



一、前言
之前开源了一篇爬取携程景区数据的文章,我看还挺火的,也有不少人找我问景区评论数据怎么爬,那就直接写篇文章记录以下携程景区数据爬取吧。
二、爬虫
1.打开携程网,找到某个景区点击跳转到详情页面https://you.ctrip.com/sight/harbin151/20017.html?scene=online
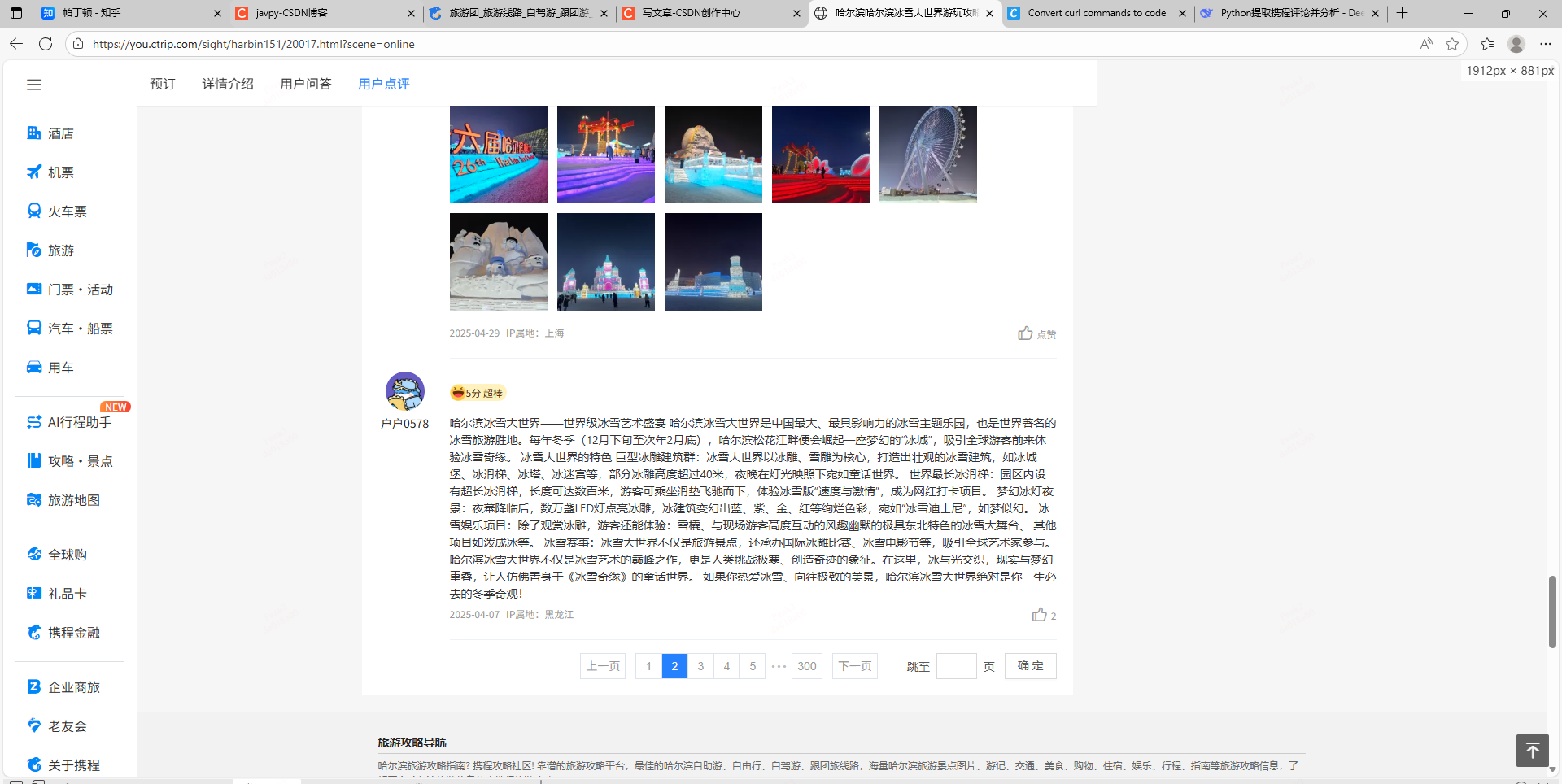
2.按F12打开开发者工具,然后点击下评论下一页来监听是否有网络请求更新,如果没有那就看页面地址栏是否发生变化,前者是动态更新(post请求,通过调后端接口完成数据更新),后者是静态更新(get请求,通过html页面更新数据)。
通过搜索评论内容定位到评论数据是通过调getCommentCollapseList接口返回的。
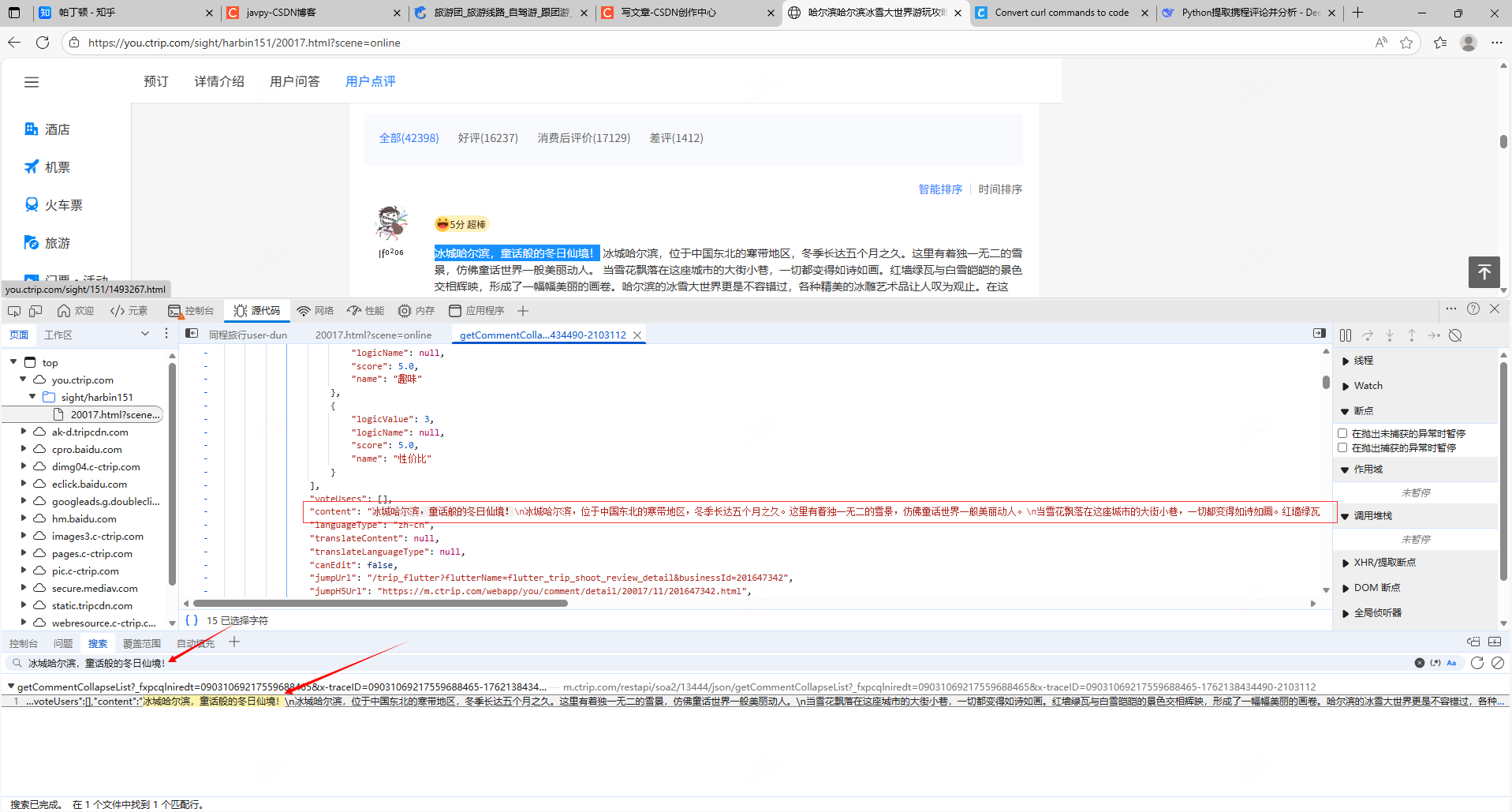
3.那么我们现在已经知道数据在哪个接口中,接下来就需要在本地模拟调用这个请求即可,这里我是用Python的requests库实现,你问我怎么知道调这个请求需要携带这些参数?
那我告诉你一个快速又便捷的方法就是右键复制这个请求的curl(bash)去拿到https://curlconverter.com/网站粘贴,就会自动输出完整的调用请求代码(好用记得点个赞哦)
import requests
cookies = {
'GUID': '09031069217559688465',
'MKT_CKID': '1751274744072.9fx30.ncpi',
'_RSG': 'Ce4EW5dni37P3spnPcTGtA',
'_RDG': '281fac73a494fd20293dac96d16828aefe',
'_RGUID': '70ecc671-6038-4a0c-add0-766671cf60d9',
'_ga': 'GA1.1.1991158589.1751274745',
'nfes_isSupportWebP': '1',
'ibulocale': 'zh_cn',
'cookiePricesDisplayed': 'CNY',
'_abtest_userid': '1a3ec536-4b47-4de6-a67e-b8a48f5801d2',
'Corp_ResLang': 'zh-cn',
'_bfaStatusPVSend': '1',
'UBT_VID': '1752483344037.225tvy',
'_bfaStatus': 'success',
'_RF1': '123.177.53.139',
'intl_ht1': 'h4=2_77366892,1_125617009,1_1452207,1_37887757,1_1216725,1_451914',
'Session': 'smartlinkcode=U1535&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=',
'cticket': 'CE25F87925CE3A24D87B4B49552AAC319AB05837BC4B4CDE3128CFD8599DA2A0',
'login_type': '0',
'login_uid': '1ABDFAF92F8F787FC7FF8F25D126F368',
'DUID': 'u=C9FDAB4B4979E966AA8F2399E969E0E3&v=0',
'IsNonUser': 'F',
'AHeadUserInfo': 'VipGrade=10&VipGradeName=%BB%C6%BD%F0%B9%F3%B1%F6&UserName=&NoReadMessageCount=0',
'_udl': '708D70C2B179E2F91CC5ED1C2CCE362D',
'MKT_Pagesource': 'PC',
'FlightIntl': 'Search=[%22DLC|%E5%A4%A7%E8%BF%9E(DLC)|6|DLC|480%22%2C%22LYG|%E8%BF%9E%E4%BA%91%E6%B8%AF(LYG)|353|LYG|480%22%2C%222025-10-30%22]',
'Hm_lvt_a8d6737197d542432f4ff4abc6e06384': '1761630082,1761716901,1761893019,1762136109',
'HMACCOUNT': '9D2E35FEF918515F',
'Union': 'OUID=&AllianceID=4902&SID=22921635&SourceID=&createtime=1762136110&Expires=1762740910248',
'MKT_OrderClick': 'ASID=490222921635&AID=4902&CSID=22921635&OUID=&CT=1762136110250&CURL=https%3A%2F%2Fwww.ctrip.com%2F%3Fallianceid%3D4902%26sid%3D22921635%26msclkid%3D7eff9c7d55f11abed3aaf57545dbc683%26keywordid%3D82533150989423&VAL={"pc_vid":"1752483344037.225tvy"}',
'Hm_lpvt_a8d6737197d542432f4ff4abc6e06384': '1762136115',
'ibulanguage': 'ZH-CN',
