




一、分片机制
kafka的分片,是为了解决单台服务器容量有限问题。当数据量比较大时,一台服务器放不下,将数据分成多个片,存储在多个服务器上。每个服务器上的数据叫做一个片。
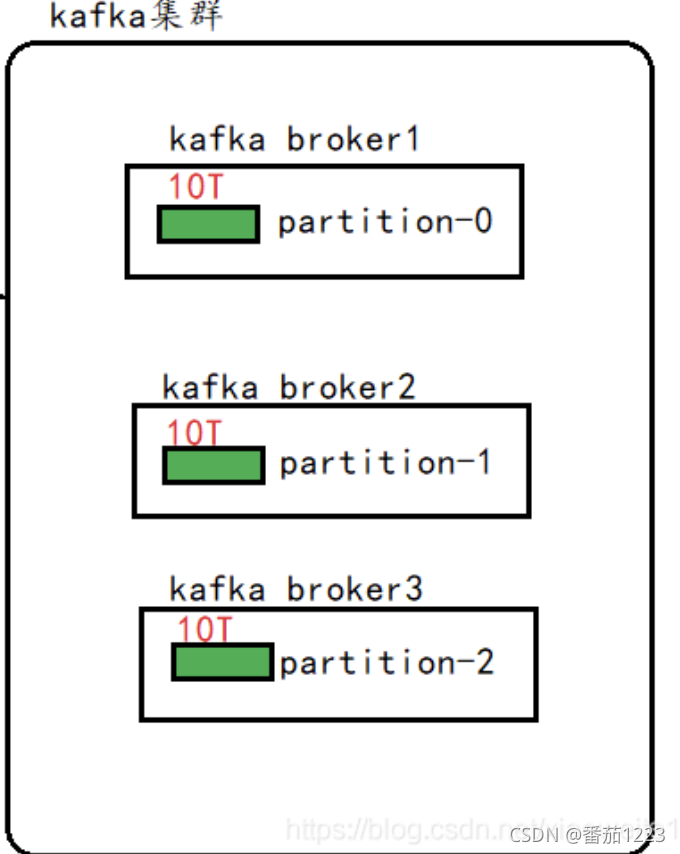
问题:分片后,数据存储在哪个片区怎么确定?
二、副本机制
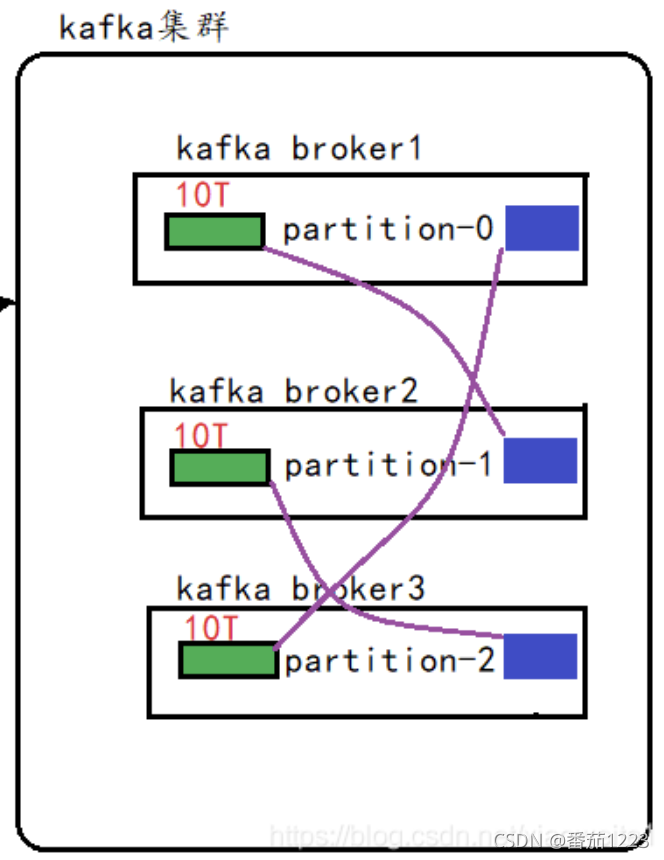
Kafka的副本机制,解决存储数据的高可用问题,一台服务器上存储数据,有丢失的风险。多拷贝几份数据到不同的服务器,可以达到容灾、容错的目的。
总结
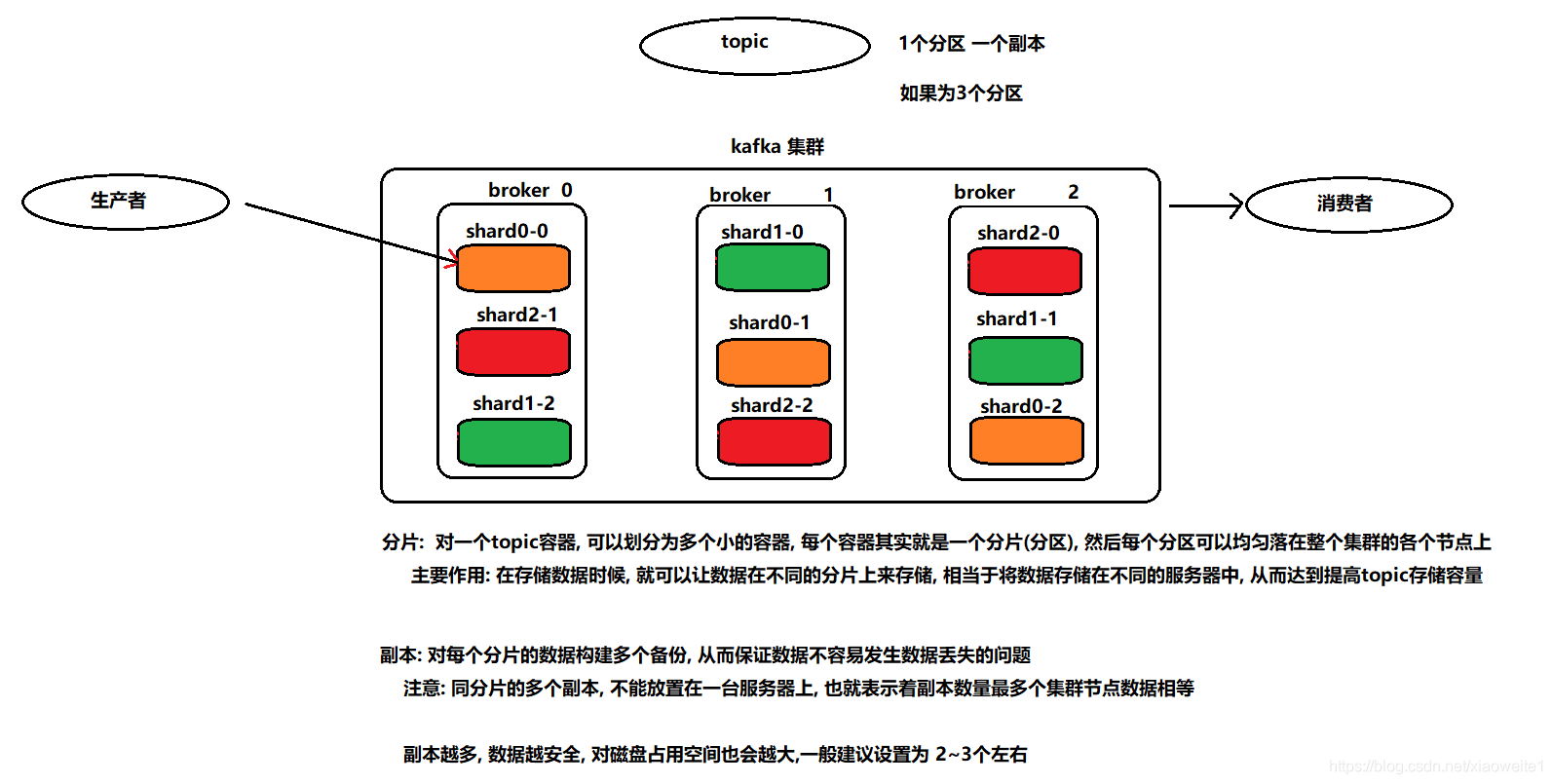
 Kafka的分片机制旨在解决大数据量存储问题,通过将数据分散在多台服务器上确保容量。数据存储位置由分片算法决定,确保均衡分布。而副本机制则保证了数据的高可用性,通过在不同服务器间复制数据,防止数据丢失,实现容灾容错。这两个机制共同提升了Kafka集群的稳定性和可靠性。
Kafka的分片机制旨在解决大数据量存储问题,通过将数据分散在多台服务器上确保容量。数据存储位置由分片算法决定,确保均衡分布。而副本机制则保证了数据的高可用性,通过在不同服务器间复制数据,防止数据丢失,实现容灾容错。这两个机制共同提升了Kafka集群的稳定性和可靠性。
kafka的分片,是为了解决单台服务器容量有限问题。当数据量比较大时,一台服务器放不下,将数据分成多个片,存储在多个服务器上。每个服务器上的数据叫做一个片。
问题:分片后,数据存储在哪个片区怎么确定?
Kafka的副本机制,解决存储数据的高可用问题,一台服务器上存储数据,有丢失的风险。多拷贝几份数据到不同的服务器,可以达到容灾、容错的目的。
 3285
3285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























