






1. 人类角度的注意力机制
注意力机制早在上世纪九十年代就有研究,最早注意力机制应用在视觉领域,后来伴随着2017年Transformer模型结构的提出,注意力机制在NLP,CV相关问题的模型网络设计上被广泛应用。“注意力机制”实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分。
举例说明:当我们看到下面这张图时,短时间内大脑可能只对图片中的“锦江饭店”有印象,即注意力集中在了“锦江饭店”处。短时间内,大脑可能并没有注意到锦江饭店上面有一串电话号码,下面有几个行人,后面还有“喜运来大酒家”等信息。

所以,大脑在短时间内处理信息时,主要将图片中最吸引人注意力的部分读出来了,大脑注意力只关注吸引人的部分, 类似下图所示.

同样的如果我们在机器翻译中,我们要让机器注意到每个词向量之间的相关性,有侧重地进行翻译,模拟人类理解的过程。
-
核心思想
让模型在处理输入序列时,动态地学习哪些部分应该被重点关注,而不是像传统方法那样对所有部分同等对待。它通过计算每个输入位置的注意力权重,并根据这些权重对输入信息进行加权求和,从而得到一个更加关注重要信息的表示。
-
作用
注意力机制的核心作用是动态地分配权重,从而更好地捕捉输入数据中的重要信息。
以下是注意力机制的主要作用:
- 解决信息瓶颈问题
- 传统的 Seq2Seq 模型依赖于一个固定长度的上下文向量,导致信息丢失。
- 注意力机制通过动态地关注输入序列的不同部分,避免了信息瓶颈问题。
- 捕捉长距离依赖关系
- 在长序列任务中,传统的 RNN 模型难以捕捉远距离依赖关系。
- 注意力机制能够直接计算输入序列中任意两个元素之间的关系,从而更好地捕捉长距离依赖。
- 解决信息瓶颈问题
2. 注意力机制三大类
深度学习中的注意力机制通常可分为三类: 软注意(全局注意)、硬注意(局部注意)和自注意(内注意)
- 软注意机制(Soft/Global Attention):
对每个输入项分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。 - 硬注意机制(Hard/Local Attention,[了解即可]):
对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑哪部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。 - 自注意力机制(Self/Intra Attention,[transformer讲解]):
对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
3. 初步理解注意力机制
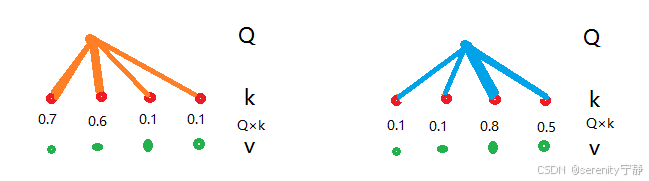
看到上面的图,可能是懵的。我们先简单抽象的理解一下。
我们先假设在注意力机制当中有Q,K,V三个矩阵。Q的大概意思是查询的句子所代表的矩阵;K的大概意思是在提问的整段话中每个句子所对应 id矩阵。而V的大概意思是提问的整段话中每个句子所代表的值矩阵
然后注意力是靠Q×K得到的权重矩阵,去乘以V矩阵,得到的输出结果
左边图:Q1×K1得到的0.7并且线比较粗,说明Q1和K1相似度较高。Q1×K2得到0.6,并且线还是比较粗,说明Q1和K2相似度还是较高。后面的Q1和K3,K4相似度0.1说明较低
右边图:另外一个查询语句Q,Q1×K1和K2都等于0.1说明相似度较低。Q1×K3=0.8并且线很粗,说明相似度很高,Q1×K4并且线相对粗,说明相似度不高也不低。
好了,现在肯定很多小同学有疑惑,Q是什么?K是什么?V到底是什么?