'_ga_5DVRDQD429': 'GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h618444427',
'_ga_B77BES1Z8Z': 'GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h0',
'_ga_9BZF483VNQ': 'GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h0',
'StartCity_Pkg': 'PkgStartCity=6',
'_ubtstatus': '%7B%22vid%22%3A%221752483344037.225tvy%22%2C%22sid%22%3A57%2C%22pvid%22%3A11%2C%22pid%22%3A%22290510%22%7D',
'_bfa': '1.1752483344037.225tvy.1.1762136930197.1762138428814.57.13.290510',
'_jzqco': '%7C%7C%7C%7C1762136110630%7C1.2042136291.1752545646178.1762136437240.1762138429916.1762136437240.1762138429916.undefined.0.0.363.363',
}
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json',
'cookieorigin': 'https://you.ctrip.com',
'origin': 'https://you.ctrip.com',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://you.ctrip.com/',
'sec-ch-ua': '"Chromium";v="142", "Microsoft Edge";v="142", "Not_A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0',
'x-ctx-currency': 'CNY',
'x-ctx-locale': 'zh-CN',
'x-ctx-ubt-pageid': '290510',
'x-ctx-ubt-pvid': '13',
'x-ctx-ubt-sid': '57',
'x-ctx-ubt-vid': '1752483344037.225tvy',
# 'cookie': 'GUID=09031069217559688465; MKT_CKID=1751274744072.9fx30.ncpi; _RSG=Ce4EW5dni37P3spnPcTGtA; _RDG=281fac73a494fd20293dac96d16828aefe; _RGUID=70ecc671-6038-4a0c-add0-766671cf60d9; _ga=GA1.1.1991158589.1751274745; nfes_isSupportWebP=1; ibulocale=zh_cn; cookiePricesDisplayed=CNY; _abtest_userid=1a3ec536-4b47-4de6-a67e-b8a48f5801d2; Corp_ResLang=zh-cn; _bfaStatusPVSend=1; UBT_VID=1752483344037.225tvy; _bfaStatus=success; _RF1=123.177.53.139; intl_ht1=h4=2_77366892,1_125617009,1_1452207,1_37887757,1_1216725,1_451914; Session=smartlinkcode=U1535&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=; cticket=CE25F87925CE3A24D87B4B49552AAC319AB05837BC4B4CDE3128CFD8599DA2A0; login_type=0; login_uid=1ABDFAF92F8F787FC7FF8F25D126F368; DUID=u=C9FDAB4B4979E966AA8F2399E969E0E3&v=0; IsNonUser=F; AHeadUserInfo=VipGrade=10&VipGradeName=%BB%C6%BD%F0%B9%F3%B1%F6&UserName=&NoReadMessageCount=0; _udl=708D70C2B179E2F91CC5ED1C2CCE362D; MKT_Pagesource=PC; FlightIntl=Search=[%22DLC|%E5%A4%A7%E8%BF%9E(DLC)|6|DLC|480%22%2C%22LYG|%E8%BF%9E%E4%BA%91%E6%B8%AF(LYG)|353|LYG|480%22%2C%222025-10-30%22]; Hm_lvt_a8d6737197d542432f4ff4abc6e06384=1761630082,1761716901,1761893019,1762136109; HMACCOUNT=9D2E35FEF918515F; Union=OUID=&AllianceID=4902&SID=22921635&SourceID=&createtime=1