



一、前言
本文提供所有爬取思路和主要代码。
酒店名称、酒店详细数据:房间套餐价格、设施、标签等数据均可以根据返回数据进行分析采集,如有需求可以联系我定制。
二、爬取酒店搜索结果列表
1.艺龙酒店搜索界面如图所示,输入城市名称、日期、酒店关键字等数据后即可搜索相关酒店。
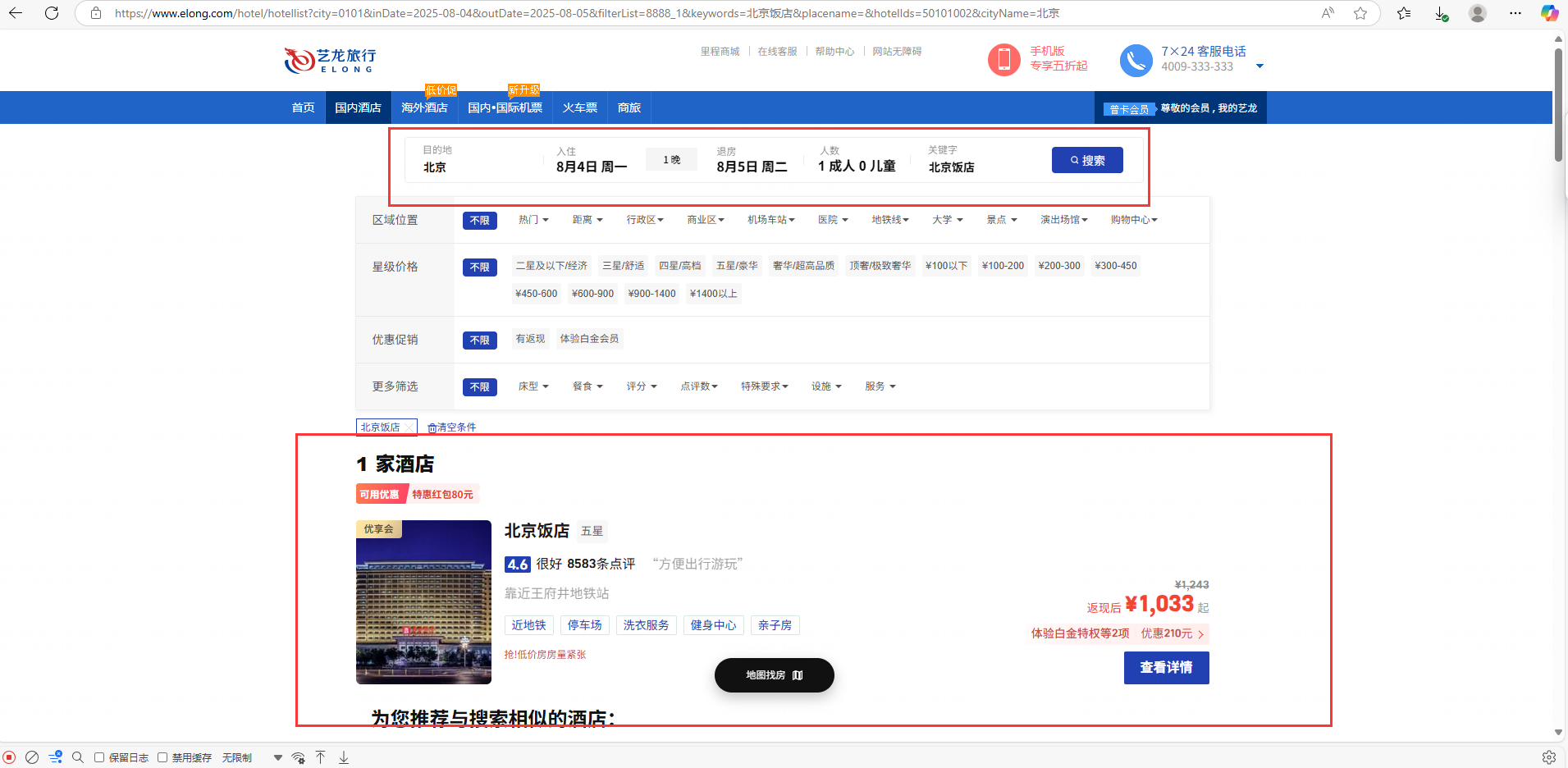
2.通过查看网络请求可以发现,搜索请求调用了名为list的接口。
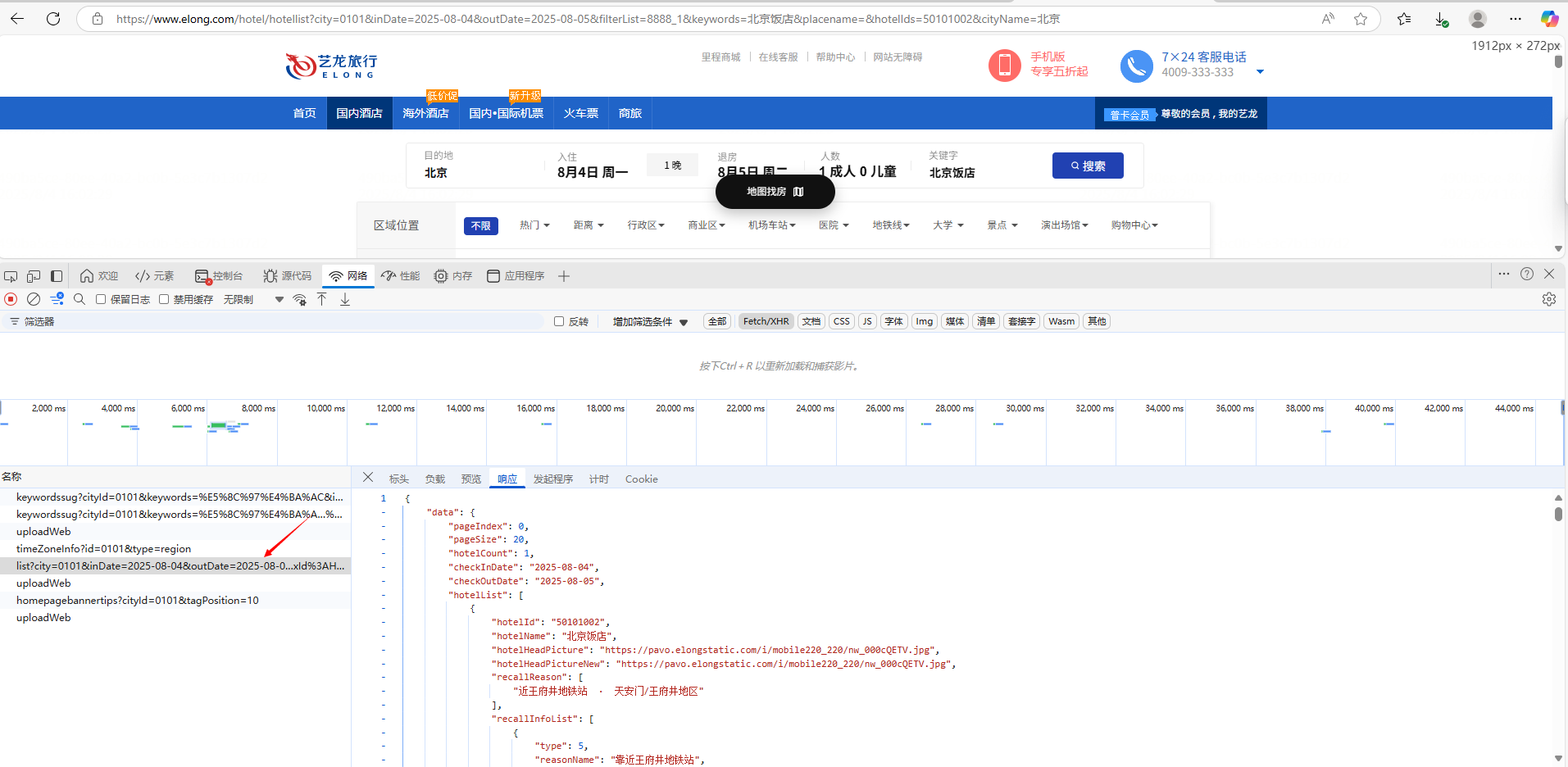 3.那我们需要实现在本地去请求这个接口拿到酒店数据,使用Python requests库实现,可以看到如下代码中携带了很多入参,这些参数都是必须的(我已经筛选过了),SessionToken为登录后的账号凭证,无法在本地模拟生成,只能手动去页面复制出来。
3.那我们需要实现在本地去请求这个接口拿到酒店数据,使用Python requests库实现,可以看到如下代码中携带了很多入参,这些参数都是必须的(我已经筛选过了),SessionToken为登录后的账号凭证,无法在本地模拟生成,只能手动去页面复制出来。
H5CookieId和deviceid是一样的(单纯的加密参数)和user-dun(加密过程与param参数有关)为加密参数,可以上JS逆向实现模拟本地生成,userdun生成代码太多了,这里我就不放出来了。
import requests
cookies = {
'H5CookieId': '44ebd0bb-61a3-4109-aada-80f1af3e588e',
'SessionToken': '3b9a9220-1691-4d7a-9e6b-25eb398ddb9e622'
}
headers = {
'appfrom': '15',
'deviceid': '44ebd0bb-61a3-4109-aada-80f1af3e588e',