Q、K、V 的具体含义
从 NLP 的角度来看:
- Q(Query,查询):假设你在翻译一句话,当前的单词(例如
he)就是查询 Q,我们想知道它与句子中的哪些单词相关。 - K(Key,键):表示整个句子的所有单词,比如
he,is,a,boy。 - V(Value,值):表示这些单词的实际信息,例如它们的词向量。
从计算机视觉(CV)的角度来看:
- Q:代表目标图像的特定区域(比如某个物体)。
- K:代表整个图像的所有区域。
- V:代表每个区域的特征信息。
最终,通过Q × K 计算相似度,我们可以知道Q更应该关注K中的哪些部分,然后加权V中的值,得到最终输出。
在Transformer的论文中提到的第一个注意力机制:公式如下

画图解释:
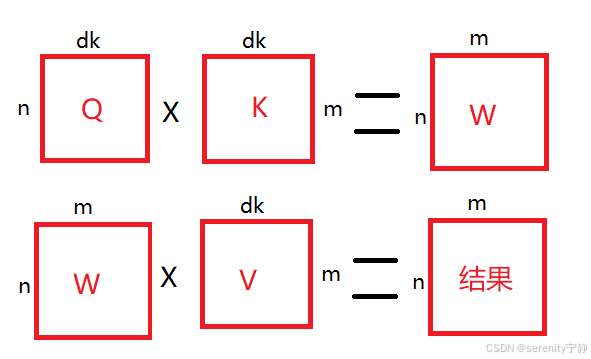
Q:有n行特征值长度为dk的向量
K:有m行特征值长度为dk的向量
矩阵相乘:(n,dk) × (m,dk)T = (n,m) T代表转置翻转矩阵
Q×K得到的是权重矩阵,权重就是查询语句和真实语句相似度的值。
拿W×V得到语义编码结果。
注:解释论文中为什么要除以根号dk,作者是这样说的,当dk比较大的时候,同一向量点乘可能导致结果向量值较大。这样softmax之后得到的结果就趋近于1。就可能导致梯队消失,原因是因为,梯度消失的时候也就是说训练好或训练到极限的时候,正确结果就是趋近于1,错误结果就是趋近于0的。
4. 解释论文中的注意力图:
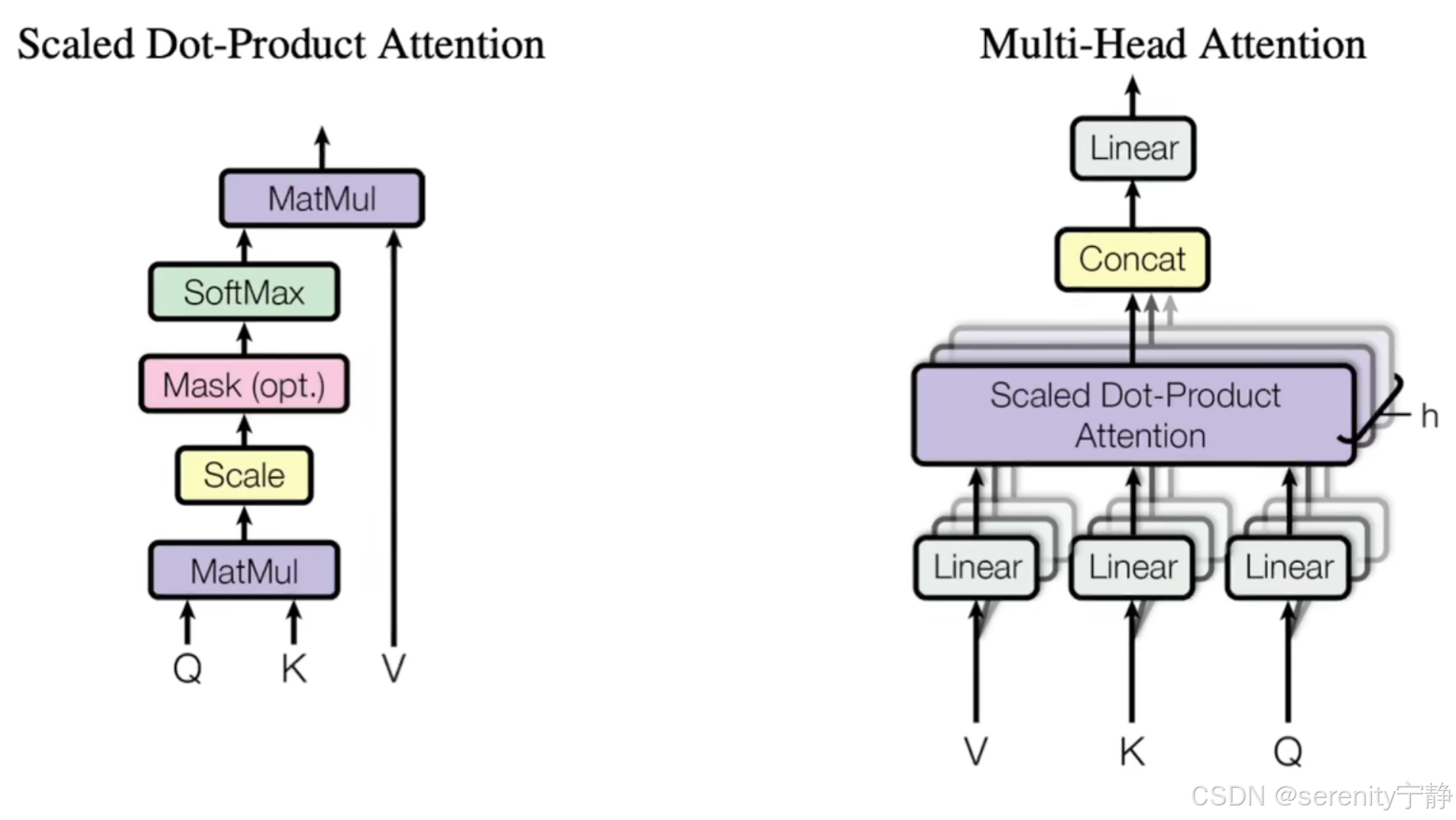
图中流程:
第一个MatMul:Q乘K
Scale:Q乘K的结果/dk
Mask:为了避免你在第t时间的时候看到以后时间的东西
详细解释Mask:假设Q和K都是等长的都是n,此时是我的Qt查询,那么我应该只是去和k1.....kt-1来进行计算,而不应该和kt....kn计算。但是我们知道注意力机制在Qt的时候,会看到所有的k。qt会和所有的k进行计算,算是可以算的,mask的意思就是将qt和kt...kn直接计算的结果,换成非常大的负数如-1*e10,那么当那么大的一个负数进入softmax的时候就会变成0,所以导致softmax出来的那些东西对应的权重都会变成零。所以我在output的时候,只用了v1到vt-1的结果用上了权重,之后的vt到vn乘以的都是0会消除掉。