762136110&Expires=1762740910248; MKT_OrderClick=ASID=490222921635&AID=4902&CSID=22921635&OUID=&CT=1762136110250&CURL=https%3A%2F%2Fwww.ctrip.com%2F%3Fallianceid%3D4902%26sid%3D22921635%26msclkid%3D7eff9c7d55f11abed3aaf57545dbc683%26keywordid%3D82533150989423&VAL={"pc_vid":"1752483344037.225tvy"}; Hm_lpvt_a8d6737197d542432f4ff4abc6e06384=1762136115; ibulanguage=ZH-CN; _ga_5DVRDQD429=GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h618444427; _ga_B77BES1Z8Z=GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h0; _ga_9BZF483VNQ=GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h0; StartCity_Pkg=PkgStartCity=6; _ubtstatus=%7B%22vid%22%3A%221752483344037.225tvy%22%2C%22sid%22%3A57%2C%22pvid%22%3A11%2C%22pid%22%3A%22290510%22%7D; _bfa=1.1752483344037.225tvy.1.1762136930197.1762138428814.57.13.290510; _jzqco=%7C%7C%7C%7C1762136110630%7C1.2042136291.1752545646178.1762136437240.1762138429916.1762136437240.1762138429916.undefined.0.0.363.363',
}
params = {
'_fxpcqlniredt': '09031069217559688465',
'x-traceID': '09031069217559688465-1762138434490-2103112',
}
json_data = {
'arg': {
'channelType': 2,
'collapseType': 0,
'commentTagId': 0,
'pageIndex': 1,
'pageSize': 10,
'poiId': 80633,
'sourceType': 1,
'sortType': 3,
'starType': 0,
},
'head': {
'cid': '09031069217559688465',
'ctok': '',
'cver': '1.0',
'lang': '01',
'sid': '8888',
'syscode': '09',
'auth': '',
'xsid': '',
'extension': [],
},
}
response = requests.post(
'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList',
params=params,
cookies=cookies,
headers=headers,
json=json_data,
)
print(response.json())4.打印数据看看评论内容是否在返回结果中。
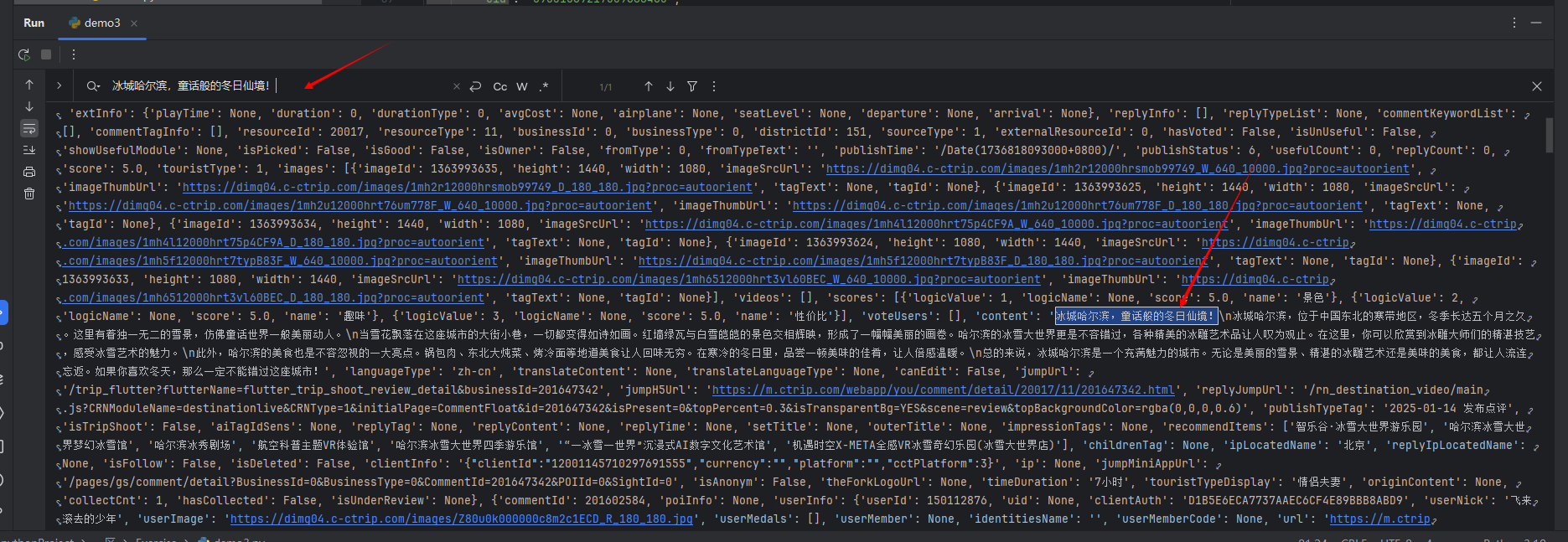
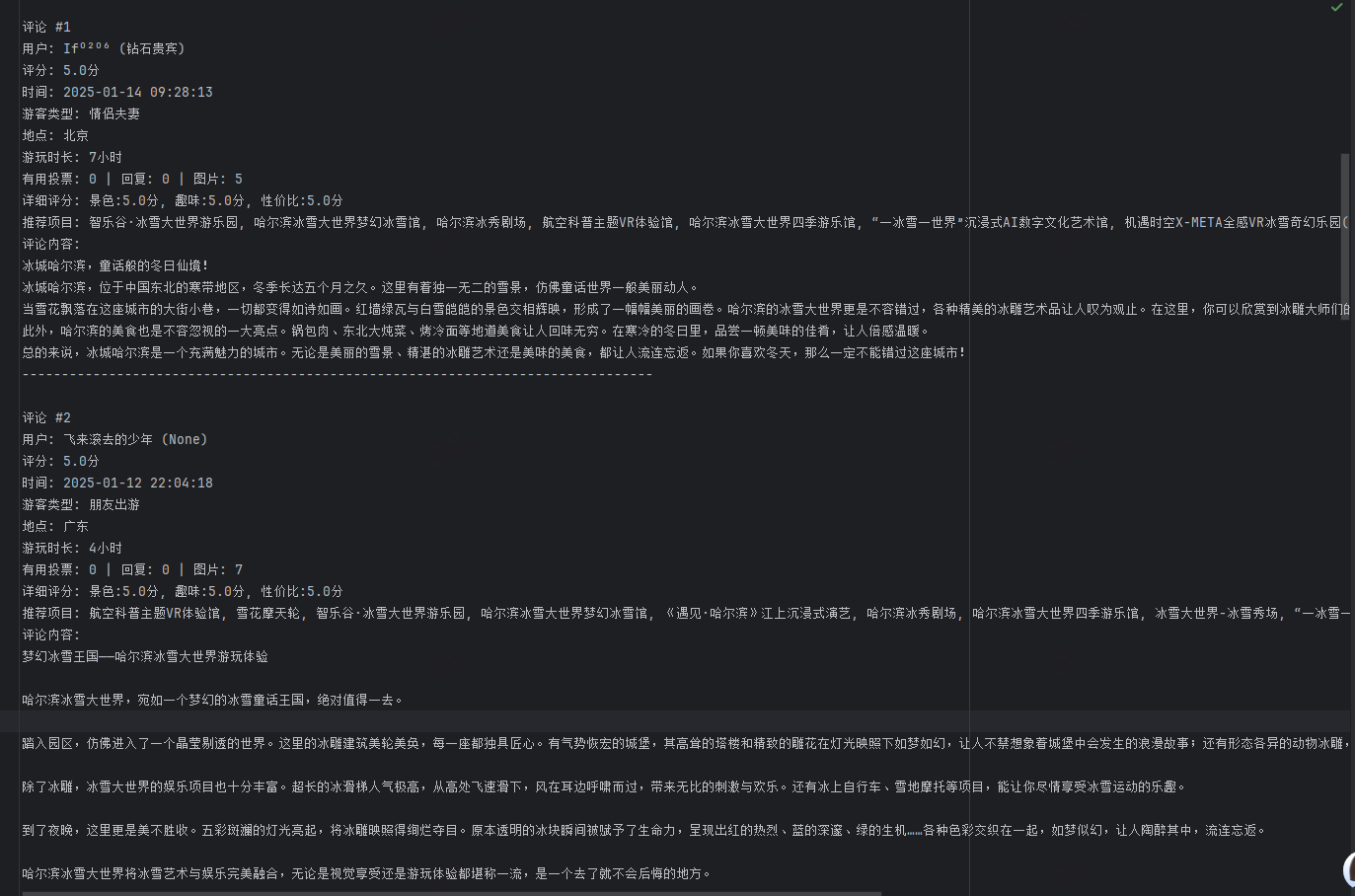
5.可以看到返回结果中有我们想要的数据,那接下来就是写数据分析和存储代码了,这里我直接给出代码和结果:
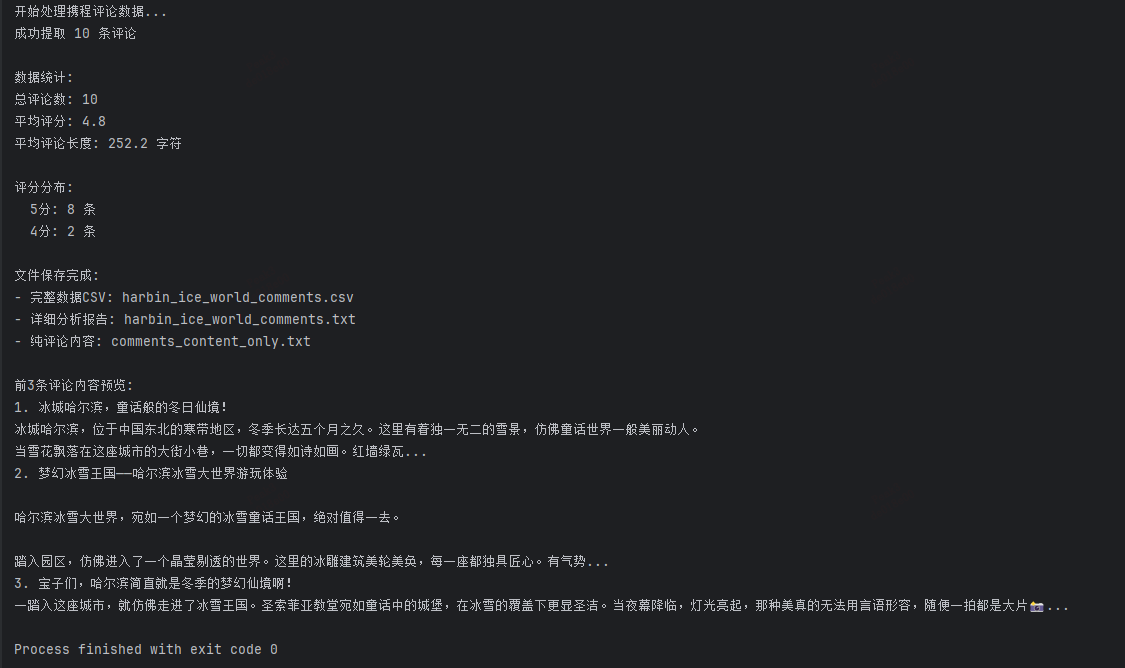
分析以及存储代码:
import requests
def crawlComment():
cookies = {
'GUID': '09031069217559688465',
'MKT_CKID': '1751274744072.9fx30.ncpi',
'_RSG': 'Ce4EW5dni37P3spnPcTGtA',
'_RDG': '281fac73a494fd20293dac96d16828aefe',
'_RGUID': '70ecc671-6038-4a0c-add0-766671cf60d9',
'_ga': 'GA1.1.1991158589.1751274745',
'nfes_isSupportWebP': '1',
'ibulocale': 'zh_cn',
'cookiePricesDisplayed': 'CNY',
'_abtest_userid': '1a3ec536-4b47-4de6-a67e-b8a48f5801d2',
'Corp_ResLang': 'zh-cn',
'_bfaStatusPVSend': '1',
'UBT_VID': '1752483344037.225tvy',
'_bfaStatus': 'success',
'_RF1': '123.177.53.139',
'intl_ht1': 'h4=2_77366892,1_125617009,1_1452207,1_37887757,1_1216725,1_451914',
