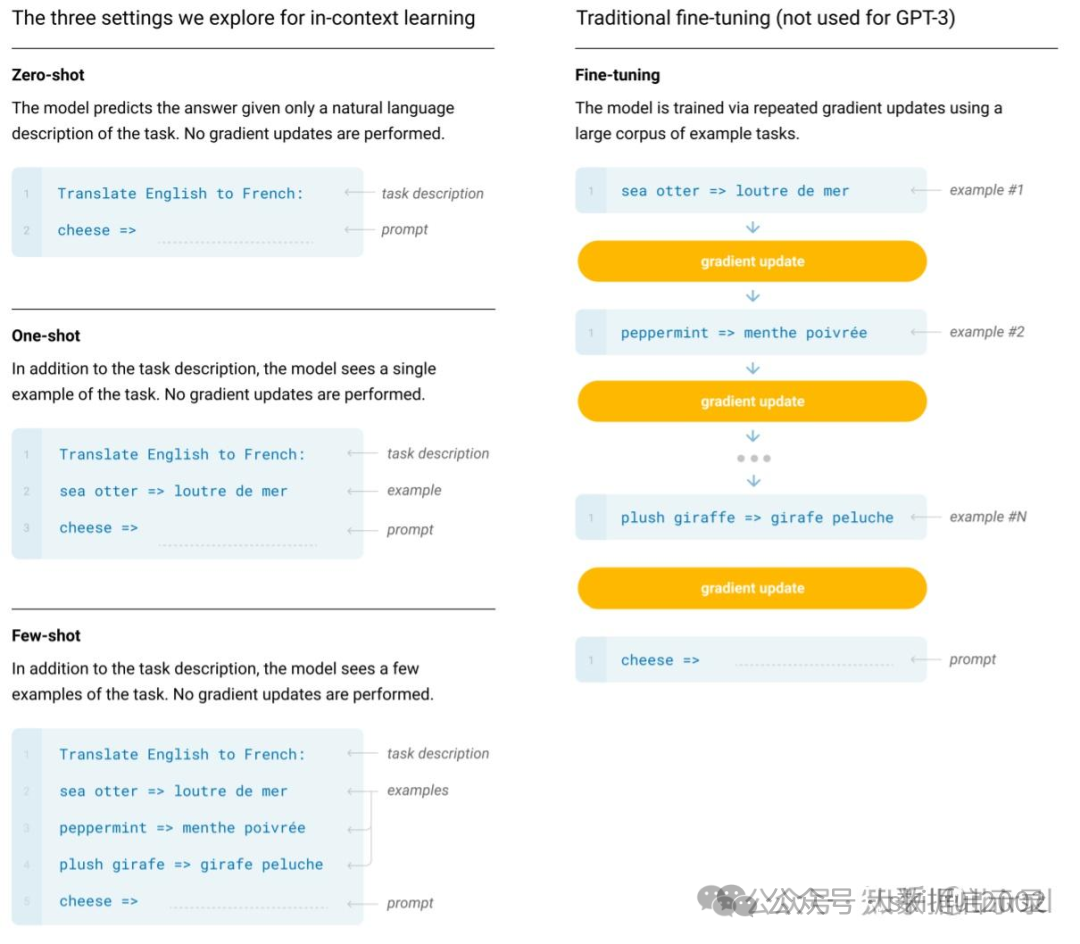
Zero-Shot Prompting
直接向模型提出问题,不需要任何案例,模型就能回答你的问题,基于模型训练的时候提供的大量数据,能做初步的判断。
(1) Zero-Shot Prompting 技术依赖于预训练的语言模型。
(2) 为了获得最佳性能,它需要大量的样本数据进行微调。像 ChatGPT 就是一个例子,它的样本数量是过千亿。
(3) 由于Zero-Shot Prompting 技术的灵活性和通用性,它的输出有时可能不够准确,或不符合预期。这可能需要对模型进行进一步的微调或添加更多的提示文本来纠正。
least-To-Most COT(LtM 提示法)
整个提示过程会分为两个阶段进行,第一个阶段是自上而下的分解问题(Decompose Question into subquestion),第二个阶段是自下而上的依次解决问题(Sequentially Solve Subquestion),而整个依次回答问题的过程,其实就可以看成是 CoT 的过程,只不过 LtM 会要求模型根据每个不同的问题,单独生成解决问题的链路,以此做到解决问题流程的“千人千面”,从而能够更加精准的解决复杂推理问题。而整个过程问题的由少变多,则是 LEAST-TO-MOST 一词的来源。
LtM 提示方法提出的初衷是为了解决 CoT 提示方法泛化能力不足的问题——即通过人工编写的思维链提示样本可能并不能够很好的迁移到别的问题当中去,换而言之,就是解决问题的流程迁移能力不足,即泛化能力不够。而这种泛化能力不足则会导致“新的问题”无法使用“老的模板”进行解决。例如此前的第四个推理问题就是如此。那即然要找到更加普适的解决问题的流程会非常复杂,那能否“千人千面”让大模型自己找到解决当前问题的思维链呢?答案是肯定的,谷歌大脑基于这个思路开发了一种全新的提示流程,即先通过提示过程让模型找到解决该问题必须要分步解决哪几个问题,然后再通过依次解决这些问题来解决最原始的问题。
思维链(Chain of Thoughts, CoT)
Jason Wei 等人(2022)引入的思维链(CoT)提示,通过中间推理步骤实现复杂的推理能力。可以将其与少样本提示相结合,以获得更好的结果,以便在回答之前进行推理的更复杂的任务。

有两种方式增加 GPT 的推理能力,或者 CoT 能力:
(1) 第一种:增加案例,如下所示,第一次回答错误,给一个计算过程的案例,GPT 可以通过案例学会简单推理。
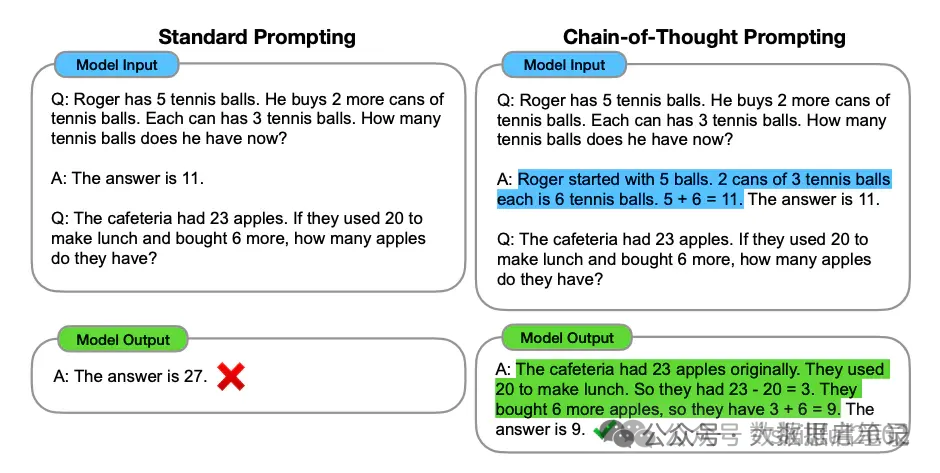
第二种:增加关键句,Let’s think step by step,测试人员测了很多类似的句子,最后发现这句话是效果最好的,这个时候不加案例,GPT 也具备一定的推理能力。

根据 Wei 等人的论文表明,它仅在大于等于 100B 参数的模型中使用才会有效。如果使用的是小样本模型,这个方法不会生效。
自洽性(Self-Consistency)
是对 CoT 的一个补充,让模型生成多个思维链,然后取最多数答案的作为最终结果。其实重复运算多次,取概率最高的那一个,需要借助脚本辅助完成这个功能。
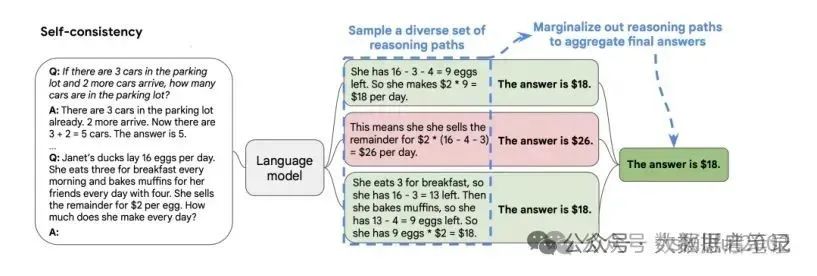
(1)从语言模型中生成多个不同的“推理路径(reasoning paths)”,这些路径可能因模型的随机性或不同的参数设置(如 temperature、top_p 等)而有所不同。有助于模型更全面地考虑问题,并可能导致更准确或更可靠的最终答案。
(2) 对上一步生成的多个推理路径进行“边缘化(marginalize out)”以得到一个最终的、一致的答案。边缘化在这里意味着从多个可能的推理路径中找出最常见或最一致的答案。
思维树(Tree-of-thought, ToT)
Tree of Thoughts(ToT)框架,用于改进语言模型(LMs)的推理能力。该框架是对流行的“Chain of Thought”方法的一种泛化,允许模型在解决问题的过程中进行更多的探索和策略性前瞻。ToT 允许模型自我评估不同的选择,以决定下一步的行动,并在必要时进行前瞻或回溯,以做出全局性的选择。
在 24 点游戏中,使用链式思考提示的 GPT-4 仅解决了 4%的任务,而使用 ToT 方法的成功率达到了 74%。
Automatic Prompt Engineer (APE)
APE 探索了一种比 zero-shot CoT prompt 人工设定的"Let’s think step by step" prompt 更优的指令,以使用 llm 生成和搜索候选解决方案的黑盒优化问题。对于不同的任务和模型,需要获取不同的指令语句。
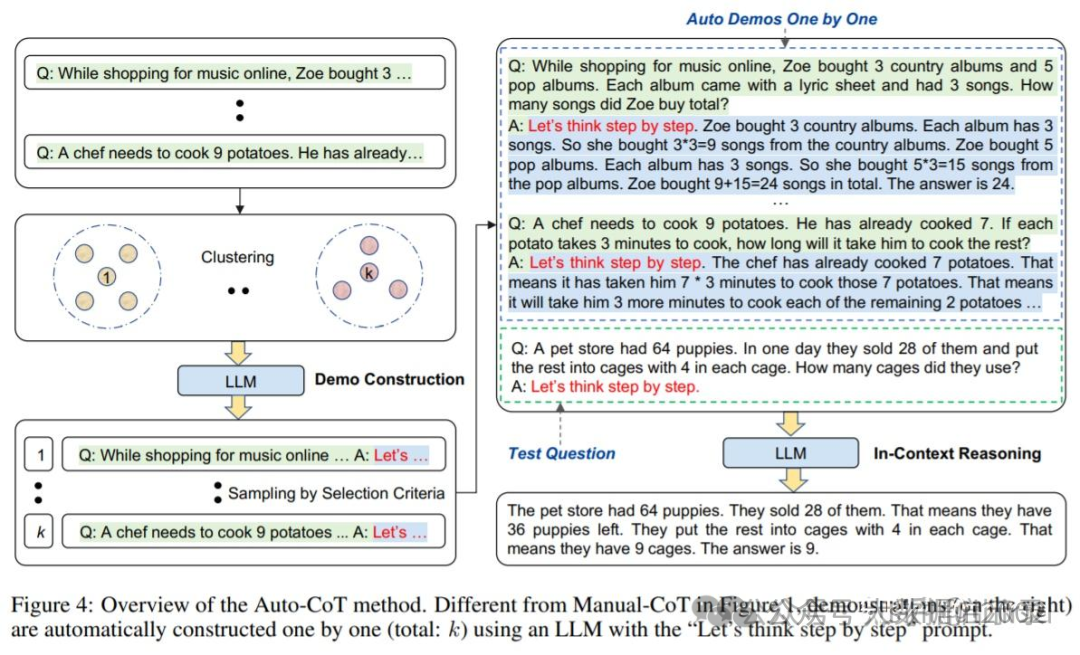
Automatic Chain-of-Thought (Auto-CoT)
当用应用思维链提示时,该过程涉及手工编写有效和多样化的示例。这种手工工作可能导致次优解决方案。Zhang 等人(2022)提出了一种方法,通过利用带有“让我们一步一步思考”提示的 LLM,为一个接一个的演示生成推理链,从而消除人工操作。这个自动过程仍然可能在生成的链中出现错误。为了减轻错误的影响,正面过程的多样性很重要。这项工作提出了 Auto-CoT,采样多样性的问题,并编写推理链。 Auto-CoT 包括两个主要阶段: 段 1:问采用::将给定数据集的问题划分为几个簇阶段):示范:样:从每个聚类中选择一个有代表性的问题,使用简单的来 oT 生成其推。