softmax:对计算值进行归一化得到权重。
第二个MatMul:权重矩阵乘V
5. 解释论文中的多头注意力图:
解释下面作者的话的前言:投影的意思:将Q,K,V矩阵分别通过nn.Linear的线性层(wx+b)变为不同维度。如全连接中某一层:nn.Linear(in_feature=512,out_feature=256)相当于将512的向量维度转为了256的维度。投影h次的意思:nn.Linear(in_feature=512,out_feature=256)这样的代码有h个
论文的作者说:与其我做一个单个的注意力函数。不如说我把整个query,key,value投影到一个低维,投影h次。然后再做h次的注意力函数。然后把每一个注意力函数的结果并在一起。然后再投影回来得到我最终的输出。
多头注意力机制vs注意力机制的好处:我先让你投影到一个低维,这个投影的W是可以学的(就是说这个W是可以通过反向传播而动态变化的参数)。而注意力机制就是一个函数,学到的东西很少。
总结:这个多头注意力机制,有点像卷积中多个通道的感觉。
在论文中h是用的8,因为论文中模型的dk是用的512维,所以投影之后的维度是512/8=64维。然后再算注意力函数,最后投影回512维
6. Transformer总体架构图
6.1 编码器:
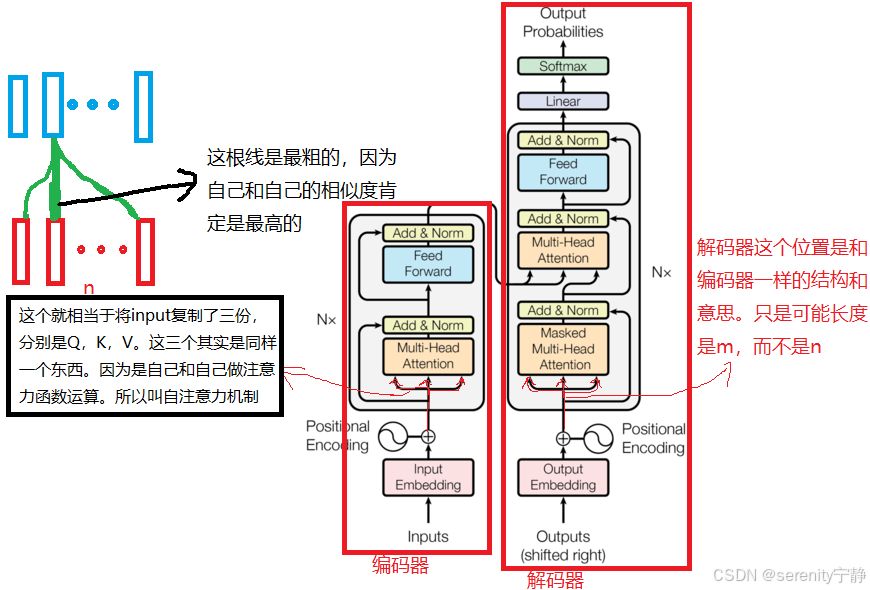
6.2 解码器上半场:
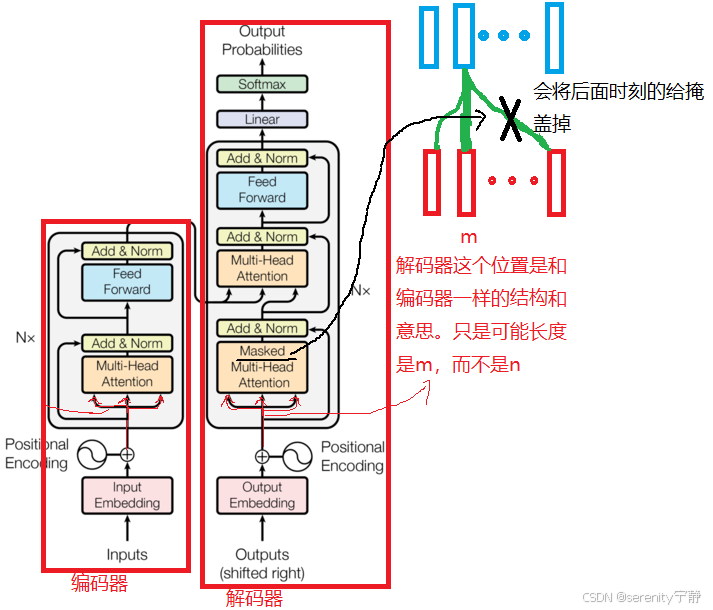
6.3 解码器下半场:
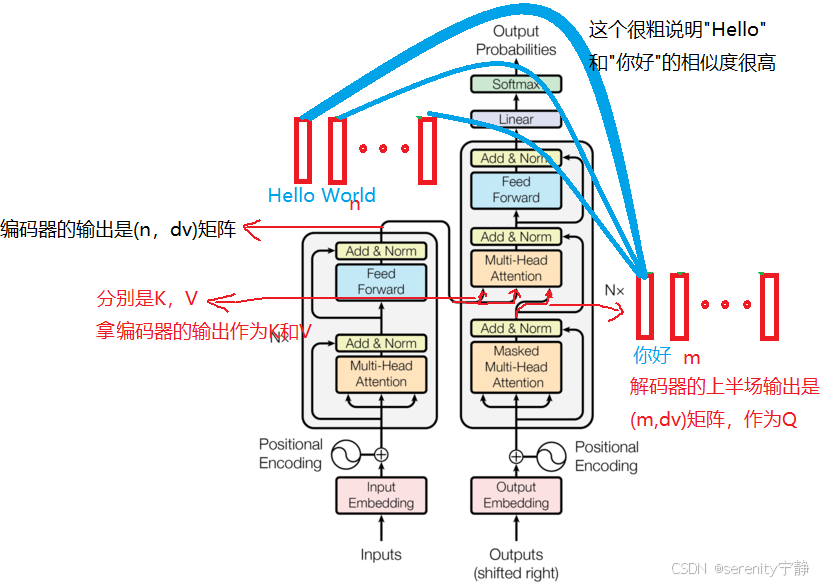