'Session': 'smartlinkcode=U1535&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=',
'cticket': 'CE25F87925CE3A24D87B4B49552AAC319AB05837BC4B4CDE3128CFD8599DA2A0',
'login_type': '0',
'login_uid': '1ABDFAF92F8F787FC7FF8F25D126F368',
'DUID': 'u=C9FDAB4B4979E966AA8F2399E969E0E3&v=0',
'IsNonUser': 'F',
'AHeadUserInfo': 'VipGrade=10&VipGradeName=%BB%C6%BD%F0%B9%F3%B1%F6&UserName=&NoReadMessageCount=0',
'_udl': '708D70C2B179E2F91CC5ED1C2CCE362D',
'MKT_Pagesource': 'PC',
'FlightIntl': 'Search=[%22DLC|%E5%A4%A7%E8%BF%9E(DLC)|6|DLC|480%22%2C%22LYG|%E8%BF%9E%E4%BA%91%E6%B8%AF(LYG)|353|LYG|480%22%2C%222025-10-30%22]',
'Hm_lvt_a8d6737197d542432f4ff4abc6e06384': '1761630082,1761716901,1761893019,1762136109',
'HMACCOUNT': '9D2E35FEF918515F',
'Union': 'OUID=&AllianceID=4902&SID=22921635&SourceID=&createtime=1762136110&Expires=1762740910248',
'MKT_OrderClick': 'ASID=490222921635&AID=4902&CSID=22921635&OUID=&CT=1762136110250&CURL=https%3A%2F%2Fwww.ctrip.com%2F%3Fallianceid%3D4902%26sid%3D22921635%26msclkid%3D7eff9c7d55f11abed3aaf57545dbc683%26keywordid%3D82533150989423&VAL={"pc_vid":"1752483344037.225tvy"}',
'Hm_lpvt_a8d6737197d542432f4ff4abc6e06384': '1762136115',
'ibulanguage': 'ZH-CN',
'_ga_5DVRDQD429': 'GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h618444427',
'_ga_B77BES1Z8Z': 'GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h0',
'_ga_9BZF483VNQ': 'GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h0',
'StartCity_Pkg': 'PkgStartCity=6',
'_ubtstatus': '%7B%22vid%22%3A%221752483344037.225tvy%22%2C%22sid%22%3A57%2C%22pvid%22%3A11%2C%22pid%22%3A%22290510%22%7D',
'_bfa': '1.1752483344037.225tvy.1.1762136930197.1762138428814.57.13.290510',
'_jzqco': '%7C%7C%7C%7C1762136110630%7C1.2042136291.1752545646178.1762136437240.1762138429916.1762136437240.1762138429916.undefined.0.0.363.363',
}
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json',
'cookieorigin': 'https://you.ctrip.com',
'origin': 'https://you.ctrip.com',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://you.ctrip.com/',
'sec-ch-ua': '"Chromium";v="142", "Microsoft Edge";v="142", "Not_A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0',
'x-ctx-currency': 'CNY',
'x-ctx-locale': 'zh-CN',
'x-ctx-ubt-pageid': '290510',
'x-ctx-ubt-pvid': '13',
'x-ctx-ubt-sid': '57',
'x-ctx-ubt-vid': '1752483344037.225tvy',