ReAct 框架
Yao 等人(2022)引入了一个框架,其中 LLMs 以交错的方式生成推理轨迹和任务特定操作,并且允许 LLMs 与外部工具交互来获取额外信息,从而给出更可靠和实际的回应。ReAct 的灵感来自于“行为”和“推理”之间的协同作用,正是这种协同作用使得人类能够学习新任务并做出决策或推理。下图展示 ReAct 的一个示例,举例执行问题回答所涉及的不同步骤。

实现流程如下:(1)用 Prompt 实现一个样例,比如上面的模板:Thought:xxx ==> Action: Search[xxx];(2)LLMs 会根据模板相同的逻辑,结合 CoT 思维链方式一步一步思考,并获取外部知识;(3)最后 Action: Finish 获取最终结果后结束。
3、LLM
概述:
LLM 是 Large Language Model 这三个单词的首字母缩写,意为大语言模型。大型语言模型(LLM)是一种基于深度学习技术的自然语言处理工具,能理解和生成文本。通过大量语料库训练,LLM 在翻译、写作、对话等任务中展现出卓越的能力。常见的应用包括自动问答、生成文本、文本摘要等。由于其多模态特性,LLM 还可用于图像和音频处理,为多领域带来创新可能。GPT、LLaMA、Mistral、BERT 等都是 LLM,LLM 是对训练文本信息的压缩,同时拥有了泛化能力,不同于数据库和搜索引擎,LLM 能创造性地生成历史上没有出现过的文本内容。
GPT(Generative Pretrained Transformer)和 BERT(Bidirectional Encoder Representations from Transformers)这两个词中的 T 就是 Transformer 架构。Transformer 架构是一种基于自注意力机制的神经网络结构,它完全颠覆了之前以循环神经网络(RNN)为主导的序列建模范式。Transformer 架构的出现,实现了并行计算和高效的上下文捕获,极大地提高了自然语言处理的性能。可以说,先有 Transformer,后有 GPT 以及 BERT。 常见模型中的 7B,14B,32B…等参数 B 是 Billion 的缩写,指的是模型训练的参数数量。
BERT 模型和 GPT 模型的区别
BERT:双向 预训练语言模型+fine-tuning(微调)
GPT:自回归 预训练语言模型+Prompting(指示/提示)
BERT 和 GPT 两者都是基于大语言模型的,他们在这一点上是相同的。他们的不同在于双向/自回归,fine-tuning/Prompting 这两个维度
架构:GPT 是单向生成模型,使用自回归架构;BERT 是双向编码模型,使用编码器架构。
训练目标:GPT 目标是自回归语言建模,生成下一个单词;BERT 目标是掩码语言建模,预测被掩码的单词。
应用场景:GPT 主要用于生成任务,如文本生成、对话系统;BERT 主要用于分类任务,如文本分类、命名实体识别。
训练数据:两者都使用大规模文本数据,但 GPT 只需要单向数据流,BERT 需要双向数据流。
模型大小:GPT 通常具有更大的参数量,BERT 相对较小。
训练方法:GPT 通过自回归训练,BERT 通过掩码训练。
性能和效率:GPT 在生成任务上表现优异,推理速度较慢;BERT 在分类任务上表现优异,推理速度较快。
扩展性:两者都可以通过微调进行多任务学习,但 GPT 在生成任务上更具优势。
常见的LLM产品:

- ChatGPT:网页版;非国区应用商店可下载APP;
- Poe:网页版;非国区应用商店可下载APP;
- Coze:国际版;国内版
- Gemini:个人版;开发者版,100万上下文
- Arc Search:官网下载客户端;非国区应用商店可下载APP
- Perplexity:网页版;非国区应用商店可下载APP;
- 通义:网页版;各大应用商店可下载APP;
- 秘塔:网页版
- Kimi:网页版;各大应用商店可下载APP;
- 文心一言:网页版;各大应用商店可下载APP;
- 海螺AI:网页版;各大应用商店可下载APP;
- 智谱清言:网页版;各大应用商店可下载APP;
- 豆包:网页版;各大应用商店可下载APP;
- Microsoft Copilot:网页版;非国区应用商店可下载APP;
- HuggingChat:网页版;非国区应用商店可下载APP;
- 讯飞星火:网页版;各大应用商店可下载APP;
- 百小应:网页版;各大应用商店可下载APP;
- DeepSeek:网页版;各大应用商店可下载APP;
LLM模型评测
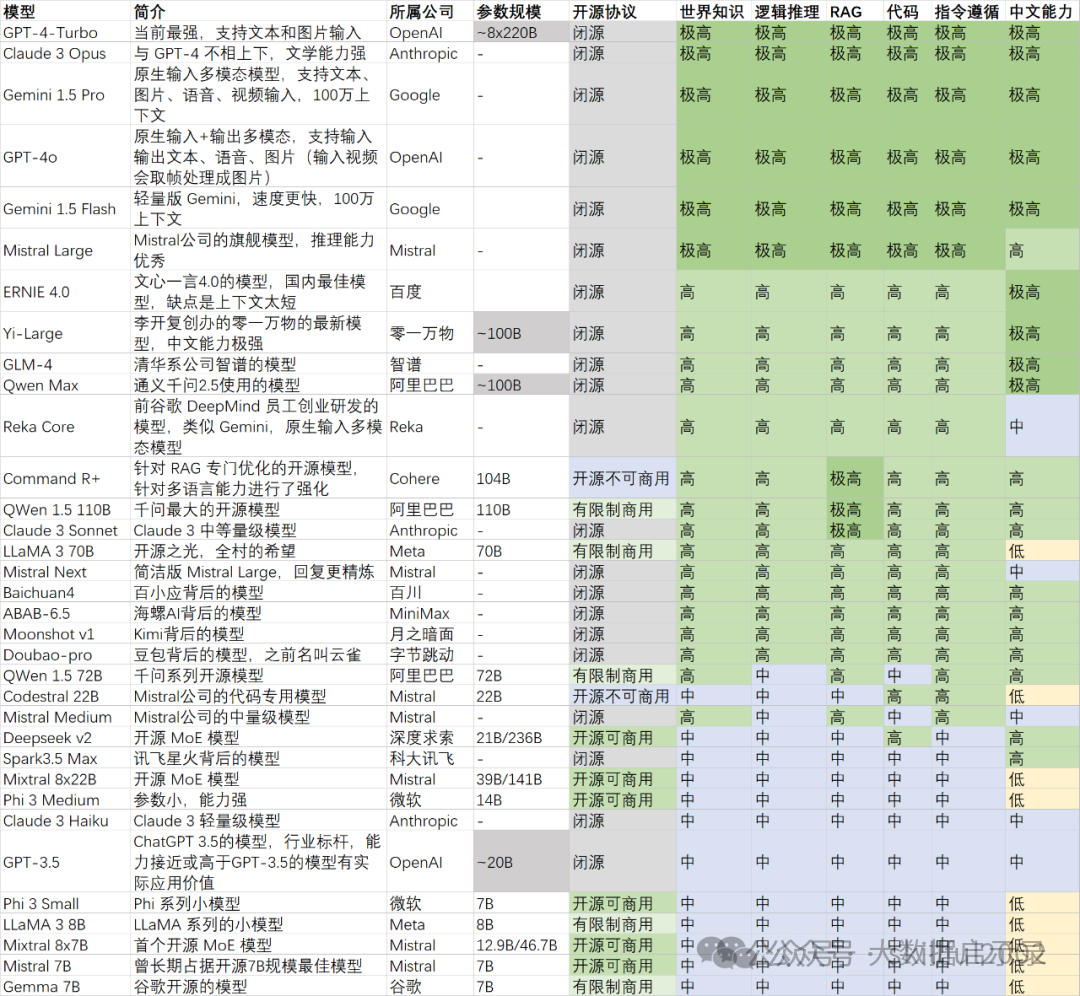
LLM与生成式AI的区别
LLM 编程框架

4、AIGC
概述:
AIGC,即人工智能生成内容(Artificial Intelligence Generated Content),是一种利用人工智能算法和技术自动生成各种形式的内容的技术。这些内容包括文本、图像、音频、视频等。AIGC 又称生成式 AI ,它被认为是继专业生成内容和用户生成内容之后的新型内容创作方式。
与传统 AI 不同,传统 AI 可以用来完成排序、分类、图像识别等任务。
而 AIGC 则专注于内容创作,AIGC 专注于使用 AI 创建新的、原创的内容,可以生成文字、图像、音乐、视频等多种形式的内容,它不仅能提高内容创作的效率,还能在广告营销、教育、娱乐等领域带来革命性的变化。AIGC代表了人工智能技术在内容生成领域的最新进展,具有重要的应用价值和发展前景。
