






1. 介绍BatchNorm
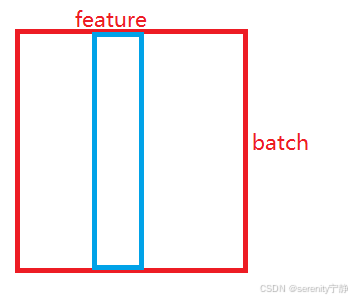
BatchNorm是对每一列变成均值为0方差为1的数。,即是对一个批次中的每一个特征点进行标准化。
在深度神经网络训练过程中,不同层的输入数据分布会不断变化(称为 Internal Covariate Shift,内部协变量偏移)。这会导致:
- 训练变得不稳定(梯度爆炸或梯度消失)
- 需要更小的学习率,收敛速度变慢
- 依赖于复杂的参数初始化
BatchNorm 通过对每一层的输入进行归一化,使其均值接近 0,方差接近 1,从而: ✅ 稳定梯度,防止梯度消失或爆炸
✅ 加快收敛速度,减少训练时间
✅ 减少对权重初始化的敏感性
✅ 一定程度上减少过拟合(但不等同于 Dropout)
图如下:
2. 介绍一下LayerNorm
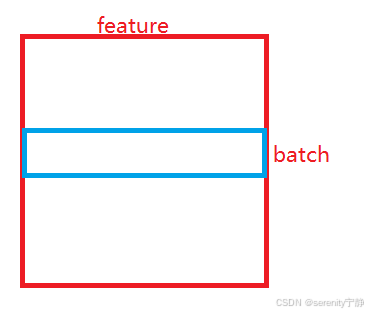
LayerNorm是对每一行变成均值为0方差为1的数。即是对一个样本中的所有的特征点进行标准化。
3. 在NLP自然语言中的区别
seq是指一个样本中(一句话中)词的多少。例如I Love You的seq=3
3.1 BatchNorm:
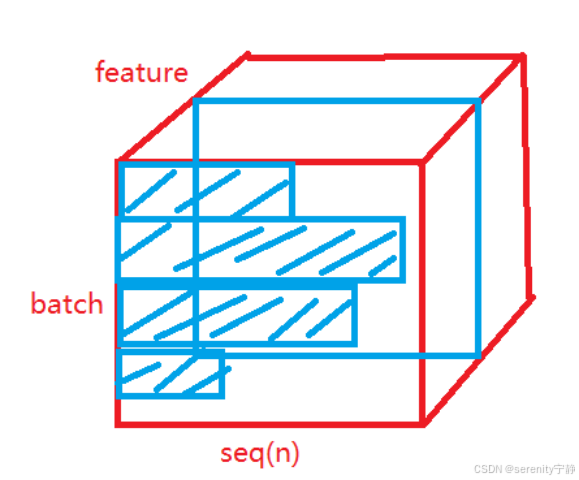
batchNorm是矩形长条组成的一面内计算均值和方差来进行标准化,但是由于句子长短不一,可能导致计算的方差和均值偏向于较长的句子或较短的句子,从而出现梯度的抖动。
3.2 LayerNorm
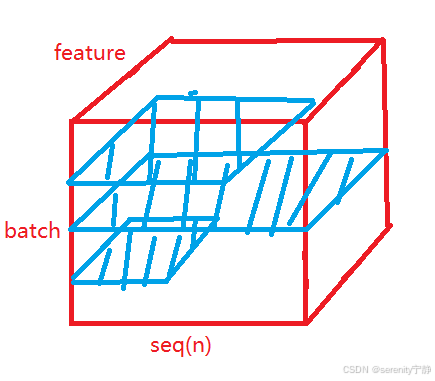
而layerNorm是在蓝色平面内求方差和均值,即每一个样本句子内部求方差和均值,则不会相互影响到其他样本句子。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