总的来说,就是编码器的输出是(n,dk)的矩阵,代表的意思就是n个词组成的句子,每个词的特征向量是dk维度。然后将这个(n,dk)的矩阵作为K和V---》输入到解码器的下半场的多头注意力中。解码器的上半场输出的是(m,dk)的矩阵,作为Q---》输入到解码器的下半场的多头注意力中。
然后下半场的多头注意力机制计算过程:Q会和K求相似度,提取出编码器中我感兴趣的部分(或者说相似度高的部分)
注意:根据解码器的输入(图中Outputs)不同,则会去编码器的输出中挑选出不同的感兴趣的部分。和我当前解码器输入相似度低的则会忽略掉。这就是编码器和解码器之间如何传递信息的。
6.4 FNN前馈神经网络
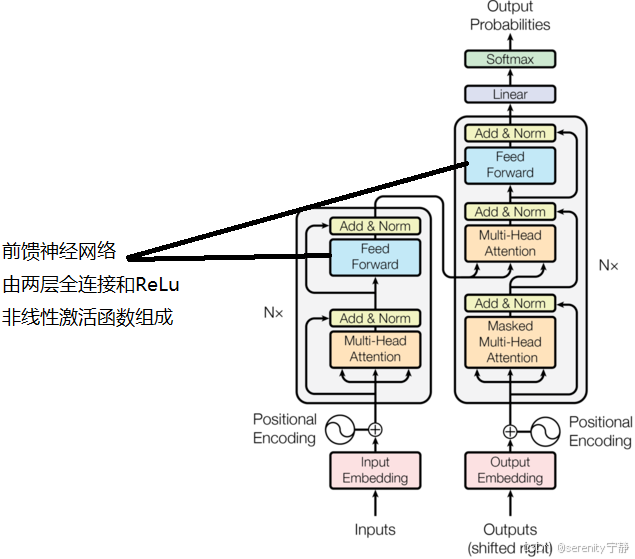
给定输入 x(每个 token 在 self-attention 之后的表示),FFN 计算如下:
![]()
代码如下:
import torch
import torch.nn as nn
class FFN(nn.Module):
def __init__(self, input_dim=512, hidden_dim=2048):
super().__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim) # 线性变换 512 -> 2048
self.activation = nn.ReLU() # 非线性激活函数
self.fc2 = nn.Linear(hidden_dim, input_dim) # 线性变换 2048 -> 512
def forward(self, x):
x = self.fc1(x) # 线性变换
x = self.activation(x) # 非线性变换
x = self.fc2(x) # 线性变换
return x
6.4.1 非线性变换的意义
1. 让 Transformer 具有更强的表达能力
自注意力(Self-Attention)部分本质上是线性变换(加权求和),如果 FFN 也是纯线性,那整个 Transformer 仍然是线性模型,无法学习复杂特征。FFN 通过 ReLU 让网络变成非线性,使模型能学习更复杂的模式。