原理说明:
AIGC 的核心原理主要依托于机器学习领域,其中尤以深度学习以及生成对抗网络(GAN)为主。通俗来讲,GAN 凭借两个处于对立态势的神经网络,即生成器和判别器,二者相互博弈,持续不断地提升所生成内容的质量水准。至于变换器( Transformer ),其借助自注意力机制,具备理解上下文关联的能力,进而能够生成逻辑连贯的文本或者其他类型的内容。
核心原理与效果技术:
1:基于生成式对抗网络(GAN)—核心思想是在通过两个神经网络——生成器(Generator)和判别器(Discriminator)的相互对抗来生成高质量的数据实例。
2:基于自编码器(Autoencoder)—编码器负责将输入数据压缩成一个低维度的隐藏空间表示,而解码器则将这个隐藏空间表示还原回输入数据的形式。
3:基于递归神经网络(RNN)—其核心思想是通过在输入序列中循环应用相同的网络结构来处理每个输入,并保留先前输入的信息,以便在处理当前输入时可以参考和使用。
4:基于变换器(Transformer)—Transformer架构的核心是自注意力机制,这种机制允许模型在序列内的任意位置间直接进行交互,从而捕捉长距离依赖关系。与传统的递归神经网络(RNN)不同,Transformer完全基于注意力机制,不使用任何循环层或卷积层,这使得其能够并行化计算,显著提高训练速度。
5:多模态生成—多模态生成技术是一种通过将多种类型的数据(如文本、图像和音频)相互映射和融合的技术,旨在生成包含多模态元素的内容。其核心在于学习不同模态数据的统一表征,提取互补信息以促进合成任务的完成。这种技术的核心在于能够将不同模态的数据进行交互和组合,从而创造出新的内容。
AIGC产品:
- 文本生成:OpenAI GPT系列、Google BERT系列、Anthropic Claude、Alibaba Qwen、Microsoft Copilot。
- 图像生成:DALL-E、Midjourney、Stable Diffusion、DeepArt、RunwayML。
- 音频生成:Jukebox、WaveNet、MusicGen、Amper Music、Descript。
- 视频生成:DeepMind VideoGen、RunwayML Video、Daz 3D、Synthesia、Adobe After Effects with AI Plugins,Sora,runway。
- 其他应用:Adobe Firefly、Notion AI、GitHub Copilot、Replit AI、Grammarly。
5、RAG
概念:
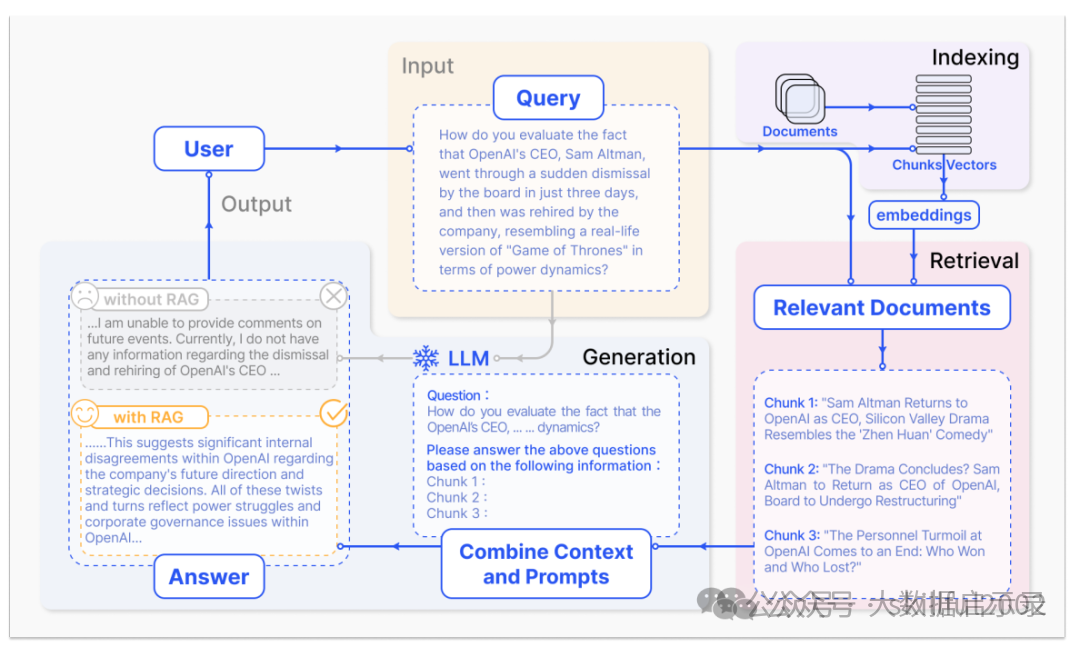
RAG(Retrieval Augmented Generation)检索增强生成,即大模型LLM在回答问题或生成文本时,会先从大量的文档中检索出相关信息,然后基于这些检索出的信息进行回答或生成文本,从而可以提高回答的质量,而不是任由LLM来发挥。RAG技术使得开发者没有必要为每个特定的任务重新训练整个大模型,只需要外挂上相关知识库就可以,即可为模型提供额外的信息输入,提高回答的准确性。RAG技术工作流程如下图所示。
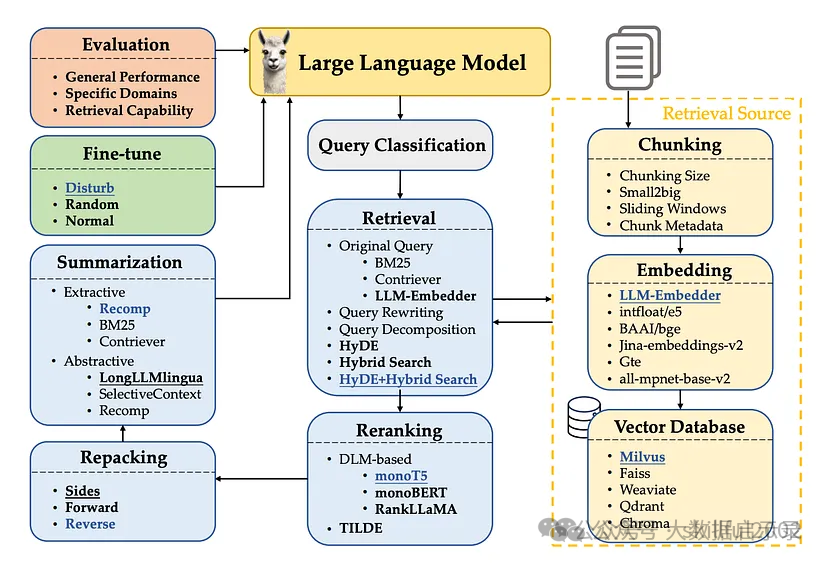
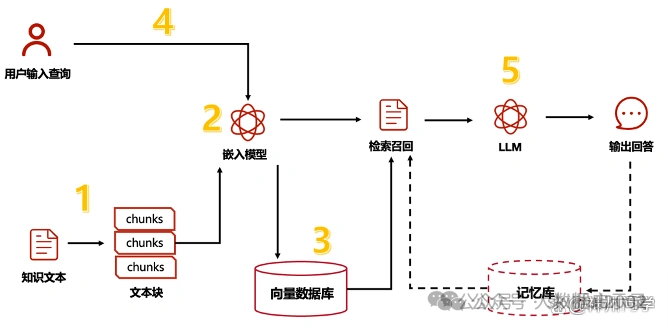
大致流程:
1:知识文本切块处理成文件块。
2: 文件块嵌入模型,创建索引。
3: 存入向量数据库。
4: 用户问题请求查询向量数据库
5: 检索和召回,并自动排序。
6: LLM 训练模型进行归纳
7: 返回响应结果,输出回答。
8:回答记录存入记忆库,检索和召回。
检索: 当接收到用户查询时,使用检索索引找到最相关的文档。具体来讲,对用户输入的查询信息Embedding转化为向量,再到向量数据库中检索其他匹配的上下文信息。通过这种相似性搜索,可以找到向量数据库中最匹配的相关数据。
增强: 将向量数据库中检索到的信息与用户查询信息放到我们自定义的提示模板中。
生成: 最后将上面经过检索以及增强后的提示内容输入到LLM中,LLM根据上述信息生成最终结果。
RAG能解决LLM的哪些问题
即使在LLM有较强的解决问题的能力,仍然需要RAG技术的配合,因为能够帮助解决LLM存在的以下几个问题。
(1)模型幻觉问题:LLM文本生成的底层原理是基于概率进行生成的,在没有已知事实作为支撑的情况下,不可避免的会出现一本正经的胡说八道的情况。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
(2)知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
(3)数据安全问题:开源的大模型是没有企业内部数据和用户数据的,如果企业想在保证数据安全的前提下使用LLM,一种比较好的解决办法就是把数据放在本地,企业数据的业务计算全部放在本地完成。而在线的LLM只是完成一个归纳总结的作用。
RAG架构
RAG的架构如图中所示,简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
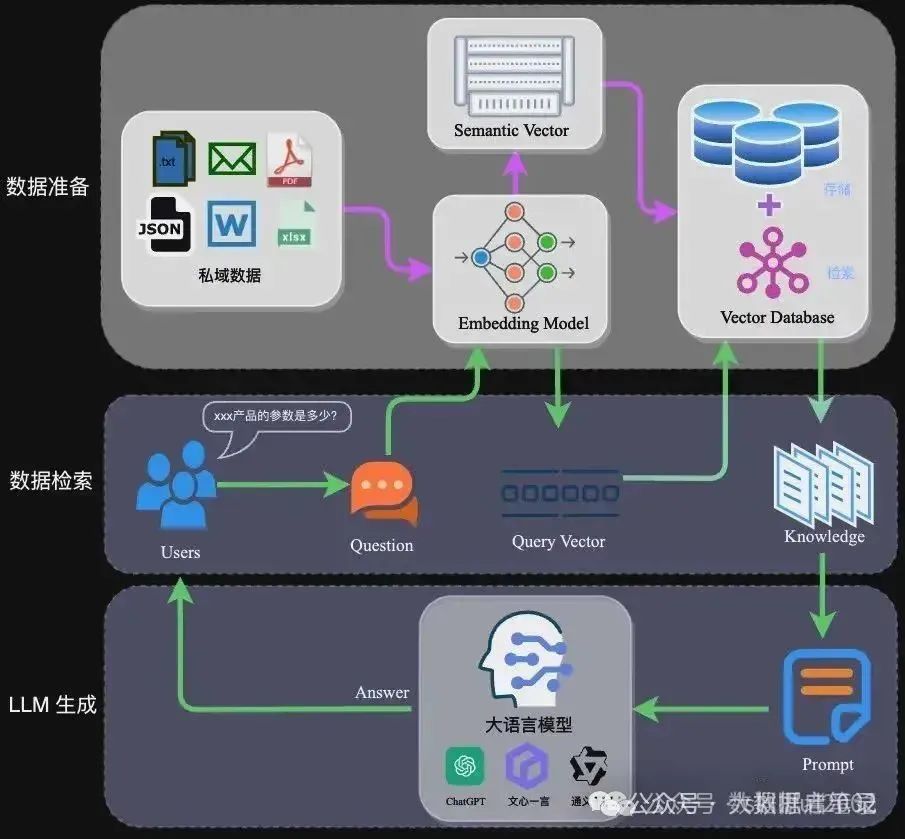
完整的RAG应用流程主要包含两个阶段:
(1)数据准备阶段:数据提取–>文本分割–>向量化(embedding)–>数据入库;
(2)应用阶段:用户提问–>数据检索(检索)–>注入Prompt(增强)–>LLM生成答案(生成)。
下面我们详细介绍一下各环节的技术细节和注意事项:
1 数据准备阶段
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
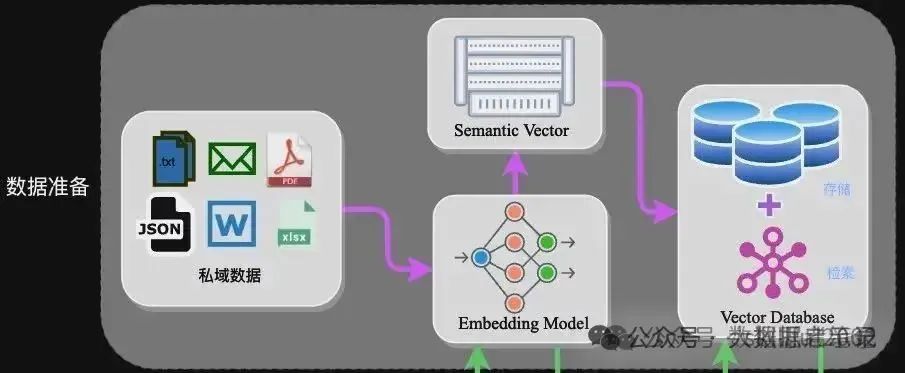
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
- 元数据获取:提取数据中关键信息,例如文件名、Title、时间等。
文本分割主要考虑两个因素:
(1) embedding模型的Tokens限制情况;
(2) 语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下:
- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的Embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、Milvus、ES等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
2 应用阶段
在应用阶段,我们根据用户的提问,通过高效的检索方法,召回与提问最相关的知识,并融入Prompt;大模型参考当前提问和相关知识,生成相应的答案。关键环节包括:数据检索、注入Prompt等。
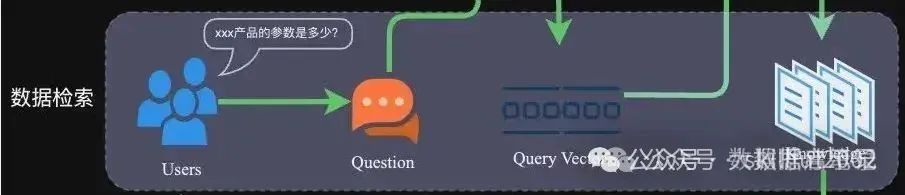
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。o 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。o 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录,比如ES。
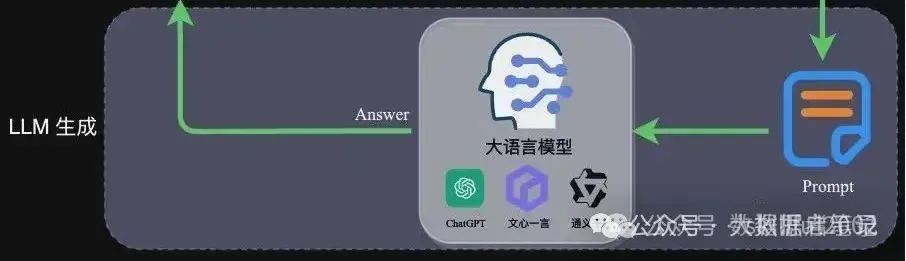
Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。
在这个阶段,我们将经过检索增强的提示内容输入到大语言模型(LLM)中,以生成所需的输出。这个过程是RAG的核心,它利用LLM的强大生成能力,结合前两个阶段的信息,从而生成准确、丰富且与上下文相关的输出。
常见的RAG开源框架
Haystack
Haystack 是一个强大而灵活的框架,用于构建端到端问题解答和搜索系统。它采用模块化架构,允许开发人员轻松创建各种 NLP 任务的管道,包括文档检索、问题解答和摘要:
- 支持多种文档存储(Elasticsearch、FAISS、SQL 等)
- 与流行的语言模型(BERT、RoBERTa、DPR 等)集成
- 处理大量文件的可扩展架构
- 易于使用的 API,可用于构建自定义 NLP 管道
https://github.com/deepset-ai/haystack
RAGFlow
RAGFlow 是 RAG 框架领域中一个相对较新的加入者,但由于其注重简洁性和效率,很快就获得了人们的青睐。该框架旨在通过提供一套预建组件和工作流来简化基于 RAG 的应用程序的构建过程:
- 直观的工作流设计界面
- 针对常见用例的预配置 RAG 管道
- 与流行的矢量数据库集成
- 支持自定义嵌入模型
RAGFlow 的用户友好型方法使其成为开发人员的一个极具吸引力的选择,这些开发人员希望快速创建和部署 RAG 应用程序原型,而无需深入研究底层的复杂性。
Txtai
txtai 是一个多功能的人工智能数据平台,它超越了传统的 RAG 框架。它为构建语义搜索、语言模型工作流和文档处理管道提供了一套全面的工具:
- 嵌入式数据库,用于高效的相似性搜索
- 用于集成语言模型和其他人工智能服务的 API
- 用于自定义工作流的可扩展架构
- 支持多种语言和数据类型
txtai 的一体化方法使其成为那些希望在单一框架内实现各种人工智能功能的企业的绝佳选择。
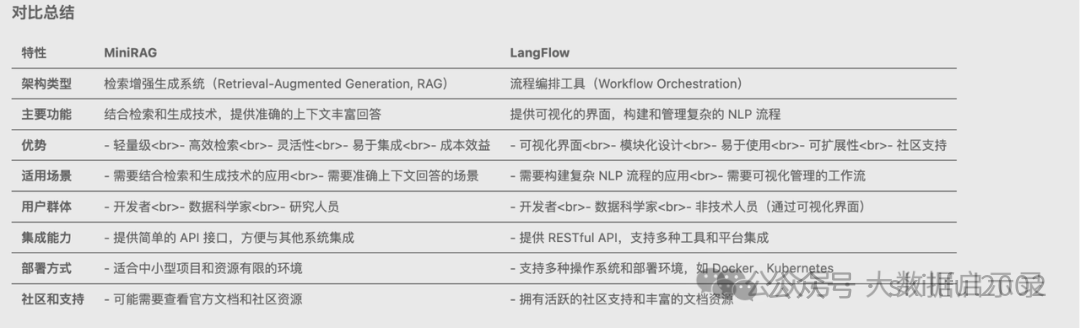
MiniRAG
- 轻量级:
- 设计简洁,易于部署和使用,适合中小型项目和资源有限的环境。
- 高效检索:
- 使用高效的检索算法和数据结构,快速从大规模文档库中检索相关信息。
- 灵活性:
- 支持多种检索和生成模型,可以根据需求进行灵活配置。
- 易于集成:
- 提供简单的 API 接口,方便与其他系统和工具集成。
- 成本效益:
- 相比大型 RAG 系统,MiniRAG 的资源消耗较低,成本更低。
langflow
- 可视化界面:
- 提供直观的拖放界面,用户无需编写代码即可构建复杂的 NLP 流程。
- 模块化设计:
- 支持多种 NLP 组件(如文本生成、文本分类、实体识别、情感分析等),可以灵活组合。
- 易于使用:
- 即使没有编程背景的用户也可以轻松构建和管理 NLP 流程。
- 可扩展性:
- 支持自定义组件和插件,可以根据需求扩展功能,提供 RESTful API,方便与其他系统集成。。
- 社区支持:
- 开源项目,拥有活跃的社区支持和丰富的文档资源。
- 集成能力:
- 可以与多种工具和平台集成,如 OpenAI API、Hugging Face Transformers 等。
6、多模态
什么是多模态?