# 'cookie': 'GUID=09031069217559688465; MKT_CKID=1751274744072.9fx30.ncpi; _RSG=Ce4EW5dni37P3spnPcTGtA; _RDG=281fac73a494fd20293dac96d16828aefe; _RGUID=70ecc671-6038-4a0c-add0-766671cf60d9; _ga=GA1.1.1991158589.1751274745; nfes_isSupportWebP=1; ibulocale=zh_cn; cookiePricesDisplayed=CNY; _abtest_userid=1a3ec536-4b47-4de6-a67e-b8a48f5801d2; Corp_ResLang=zh-cn; _bfaStatusPVSend=1; UBT_VID=1752483344037.225tvy; _bfaStatus=success; _RF1=123.177.53.139; intl_ht1=h4=2_77366892,1_125617009,1_1452207,1_37887757,1_1216725,1_451914; Session=smartlinkcode=U1535&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=; cticket=CE25F87925CE3A24D87B4B49552AAC319AB05837BC4B4CDE3128CFD8599DA2A0; login_type=0; login_uid=1ABDFAF92F8F787FC7FF8F25D126F368; DUID=u=C9FDAB4B4979E966AA8F2399E969E0E3&v=0; IsNonUser=F; AHeadUserInfo=VipGrade=10&VipGradeName=%BB%C6%BD%F0%B9%F3%B1%F6&UserName=&NoReadMessageCount=0; _udl=708D70C2B179E2F91CC5ED1C2CCE362D; MKT_Pagesource=PC; FlightIntl=Search=[%22DLC|%E5%A4%A7%E8%BF%9E(DLC)|6|DLC|480%22%2C%22LYG|%E8%BF%9E%E4%BA%91%E6%B8%AF(LYG)|353|LYG|480%22%2C%222025-10-30%22]; Hm_lvt_a8d6737197d542432f4ff4abc6e06384=1761630082,1761716901,1761893019,1762136109; HMACCOUNT=9D2E35FEF918515F; Union=OUID=&AllianceID=4902&SID=22921635&SourceID=&createtime=1762136110&Expires=1762740910248; MKT_OrderClick=ASID=490222921635&AID=4902&CSID=22921635&OUID=&CT=1762136110250&CURL=https%3A%2F%2Fwww.ctrip.com%2F%3Fallianceid%3D4902%26sid%3D22921635%26msclkid%3D7eff9c7d55f11abed3aaf57545dbc683%26keywordid%3D82533150989423&VAL={"pc_vid":"1752483344037.225tvy"}; Hm_lpvt_a8d6737197d542432f4ff4abc6e06384=1762136115; ibulanguage=ZH-CN; _ga_5DVRDQD429=GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h618444427; _ga_B77BES1Z8Z=GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h0; _ga_9BZF483VNQ=GS2.1.s1762136110$o33$g1$t1762136116$j54$l0$h0; StartCity_Pkg=PkgStartCity=6; _ubtstatus=%7B%22vid%22%3A%221752483344037.225tvy%22%2C%22sid%22%3A57%2C%22pvid%22%3A11%2C%22pid%22%3A%22290510%22%7D; _bfa=1.1752483344037.225tvy.1.1762136930197.1762138428814.57.13.290510; _jzqco=%7C%7C%7C%7C1762136110630%7C1.2042136291.1752545646178.1762136437240.1762138429916.1762136437240.1762138429916.undefined.0.0.363.363',
}
params = {
'_fxpcqlniredt': '09031069217559688465',
'x-traceID': '09031069217559688465-1762138434490-2103112',
}
json_data = {
'arg': {
'channelType': 2,
'collapseType': 0,
'commentTagId': 0,
'pageIndex': 2,
'pageSize': 10,
'poiId': 80633,