2. 让不同 token 具有更复杂的特征变换
Self-Attention 是 token 间的交互,但它本身只是加权求和。FFN 让每个 token 都能单独进行非线性变换,从而丰富 token 的特征表达。
3. 让高维特征更充分地转换
通过 512 → 2048 → 512 这样的变换:
- 512 → 2048:扩展维度,让信息分布到更高维度,可以学习更复杂的特征。
- 2048 → 512:降维,避免参数量过大,同时保留重要特征。
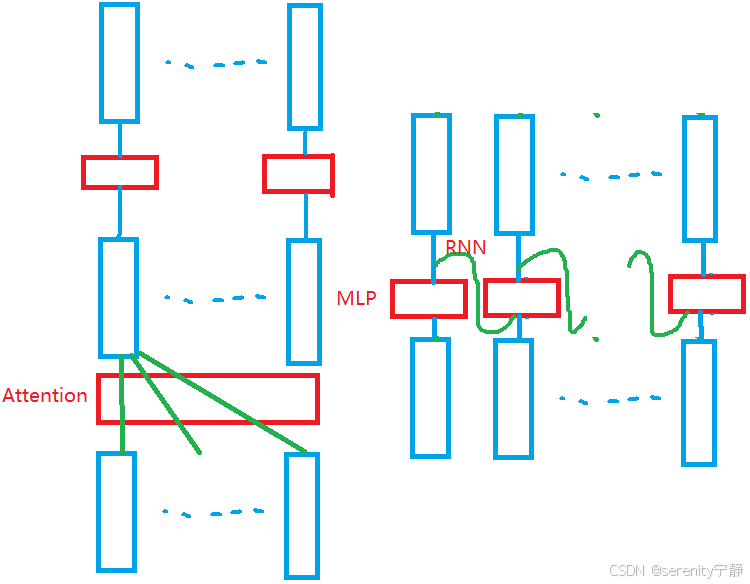
左边是transformer的简易图,attention部分是让每一个token都会去计算和其他所有token的关系,得到序列信息,再将序列信息传入到MLP中进行特征提取和非线性变换。
右边是RNN的简易图,没有注意力机制,是使用将前一个token的输出信息传给下一个token这种方式产生跨token的序列信息,同样也是传入MLP进行特征提取和非线性变换。
总结:Attention层是为了注意到应该注意的token上产生的序列信息,FNN是为了如何有效的利用序列信息。
6.5 Embeddings和softmax层
Embeddings 层的作用:
将输入的 token 索引(整数) 转换为 连续的向量表示(浮点数),这样可以让模型能够在高维空间中学习到词的语义信息。
公式:
假设词表(Vocabulary)大小为 V,词向量的维度为 d,那么嵌入矩阵 E的形状为:
![]()
对于输入 token x,其嵌入向量表示为:
![]()
其中,E[x] 表示从嵌入矩阵 E 中取出索引为 x 的行。
在 Transformer 中,词嵌入通常会与位置编码相加,确保模型能够捕捉到词的顺序信息:
embedding_output = embedding_layer(input_tokens) + positional_encoding(input_tokens)
特点:
- 通过 梯度下降,嵌入矩阵 EEE 在训练过程中被优化,使得相似的词具有更相似的表示。
- 使用固定大小的向量(如 512 维)来表示不同的词,有助于捕获语义信息。
6.6 位置编码器Positional Encoding
由于 Transformer 结构中没有循环结构(不像 RNN 那样依靠时间步),无法隐式地捕捉序列的位置信息。因此,需要引入 位置编码(Positional Encoding) 来为序列中的每个词提供位置信息。
位置编码的公式
论文中使用 正弦和余弦函数 来生成位置编码:
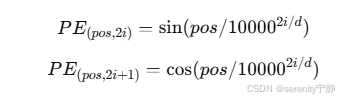
其中:
- pospospos 是词在序列中的位置
- iii 是特征维度的索引
- ddd 是嵌入维度
这种编码方式的优点:
- 位置编码的相对关系可以通过加法或减法保持,帮助模型捕捉词之间的相对位置。
- 位置编码的值是固定的,不依赖于数据,因此不需要训练参数。
7. 为什么说Transformer是CNN和RNN的终结者?
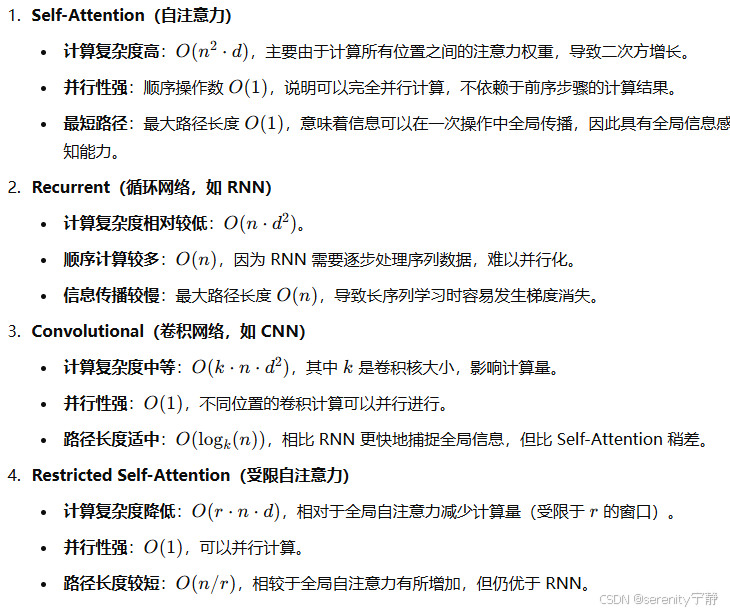
7.1 论文中的模型比较:

术语解释:
- Layer Type(层类型):不同类型的神经网络层,包括自注意力(Self-Attention)、循环(Recurrent)、卷积(Convolutional)等。
- Complexity per Layer(每层计算复杂度):衡量该层计算量的增长情况,主要关注输入序列长度 nnn 和隐藏层维度 ddd。
- Sequential Operations(顺序操作数):表示该层执行过程中涉及的顺序计算步数,较低的顺序计算意味着更易于并行计算。
- Maximum Path Length(最大路径长度):指的是在该层架构下,信息从输入传递到输出所需的最大步长。较短的路径通常意味着更快的信息传播和更好的梯度流。
7.2 各层特点分析



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