多模态是从多个模态表达或感知事物。多个模态也可归类为同质性的模态,例如从两台相机中分别拍摄的图片,异质性的模态,即图片与文本语言的关系。目前研究领域中主要是对图像,文本,语音三种模态的处理。之所以要对模态进行融合,是因为不同模态的表现方式不一样,看待事物的角度也会不一样,所以存在一些交叉(所以存在信息冗余),互补(所以比单特征更优秀)的现象,甚至模态间可能还存在多种不同的信息交互,如果能合理的处理多模态信息,就能得到丰富特征信息。即概括来说多模态的显著特点是:余度性 和 互补性 。 多模态融合重点关注深度学习模型中融合特征的阶段,无论是数据级、特征级还是建议级。
一句话总结:就是融合了多种不同类型的信息,比如图像、文本、音频和视频等。目前最常见的是Vision+Language的结合形式。
几种常见的多模态任务
多模态任务指的是涉及到多种模态(如视觉、语音、文本等)数据的任务。以下是一些常见的多模态任务:
图像分类和描述:给定一张图片,需要将其分类到不同的类别,并且根据图片生成相应的文字描述。
视频分析:对于一段视频,需要进行各种分析,如人物跟踪、动作识别、情感分析等。
语音识别和生成:将语音转化为文字,或者根据给定的文本生成相应的语音。
视觉问答:基于对图像的理解,回答与之相关的问题。
多模态机器翻译:将不同模态的输入翻译成目标语言的输出,如将一段视频中的语音和图像翻译成另一种语言的文字和图像。
多模态情感识别:利用图像、文本、语音等不同的模态数据来识别人的情感状态,如快乐、悲伤、愤怒等。 需要注意的是,
多模态任务的范围很广,上述只是其中的一部分,实际应用还有很多其他的多模态任务。
多模态大型语言模型
多模态大型语言模型(Multimodal Large Language Models,简称MLLMs)是一类结合了大型语言模型(Large Language Models,简称LLMs)的自然语言处理能力与对其他模态(如视觉、音频等)数据的理解与生成能力的模型。这些模型通过整合文本、图像、声音等多种类型的输入和输出,提供更加丰富和自然的交互体验。 MLLMs的核心优势在于它们能够处理和理解来自不同模态的信息,并将这些信息融合以完成复杂的任务。例如,MLLMs可以分析一张图片并生成描述性的文本,或者根据文本描述生成相应的图像。这种跨模态的理解和生成能力,使得MLLMs在多个领域,如自动驾驶、智能助理、内容推荐系统、教育和培训等,都有广泛的应用前景。
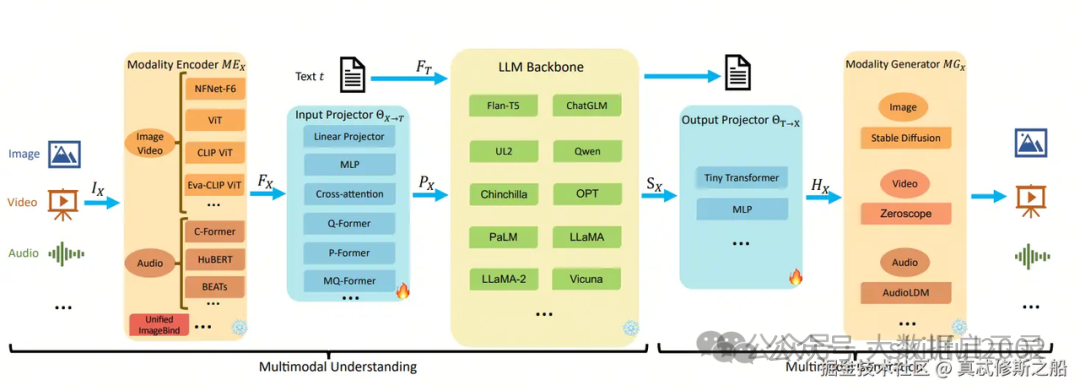
上图中,我们可以看到MLLMs的核心组成部分,包括:
扩展的方式是找到一个方法将不同模态的数据映射到LLMs可以接收的语义空间。接下来我们分别看看这几个组成部分的具体内容
多模态的分类
静态多模态大模型:这个主要是处理静态数据,比如图片和文本。
动态多模态大模型:涉及动态数据,比如视频和音频。
垂直领域多模态:针对特定领域的多模态应用。
多模态学习
多模态学习(Multimodal Learning)是一种利用来自不同感官或交互方式的数据进行学习的方法,这些数据模态可能包括文本、图像、音频、视频等。多模态学习通过融合多种数据模态来训练模型,从而提高模型的感知与理解能力,实现跨模态的信息交互与融合。
接下来分三部分:模态表示、多模态融合、跨模态对齐,一起来总结下多模型的核心:多模态学习
一:模态表示
什么是模态表示(Modal Representation)?
模态表示是将不同感官或交互方式的数据(如文本、图像、声音等)转换为计算机可理解和处理的形式,以便进行后续的计算、分析和融合。
- 文本模态的表示:文本模态的表示方法有多种,如独热表示、低维空间表示(如通过神经网络模型学习得到的转换矩阵将单词或字映射到语义空间中)、词袋表示及其衍生出的n-grams词袋表示等。目前,主流的文本表示方法是预训练文本模型,如BERT。
- 视觉模态的表示:视觉模态分为图像模态和视频模态。图像模态的表示主要通过卷积神经网络(CNN)实现,如LeNet-5、AlexNet、VGG、GoogLeNet、ResNet等。视频模态的表示则结合了图像的空间属性和时间属性,通常由CNN和循环神经网络(RNN)或长短时记忆网络(LSTM)等模型共同处理。
- 声音模态的表示:声音模态的表示通常涉及音频信号的预处理、特征提取和表示学习等步骤,常用的模型包括深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(RNN)等。
表征学习(Representation Learning)
旨在从原始数据中自动提取有效特征,形成计算机可理解的模态表示,以保留关键信息并促进跨模态交互与融合。 表征学习 表征学习(Representation Learning) ≈ 向量化(Embedding)
神经网络算法 - 一文搞懂Embedding(嵌入)
一文彻底搞懂Embedding - Word2Vec(Skip-Gram和CBOW)
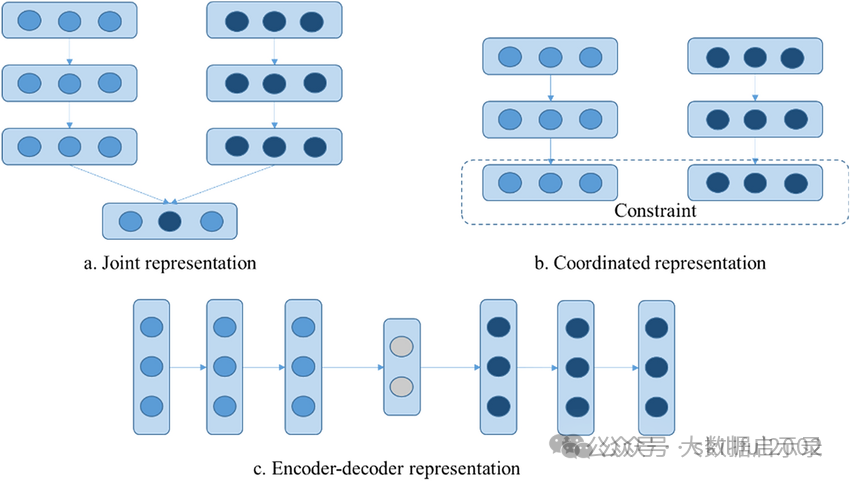
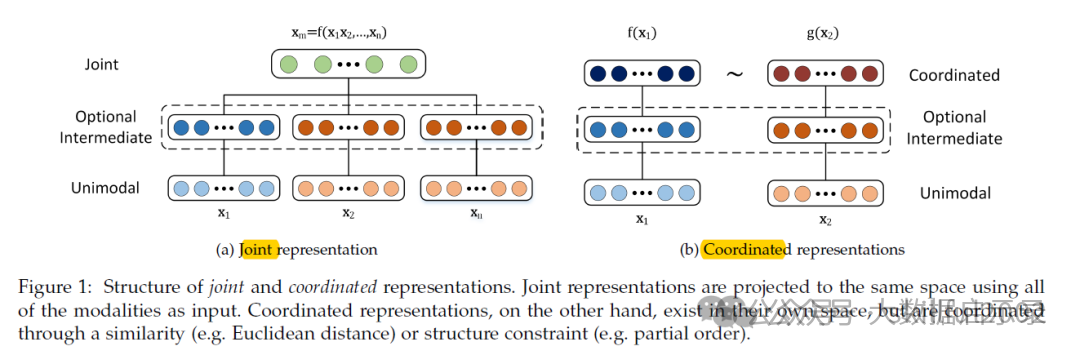
什么是多模态联合表示(Joint Representation)?
多模态联合表示是一种将多个模态(如文本、图像、声音等)的信息共同映射到一个统一的多模态向量空间中的表示方法。 多模态联合表示通过神经网络、概率图模型将来自不同模态的数据进行融合,生成一个包含多个模态信息的统一表示。这个表示不仅保留了每个模态的关键信息,还能够在不同模态之间建立联系,从而支持跨模态的任务,如多模态情感分析、视听语音识别等。
多模态表示
什么是多模态协同表示(Coordinated Representation)?
多模态协同表示是一种将多个模态的信息分别映射到各自的表示空间,但映射后的向量或表示之间需要满足一定的相关性或约束条件的方法。这种方法的核心在于确保不同模态之间的信息在协同空间内能够相互协作,共同优化模型的性能。
二、多模态融合
什么是多模态融合(MultiModal Fusion)?
多模态融合能够充分利用不同模态之间的互补性,它将抽取自不同模态的信息整合成一个稳定的多模态表征。从数据处理的层次角度将多模态融合分为数据级融合、特征级融合和目标级融合。
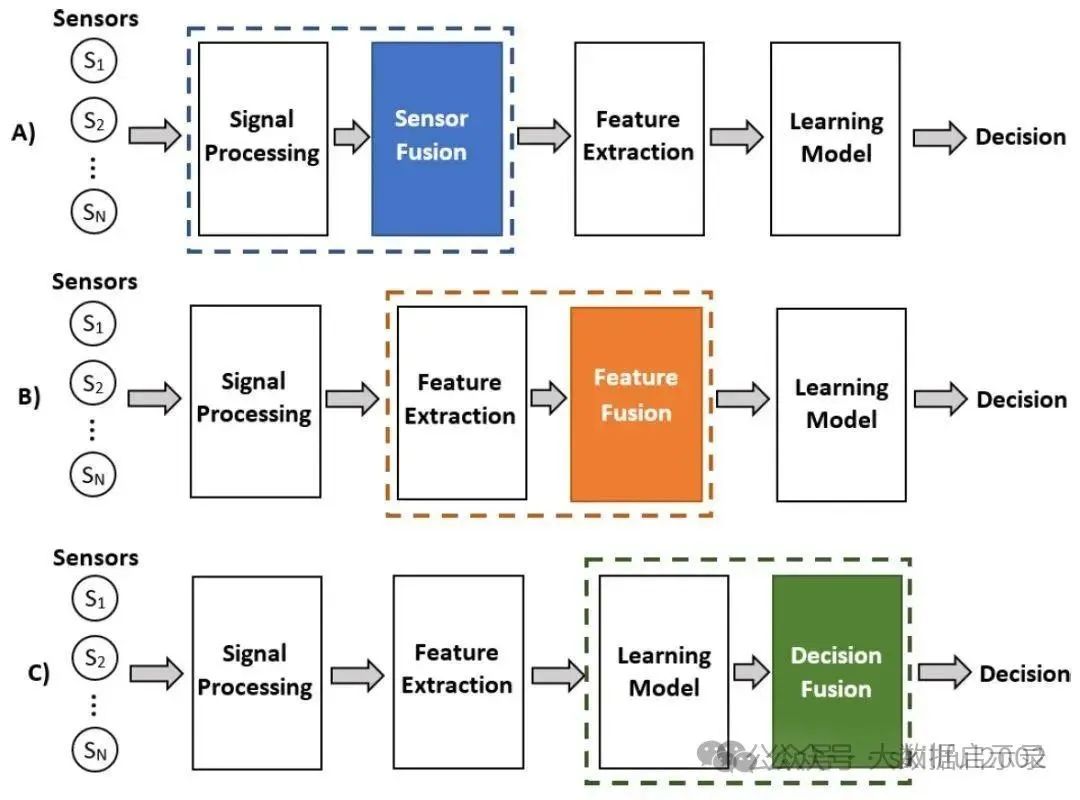
- 数据级融合(Data-Level Fusion):
- 数据级融合,也称为像素级融合或原始数据融合,是在最底层的数据级别上进行融合。这种融合方式通常发生在数据预处理阶段,即将来自不同模态的原始数据直接合并或叠加在一起,形成一个新的数据集。
- 应用场景:适用于那些原始数据之间具有高度相关性和互补性的情况,如图像和深度图的融合。
- 特征级融合(Feature-Level Fusion):
- 特征级融合是在特征提取之后、决策之前进行的融合。不同模态的数据首先被分别处理,提取出各自的特征表示,然后将这些特征表示在某一特征层上进行融合。
- 应用场景:广泛应用于图像分类、语音识别、情感分析等多模态任务中。
- 目标级融合(Decision-Level Fusion):
- 目标级融合,也称为决策级融合或后期融合,是在各个单模态模型分别做出决策之后进行的融合。每个模态的模型首先独立地处理数据并给出自己的预测结果(如分类标签、回归值等),然后将这些预测结果进行整合以得到最终的决策结果。
- 应用场景:适用于那些需要综合考虑多个独立模型预测结果的场景,如多传感器数据融合、多专家意见综合等。
三、跨模态对齐
什么是跨模态对齐(MultiModal Alignment)?