'sourceType': 1,
'sortType': 3,
'starType': 0,
},
'head': {
'cid': '09031069217559688465',
'ctok': '',
'cver': '1.0',
'lang': '01',
'sid': '8888',
'syscode': '09',
'auth': '',
'xsid': '',
'extension': [],
},
}
response = requests.post(
'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList',
params=params,
cookies=cookies,
headers=headers,
json=json_data,
)
return response.json()
import json
import pandas as pd
from datetime import datetime
def extract_comments_from_json(json_data):
"""
从携程API返回的JSON数据中提取评论信息
"""
comments = []
# 检查数据结构
if 'result' in json_data and 'items' in json_data['result']:
items = json_data['result']['items']
for item in items:
comment_info = {
'comment_id': item.get('commentId'),
'user_nick': item.get('userInfo', {}).get('userNick', ''),
'user_member': item.get('userInfo', {}).get('userMember', ''),
'score': item.get('score', 0),
'content': item.get('content', ''),
'publish_time': format_timestamp(item.get('publishTime', '')),
'tourist_type': get_tourist_type_display(item.get('touristType', 0)),
'ip_location': item.get('ipLocatedName', ''),
'time_duration': item.get('timeDuration', ''),
'useful_count': item.get('usefulCount', 0),
'reply_count': item.get('replyCount', 0),
'image_count': len(item.get('images', [])),
'recommend_items': item.get('recommendItems', []),
'scores': get_detailed_scores(item.get('scores', []))
}
comments.append(comment_info)
return comments
def format_timestamp(timestamp_str):
"""
格式化时间戳
"""
if not timestamp_str:
return ''
try:
# 处理 /Date(1742347091000+0800)/ 格式的时间戳
if timestamp_str.startswith('/Date('):
timestamp_str = timestamp_str.replace('/Date(', '').replace(')/', '')
# 提取毫秒时间戳部分
millis = int(timestamp_str.split('+')[0])
dt = datetime.fromtimestamp(millis / 1000)
return dt.strftime('%Y-%m-%d %H:%M:%S')
except:
pass
return timestamp_str
def get_tourist_type_display(tourist_type):
"""
获取游客类型显示文本
"""
tourist_type_map = {
0: "个人游",
1: "情侣夫妻",
2: "家庭亲子",
3: "朋友出游",
4: "商务出差",
5: "独自旅行"
}
return tourist_type_map.get(tourist_type, "其他")
def get_detailed_scores(scores_list):
"""
获取详细的评分信息
"""
scores_detail = {}
for score_item in scores_list:
name = score_item.get('name', '')
score = score_item.get('score', 0)
if name:
scores_detail[name] = score
return scores_detail
def analyze_comments_data(comments):
"""
分析评论数据,生成统计信息
"""
if not comments:
return {}
total_comments = len(comments)
