 利用Spark进行通信用户数据分析
利用Spark进行通信用户数据分析




 文章讲述了如何使用Spark进行通信公司用户数据的统计计算,创建SparkSession,读取CSV文件,分析并按不同收费金额和使用状态分组,计算活动用户数量。作者还分享了学习Spark的心得体会。
文章讲述了如何使用Spark进行通信公司用户数据的统计计算,创建SparkSession,读取CSV文件,分析并按不同收费金额和使用状态分组,计算活动用户数量。作者还分享了学习Spark的心得体会。
目录
1.创建SparkSession实例,命名为"demand2",使用本地[*]模式,设置Spark Driver的主机地址
一、准备用户数据
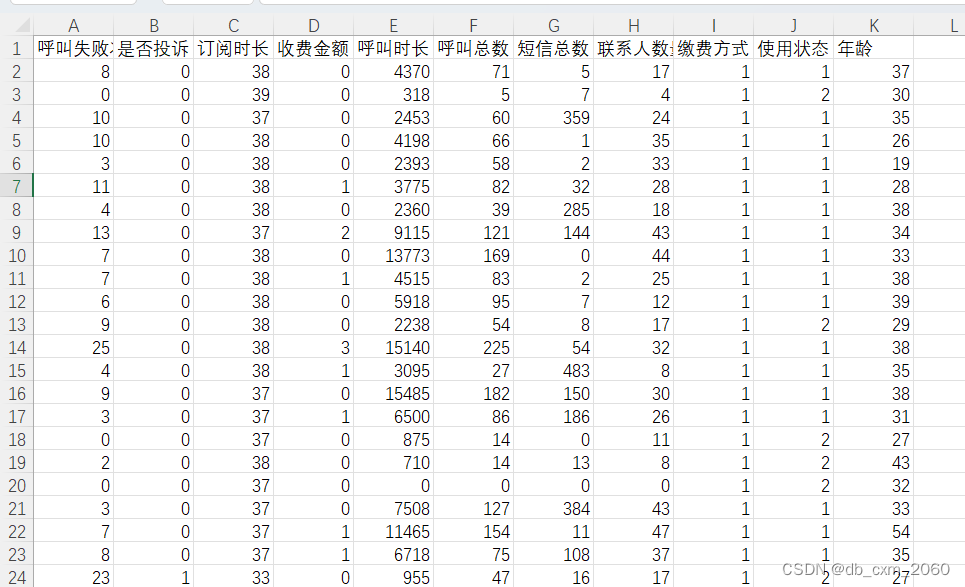
这里准备了3150条通信用户的数据,里面包括了呼叫失败次数,是否投诉,订阅时长,收费金额,呼叫时长,呼叫总,短信总数,联系人数量,缴费方式,使用状态,年龄等字段。
二、统计计算
这里计算该表用户不同收费金额,使用状态为活动的总人数。
1.创建SparkSession实例,命名为"demand2",使用本地[*]模式,设置Spark Driver的主机地址
import org.apache.spark.sql.SparkSession
object demand2 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName("demand1")
.master("local[*]")
// .config("spark.driver.host", "localhost")
.getOrCreate()2.读取通信公司用户数据Customer.csv
val data = session.read.
format("csv")
.option("header", "true")
.option("encoding", "GBK")
.load("Customer.csv")3.需求分析
从“不同收费金额,使用状态为活动的总人数”,这句话可知,该问题也就是按照金额跟使用状态对数据进行分类,然后求出不同金额,状态为活动的总人数。
4.需求计算
在学过的Spark算子中,涉及到对数据进行分类/分组的算子有groupByKey,因此在实现的过程中,要考虑使用上该算子,采用groupByKey算子来对数据进行分组。
将结果输入至控制台
// 不同收费金额,使用状态为活动的总人数
data.where("`使用状态`==1")
.groupBy("收费金额").count()
.withColumnRenamed("count","人数").show()
}
}三、结果展示

由图可知,从不同金额,使用状态为活动的分组结果如上,该数据没有统计按升序或降序进行排列。
四、Spark及Scala课程的心结体会
通过本学期的学习我知道了什么是Spark,Apache Spark作为下一代大数据处理引擎,现已成为当今大数据领域非常活跃、高效的大数据计算平台,很多互联网公司都使用Spark来实现公司的核心业务,例如阿里的云计算平台、京东的推荐系统等,只要和海量数据相关的领域,都有Spark的身影。
总的来说,学习了Spark,让我对大数据计算得到了进一步的加强,结合上个学期的Hadoop,我相信我也初步的掌握了大数据平台的搭建与使用,但在实际的操作中也还是会犯一些错误的,所以当我发现一些错误后我也积极进行改正和反馈,接下来的时间,要继续学习好Hadoop和Spark,我们唯有克服重重困难,才能取得成功。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