跨模态对齐是通过各种技术手段,实现不同模态数据(如图像、文本、音频等)在特征、语义或表示层面上的匹配与对应。跨模态对齐主要分为两大类:显式对齐和隐式对齐。

什么是显示对齐(Explicit Alignment)?
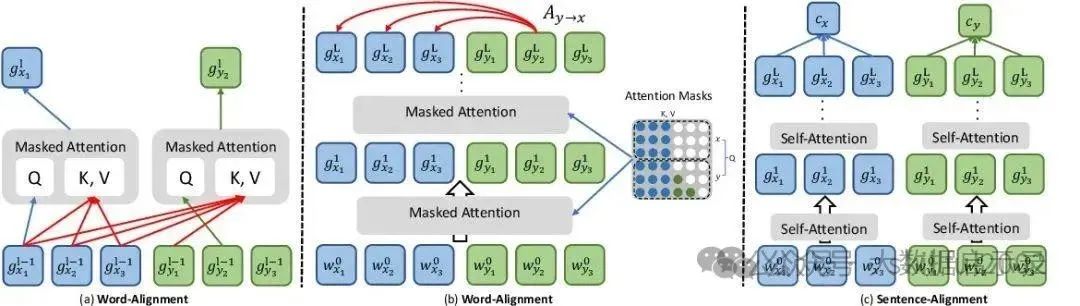
什么是隐式对齐(Implicit Alignment)?
开源社区模型
MiniGPT-4:基于 BLIP-2 和 Vicuna,通过轻量化设计实现类似 GPT-4V 的图文交互。
mPLUG-Owl:支持多模态指令跟随,可处理文本、图像和视频。 OpenFlamingo:Flamingo 的开源复现版本,支持少样本学习
7、MCP
MCP(Model Context Protocol,模型上下文协议) 是由 Anthropic 推出的一种开放标准,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,MCP 使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。
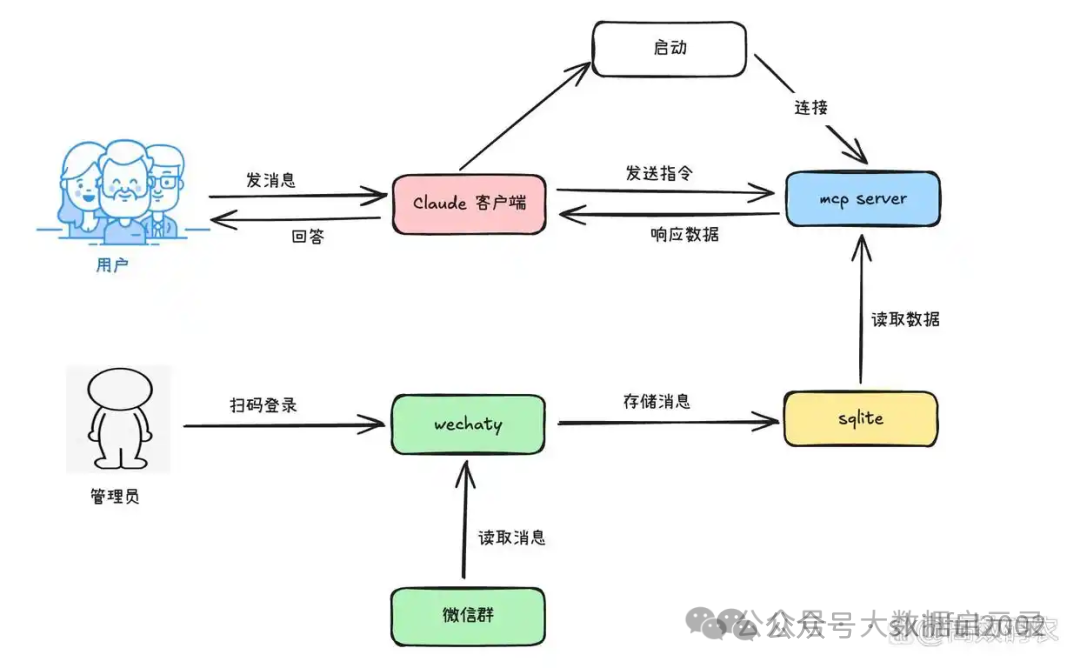
MCP协议的核心是将一般的AI AGENT函数调用的工程架构抽象为了客户端、服务器结构,可以理解为是对函数调用AGENT在工程层面实现了一个更好的抽象。抽象之后客户端可以是传统的服务请求、大模型请求、或者是一般的Tool请求等。服务器端的实现则是更适合大模型体质的方式,同时兼容非大模型的请求,服务器端的实现最核心的地方在于引入了Resources、Tools、Prompts等概念。
Resources主要作用是描述当前服务端,一般包含服务的唯一标识、服务的名称、服务的主要功能、以及其它相关信息(当通过大模型的客户端提问时,需要知道当前问题应该需要由哪个服务解决此时会依赖这个资源描述信息)。
Tools主要用于定义一组可用API,表示该服务可提供的功能,同时每个Tool都有类似Resources的描述,只不过Tool不需要唯一标识。
Prompts主要作用是为大模型实现的客户端提供一些有价值的上下文信息(这是可选的),可以是模板方式生成、也可以是动态的,取决于当前服务具体的功能是什么。
MCP的意义
- 建立开放的集成标准: 通过标准化应用程序与LLM之间的上下文交互方式,提升模型的上下文感知能力和任务协作能力。
- 加强数据安全与控制: 所有操作均需用户授权,且MCP服务部署于本地,有效避免数据外泄风险,保障数据安全。
- 构建丰富的工具生态: 解决了过去LLM工具不兼容的问题,提供多样化的工具选择。
MCP架构
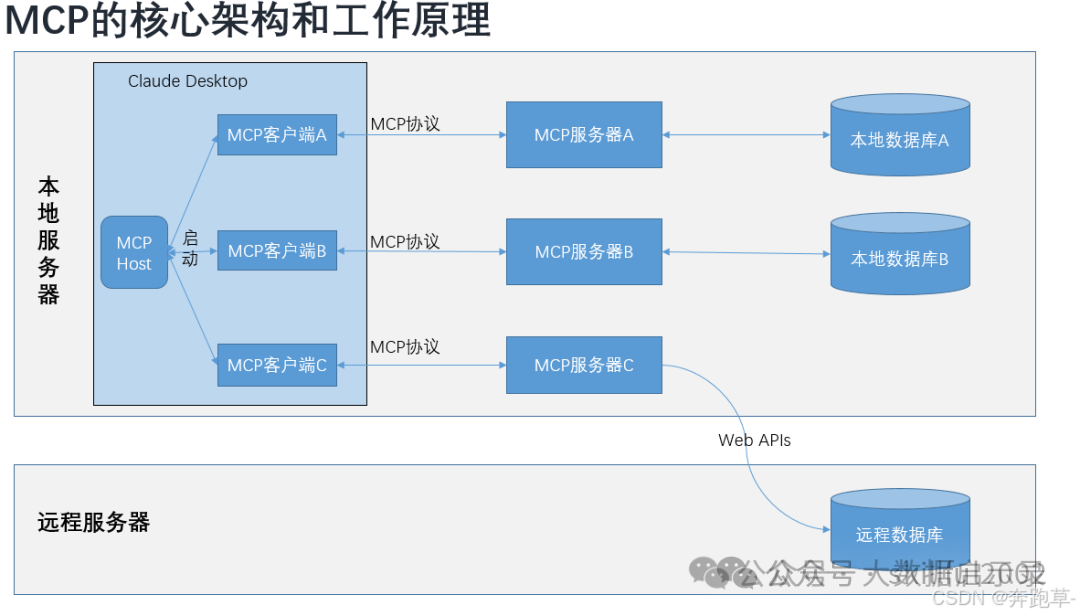
MCP主机:像Claude Desktop、集成开发环境(IDEs)或希望通过MCP访问数据的AI工具这样的程序。
MCP客户端:与服务器保持1:1连接的协议客户端。
MCP服务器:通过标准化的模型上下文协议(MCP)暴露特定能力的轻量级程序。
本地数据源(注:目前主要还是本地化操作,对于云端操作还是有局限性):计算机上的文件、数据库和服务,MCP服务器可以安全地访问。
远程服务:通过互联网可用的外部系统(例如,通过APIs),MCP服务器可以连接到这些系统。
MCP Client
MCP client 充当 LLM 和 MCP server 之间的桥梁,MCP client 的工作流程如下:
- MCP client 首先从 MCP server 获取可用的工具列表。
- 将用户的查询连同工具描述通过 function calling 一起发送给 LLM。
- 如果需要使用工具,MCP client 会通过 MCP server 执行相应的工具调用。
MCP Server
MCP server 是 MCP 架构中的关键组件,它可以提供 3 种主要类型的功能:
资源(Resources):类似文件的数据,可以被客户端读取,如 API 响应或文件内容。
工具(Tools):可以被 LLM 调用的函数(需要用户批准)。
提示(Prompts):预先编写的模板,帮助用户完成特定任务。
这些功能使 MCP server 能够为 AI 应用提供丰富的上下文信息和操作能力,从而增强 LLM 的实用性和灵活性。 你可以在 MCP Servers Repository 和 Awesome MCP Servers 这两个 repo 中找到许多由社区实现的 MCP server。使用 TypeScript 编写的 MCP server 可以通过 npx 命令来运行,使用 Python 编写的 MCP server 可以通过 uvx 命令来运行。
8、扩散模型
什么是扩散模型?