avg_score = sum(comment['score'] for comment in comments) / total_comments
# 统计评分分布
score_distribution = {}
for comment in comments:
score = comment['score']
score_range = f"{int(score)}分"
score_distribution[score_range] = score_distribution.get(score_range, 0) + 1
# 统计游客类型分布
tourist_type_dist = {}
for comment in comments:
tourist_type = comment['tourist_type']
tourist_type_dist[tourist_type] = tourist_type_dist.get(tourist_type, 0) + 1
# 统计地区分布
location_dist = {}
for comment in comments:
location = comment['ip_location'] or '未知'
location_dist[location] = location_dist.get(location, 0) + 1
# 计算平均评论长度
avg_content_length = sum(len(comment['content']) for comment in comments) / total_comments
analysis = {
'total_comments': total_comments,
'average_score': round(avg_score, 2),
'score_distribution': score_distribution,
'tourist_type_distribution': tourist_type_dist,
'location_distribution': location_dist,
'average_content_length': round(avg_content_length, 2),
'total_images': sum(comment['image_count'] for comment in comments),
'total_useful_votes': sum(comment['useful_count'] for comment in comments)
}
return analysis
def save_comments_to_files(comments, analysis, base_filename='harbin_ice_world_comments'):
"""
将评论数据保存到多个文件
"""
# 保存为CSV文件
df = pd.DataFrame(comments)
csv_filename = f"{base_filename}.csv"
df.to_csv(csv_filename, index=False, encoding='utf-8-sig')
# 保存为文本文件
txt_filename = f"{base_filename}.txt"
with open(txt_filename, 'w', encoding='utf-8') as f:
f.write("哈尔滨冰雪大世界用户评论分析\n")
f.write("=" * 60 + "\n\n")
# 写入统计信息
f.write("数据统计:\n")
f.write(f"总评论数: {analysis['total_comments']}\n")
f.write(f"平均评分: {analysis['average_score']}\n")
f.write(f"平均评论长度: {analysis['average_content_length']} 字符\n")
f.write(f"总图片数: {analysis['total_images']}\n")
f.write(f"总有用投票数: {analysis['total_useful_votes']}\n\n")
f.write("评分分布:\n")
for score_range, count in analysis['score_distribution'].items():
f.write(f" {score_range}: {count} 条\n")
f.write("\n游客类型分布:\n")
for tourist_type, count in analysis['tourist_type_distribution'].items():
f.write(f" {tourist_type}: {count} 条\n")
f.write("\n地区分布:\n")
for location, count in analysis['location_distribution'].items():
f.write(f" {location}: {count} 条\n")
f.write("\n" + "=" * 60 + "\n")
f.write("详细评论内容:\n\n")
# 写入详细评论
for i, comment in enumerate(comments, 1):
f.write(f"评论 #{i}\n")
f.write(f"用户: {comment['user_nick']} ({comment['user_member']})\n")
f.write(f"评分: {comment['score']}分\n")