扩散模型(Diffusion Models)是一类基于概率生成模型的深度学习方法,近年来在图像生成、语音合成、文本生成等领域取得了显著的成果。它通过模拟物理扩散过程,将数据逐步转化为噪声,再学习一个逆向过程,从噪声中逐步恢复出原始数据,最终实现高质量的生成。 扩散模型的核心思想包括两个主要过程:
- 正向扩散过程(Forward Diffusion Process) 逐步向数据中添加噪声,使其转变为纯噪声。 通常用一个马尔可夫链表示,每一步加少量高斯噪声。
- 逆向生成过程(Reverse Generation Process) 学习一个逆向扩散的马尔可夫链,从噪声中逐步去除噪声,恢复出原始数据。 通过神经网络来预测并消除各步所添加的噪声。
通过这两个过程,可以在训练时把真实数据变成纯噪声,然后在生成时从纯噪声“还原”出逼真的数据样本。 ``
扩散模型的类型
扩散模型的类型主要包括以下几种:
- 这是一种通过逐步添加噪声到数据中,形成正向扩散过程,然后学习如何从噪声中恢复出原始数据的模型。
- DDPM通过一个马尔可夫链来实现数据的生成过程,首先将数据逐步加噪,形成一个完全随机的噪声分布,然后通过学习反向过程,将噪声逐步去除,恢复出高质量的样本。
- 在图像生成任务中,DDPM显示出优越性能,例如在CIFAR-10数据集上的Inception分数达到9.46,FID分数为3.17。
- SGMs是一种新兴的生成模型,主要通过学习数据分布的得分函数来实现样本生成。
- 这种方法不直接建模数据的概率分布,而是通过对数概率密度函数的梯度进行建模。
- SGMs利用随机微分方程(SDE)来描述扩散过程,并通过Langevin动力学进行采样。在图像生成任务中,SGMs能够生成与GAN相媲美的样本质量。
- SDE作为描述随时间变化的随机过程的重要工具,广泛应用于物理学、金融学等多个领域。
- 在金融市场中,SDE尤其擅长处理那些对市场结果产生重大影响的随机因素。通过SDE,我们可以对这类金融衍生品(如原油期货合约)进行精确计算,不仅能建模价格波动,还能准确估算优惠价格,为市场参与者提供更为可靠的决策依据。
市场上的主要扩散模型产品
DALL-E:DALL-E是由OpenAI开发的一系列AI图像生成器,能够根据自然语言描述生成逼真的图像和艺术作品。DALL-E 2于2022年4月推出,能够更好地理解和处理复杂的文本描述。现在OpenAI已经把DALL-E集成到它的ChatGPT系列产品中。
Stable Diffusion:由Stability AI创立的标准扩散模型,实质为两阶段训练过程,在多主题提示、无条件图像生成、文本到图像合成以及超分辨率任务中取得明显的优势。同时,通过克服像素空间操作的计算挑战,Stable Diffusion可以满足用户的可扩展性和质量需求。此外,DreamStudio作为由Stability AI开发的Stable Diffusion的简化版本,允许用户通过简单的文本输入生成高质量的图像。
Sora:Sora是OpenAI在2024年2月发布的首个文本生成视频模型,继承了DALL-E 3的画质和遵循指令能力,能根据用户文本提示快速制作长达一分钟的高保真视频,还可从静态图像生成视频。Sora可以理解复杂场景中元素的物理属性及关系,生成具有多个角色、特定运动的复杂场景,具有高度可定制性和可扩展性。
Midjourney:Midjourney提供更多梦幻般的艺术风格视觉效果,如安迪・沃霍尔、达芬奇、达利和毕加索等,还能识别特定镜头或摄影术语,从而吸引那些从事科幻文学或需要更多艺术风格作品的人。Midjourney更像是一种绘画工具,它旨在提供更高的图像质量、更多样化的输出、更广泛的风格范围和更好的图像动态范围。
Imagen:由Google开发的基于扩散的图像生成模型,利用大型Transformer语言模型的功能来理解文本,同时依靠扩散模型的强大功能来生成保真度极高的高质量图像,采用多尺度生成策略和噪声调节增强技术,可生成高分辨率、细节丰富、色彩准确的图像。Imagen使用相当大的无分类器指导权重来指导和控制图像生成,从而增强了照片真实感和图像文本对齐。
9、模型蒸馏
模型蒸馏的概念
模型蒸馏(Model Distillation):是一种模型压缩和知识迁移的技术,旨在将一个大型、复杂且性能优异的教师模型(Teacher Model)中的知识传递给一个较小、计算效率更高的学生模型(Student Model),将复杂且大的模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力,复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的Student小模型。 其核心思想是利用教师模型输出的软标签(soft targets)—— 即概率分布而非硬标签(hard labels),来指导学生模型的训练。通过这种方式,学生模型不仅学习到数据的类别信息,还能够捕捉到类别之间的相似性和关系,从而提升其泛化能力。 蒸馏过程通常包括以下几个步骤:
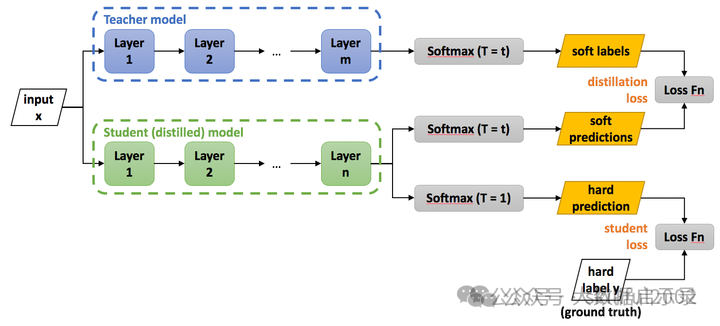
- 训练教师模型:首先训练一个大型的、性能较好的模型作为教师模型。教师模型可以是任何高性能的深度学习模型,如深层神经网络、卷积神经网络(CNN)、Transformer等。
- 生成软标签:训练好的教师模型对训练数据进行预测,获得每个样本的概率分布。这些概率分布作为软标签,包含了类别之间的相对关系信息。
- 训练学生模型:使用这些软标签来训练学生模型,使其能够模仿教师模型的行为。
- 优化损失函数:在训练过程中,通常会结合学生模型自身的损失和蒸馏损失,以确保学生模型不仅学习到输入数据的特征,还能捕捉到教师模型的“隐含知识”。
该方法的优势在于能够在不显著损失性能的情况下,显著减少模型大小和计算需求,特别适用于资源受限的设备,如移动设备和嵌入式系统。
1、蒸馏的知识迁移优势
- 模型 A 是通过蒸馏从一个更大、更强的模型(教师模型)中获得知识的。蒸馏的过程并不仅仅是复制大模型的输出,而是让小模型学习到大模型的决策过程、内部表示和隐含知识。这样,模型 A 在训练过程中能够 接收到更多的高质量指导,尤其是在复杂的推理、模式识别和特征提取方面。
- 通过蒸馏,模型 A 实际上学会了一个已经“成熟”的模型的很多优点,比如对上下文的理解能力、处理边缘情况的能力以及通过大量训练积累的 先验知识,这些是从零训练的模型(B)很难在同样的数据量和训练时间下学到的。
2、训练过程中的指导作用
- 在模型 B 的训练过程中,它是从随机初始化开始的,没有任何先前的知识。它的每一个参数都是从头开始学习,可能需要更多的训练数据和更长的时间,才能逐步接近其理论上的最优状态。
- 与之对比,模型 A 通过蒸馏直接从教师模型(通常具有强大的能力)中学习。这意味着模型 A 的学习过程是高效的,它利用教师模型的“智慧”来进行学习,在较少的训练数据和计算资源下可能就能表现得很好。
3、大模型的泛化能力
- 大模型(即教师模型)通常具有很强的泛化能力,因为它是在大量的数据上训练出来的。通过蒸馏,小模型(A)能够继承教师模型的一部分泛化能力,尤其是在不确定的、少见的模式识别上,这对于提高模型的性能是非常有帮助的。
- 模型B从零开始,缺乏这种来自大模型的“润色”或高质量的指导,因此在面对复杂的、边缘的或数据稀缺的任务时,B 模型的表现可能会较差,尤其是在数据量有限的情况下。 说明一下,在做模型蒸馏时,教师模型和学生模型的架构可以不同。蒸馏的核心在于将教师模型的知识(如输出分布或中间特征)传递给学生模型,而不是直接复制其架构。这种灵活性使得蒸馏可以应用于不同架构的模型之间
模型量化(Model Quantization):
模型量化是一种通过减少模型参数和计算表示精度来压缩模型的技术。其主要目的是将浮点数参数转换为低精度整数(如8位或更低),从而减少存储需求和计算成本。量化过程通常分为以下几种:
模型蒸馏: 主要通过知识迁移来实现小型化,适用于需要高效推理但对精度要求较高的场景。
模型量化: 通过降低参数精度来减少存储和计算成本,适用于资源受限的设备和需要快速推理的应用场景。

10、Embedding模型
Embedding: 这是一个通用术语,指的是将数据(可以是词、句子、图像等)转换成数值向量形式的过程。这些向量捕捉了数据的某些特征或属性,使得机器学习算法能够处理。可以应用于多种类型的数据,不仅限于文本,还可以是图像、声音等,而词嵌入特指文本中的单词或短语的嵌入。 Embedding 通常指将高维度的数据映射到低维度的空间中 。
词嵌入(Word Embedding): 词嵌入是特定于文本数据的嵌入形式,它将单词或短语转换成向量。这些向量能够表示单词的语义和语法特征,使得语义上相似的单词在向量空间中彼此接近。是嵌入技术在文本处理领域的应用。词嵌入生成的向量成为向量模型的输入,向量模型利用这些向量来进行各种下游任务。
向量模型(Vector Model): 向量模型通常指的是使用向量表示来处理数据的模型。在NLP中,这通常意味着使用词嵌入作为输入特征的模型。向量模型可以是用于分类、聚类、相似性度量等任务的任何机器学习或深度学习模型。是一个更广泛的概念,它不仅包括使用词嵌入的模型,还可以包括使用其他类型嵌入的模型。
一句话总结,词嵌入是嵌入技术在语言处理领域的具体实例,而向量模型则是利用这些嵌入向量进行任务处理的模型。在NLP中,词嵌入向量作为特征输入,使得向量模型能够理解和处理人类语言。
Embeddings 分类及对应模型
Embeddings 有许多种类别和变体,每种类型的 Embeddings 都有其特定的设计目标和应用场景,共同点在于它们都致力于将复杂而抽象的对象结构化并压缩到便于计算和比较的数值形式,以下是几种常见的 Embeddings 类型:
词嵌入
Word2Vec: 包括 CBOW (Continuous Bag-of-Words) 和 Skip-Gram 模型,由 Google 提出,用于学习单词之间的语义关系。 GloVe (Global Vectors for Word Representation): 由斯坦福大学开发,旨在结合全局统计信息和局部上下文窗口的优势来生成单词嵌入。 FastText: 由 Facebook AI 团队推出,不仅考虑单个单词,还考虑内部字符 n-gram,对于罕见词汇有更好的表现。 ELMo (Embeddings from Language Models): 利用双向 LSTM 对整个句子进行建模,产生上下文敏感的单词嵌入。
情景化话的词嵌入
BERT (Bidirectional Encoder Representations from Transformers): 由 Google 推出,利用Transformer架构的预训练模型,能够根据上下文提供动态的单词嵌入。 GPT (Generative Pre-training Transformer) 及其后续版本 GPT-2/3/4:由 OpenAI 开发,也是基于Transformer的自回归模型,同样能产出上下文相关的嵌入。 XLNet、RoBERTa 等都是BERT之后改进或扩展的预训练模型。
句子和文档嵌入
Doc2Vec: 扩展了 Word2Vec,能够为整个文档生成统一的向量表示。 Average Word Embeddings: 将一段文本中所有单词的嵌入取平均作为整体的文本表示。 Transformers Sentence Embeddings: 如BERT的[CLS]标记对应的向量,或者专门针对句子级别的模型如Sentence-BERT。
实体/概念嵌入
Knowledge Graph Embeddings: 如 TransE、DistMult、ComplEx 等,用于将知识图谱中的实体和关系嵌入到低维向量空间中。
其他类型
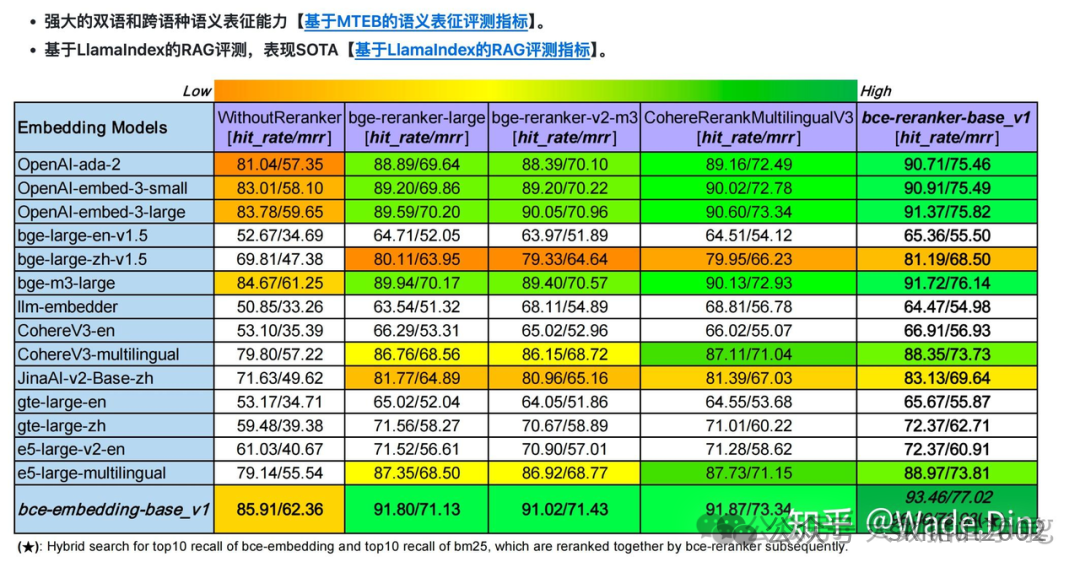
图像 Embeddings: 使用卷积神经网络(CNN )进行图像特征提取,得到的特征向量即为图像嵌入。 音频 Embeddings: 在语音识别和声纹识别中,将声音信号转化为有意义的向量表示。 用户/物品 Embeddings:在推荐系统中,将用户行为或物品属性映射到低维空间以进行协同过滤或基于内容的推荐。 还有一种图 Embeddings:是用于学习图结构的表示学习方法,将图中的节点和边映射到低维向量空间 中。通过学习图嵌入,可以将复杂的图结构转化为向量表示,以捕捉节点之间的结构和关联关系。这些方法可 以通过DeepWalk、Node2Vec、GraphSAGE等算法来实现。图嵌入在图分析、社交网络分析、推荐系统等领 域中广泛应用,用于发现社区结构、节点相似性、信息传播等图属性。 以下是5个主流的Embedding模型,推荐给大家用于搭建RAG系统做参考:
BGE Embedding:由智源研究院开发,支持多语言,提供多个版本,包括高效的reranker。该模型开源且许可宽松,适用于检索、分类、聚类等任务。GTE Embedding:由阿里巴巴达摩院推出,基于BERT框架,适用于信息检索和语义相似性判断等场景,性能卓越。Jina Embedding:由Jina AI的Finetuner团队打造,基于Linnaeus-Clean数据集训练,适用于信息检索和语义相似性判断,性能出众。Conan-Embedding:这是一个针对中文优化的Embedding模型,在C-MTEB上达到了SOTA(State-of-the-Art)水平,特别适合需要高精度中文语义表示的RAG系统。text-embedding-ada-002:由Xenova团队开发,与Hugging Face库兼容,提供高质量的文本向量表示,适用于多种NLP任务。
Embeddings 常规文本嵌入模型对比与选型
下是针对 mxbai-embed-large、bge-m3、bge-large、nomic-embed-text、m3e-base、GTE-Qwen2-7B-instruct、text-embedding-ada-002 等文本嵌入模型的详细对比与选择指南,结合性能、场景和资源需求:
模型对比表
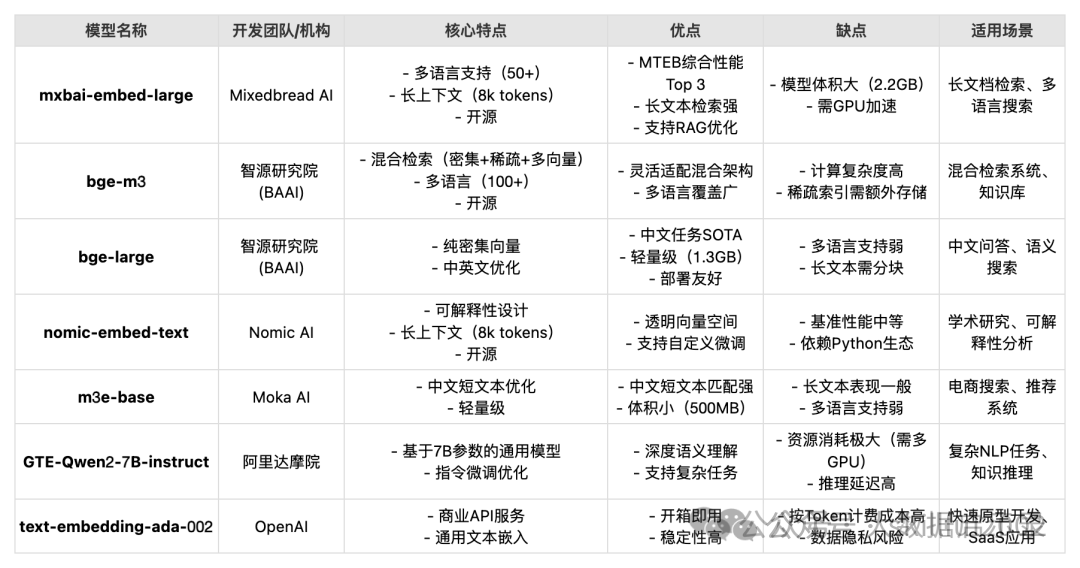
关键指标对比
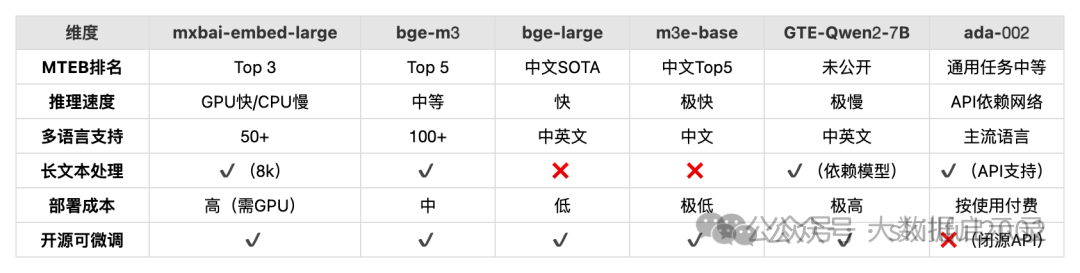
场景化选择指南
1. 中文场景优先
- 开源:mxbai-embed-large(长上下文支持)
2. 多语言混合场景
- 经济型:text-embedding-ada-002(预算充足时)
3. 资源敏感场景
- 多任务通用:GTE-Qwen2-7B(需充足算力)
4. 研究/可解释性需求
- 必选:nomic-embed-text(可视化工具链完善)
5. 商业快速集成
- 无开发资源:text-embedding-ada-002(OpenAI API)
- 阿里生态整合:GTE-Qwen2-7B(适配阿里云服务)
部署建议
- 量化压缩:使用 bitsandbytes 对 bge-large/m3e-base 进行8-bit量化。
- 检索加速:搭配 FAISS 或 Milvus 构建索引。
- 长文本分块:对 bge-large 使用滑动窗口(如256 tokens重叠)。
- 成本控制:优先选择 text-embedding-3-small(性能相近,价格更低)。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