f.write(f"时间: {comment['publish_time']}\n")
f.write(f"游客类型: {comment['tourist_type']}\n")
f.write(f"地点: {comment['ip_location']}\n")
f.write(f"游玩时长: {comment['time_duration']}\n")
f.write(
f"有用投票: {comment['useful_count']} | 回复: {comment['reply_count']} | 图片: {comment['image_count']}\n")
# 详细评分
if comment['scores']:
f.write("详细评分: ")
scores_str = ", ".join([f"{k}:{v}分" for k, v in comment['scores'].items()])
f.write(scores_str + "\n")
# 推荐项目
if comment['recommend_items']:
f.write(f"推荐项目: {', '.join(comment['recommend_items'])}\n")
f.write(f"评论内容:\n{comment['content']}\n")
f.write("-" * 80 + "\n\n")
return csv_filename, txt_filename
def extract_only_comments_content(comments, filename='comments_content_only.txt'):
"""
仅提取评论内容,保存到单独文件
"""
with open(filename, 'w', encoding='utf-8') as f:
f.write("哈尔滨冰雪大世界评论内容汇总\n")
f.write("=" * 50 + "\n\n")
for i, comment in enumerate(comments, 1):
f.write(f"【评论 {i}】\n")
f.write(f"{comment['content']}\n")
f.write("-" * 50 + "\n\n")
return filename
# 主处理函数
def process_ctrip_comments(json_data):
"""
处理携程评论数据的主函数
"""
print("开始处理携程评论数据...")
# 提取评论
comments = extract_comments_from_json(json_data)
print(f"成功提取 {len(comments)} 条评论")
if not comments:
print("未找到评论数据")
return
# 分析数据
analysis = analyze_comments_data(comments)
# 打印简要统计
print(f"\n数据统计:")
print(f"总评论数: {analysis['total_comments']}")
print(f"平均评分: {analysis['average_score']}")
print(f"平均评论长度: {analysis['average_content_length']} 字符")
print(f"\n评分分布:")
for score_range, count in analysis['score_distribution'].items():
print(f" {score_range}: {count} 条")
# 保存文件
csv_file, txt_file = save_comments_to_files(comments, analysis)
content_only_file = extract_only_comments_content(comments)
print(f"\n文件保存完成:")
print(f"- 完整数据CSV: {csv_file}")
print(f"- 详细分析报告: {txt_file}")
print(f"- 纯评论内容: {content_only_file}")
# 显示前几条评论内容
print(f"\n前3条评论内容预览:")
for i, comment in enumerate(comments[:3], 1):
print(f"{i}. {comment['content'][:100]}...")
return comments, analysis
# 使用示例
if __name__ == "__main__":
# 爬取数据
json_data = crawlComment()
# 处理数据
comments, analysis = process_ctrip_comments(json_data)
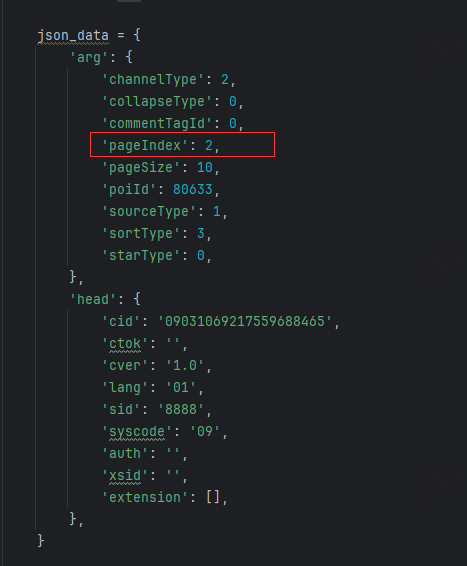
6.那有聪明的小伙伴又问了,主播主播,这怎么就10个评论呀,因为一个页面就只有10条数据啊,想要爬取其他页的数据可以修改请求入参,也就是json_data,json_data中有个参数叫pageIndex参数,可选范围是1~300,也就是说一个景区你能爬3000条评论数据。
三、总结
开源代码纯属闲的没事干,如果帮到你了给个赞就行

















 4252
4252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