'tmapi-client': 'epc',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0',
'user-dun': 'x7NxxxxxIHJbl2jxIHH1Pfc1P8LpzxCIx7CCI7QqhqCOWaKFa5ax8pWLXNG+X/5Ih25recNIxx7PkkVgDm+zlvTQoWOklv3QsEfbZbXflv9QuPXqO9YhjLXq+4GvcmuFq920cmuFq93Qjh0ruWdEorYbAv+zo8eOjLnUl8TRlQqQlWlhoW33mtar4OlUOEVgm1xZGu1vEQqKoXPAcm8AjmRThmTDFQ7Esxq4Rhj8oBvYR/CUsd9aCj8UXN+BGD1QbFjRrWlQl61b1hBygNZQMmLwFxovXLbYlSlNwQ/yFR4T7K60qR0QaWg9f7qia8t8dsqVa8wwOBHXRm8MCQ14lLVXLri22muqOZ9bZZJXuvlh1hHmdkl3mtTZ+rER/QA/OHoqccl611qEk8E+de3bnjarFAlcrbTFle19ccHqsA87tW+2dU9tqvcWGd1njkEec9BSt7HmMZT7g1El41KGO/uFU/a+1kupv/+ndOzWbLbCPBvtS9BTmIpv28sK4j2Ac1kXz6wHJJrGkoo+VA/1zxlFNZ0szRVr9k/lu+yoX9b9m1iKNEpZAsZy3EMjm24RgZEX3HH+7nbim/yGZnLbkSekNZvv6n0A/1ANqGnA/4EWSuFPvu5mFGuAArz1SsaMkGeSkxlMJQIEj6Xtqju3/+BvfmvbOW1vIxs9a7==',
}
params = {
'city': '0101',
'inDate': '2025-08-05',
'outDate': '2025-08-06',
'filterList': '8888_1',
'keywords': '北京饭店',
'placename': '',
'pageIndex': '0',
'pageSize': '20',
'adultsNumber': '1',
'childrenAges': '',
}
response = requests.get('https://www.elong.com/tapi/v2/list', params=params, cookies=cookies, headers=headers)
print(response.text)
hotelList = response.json().get("data", {}).get("hotelList", [])
for hotel in hotelList:
hotel_id = hotel.get("hotelId")
hotel_name = hotel.get("hotelName")
print(hotel_id, hotel_name)
picTopTags = hotel.get("picTopTags", [])
tagName_list = []
if picTopTags:
for picTopTag in picTopTags:
tagName = picTopTag.get("tagName", "")
tagName_list.append(tagName)
print(tagName_list)
H5CookieId获取代码,经过多次测试,发现其有效期1小时左右
(注意:电脑必须有最新版的Google Chrome浏览器,不然代码跑不起来!):
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import time
from datetime import datetime
class H5CookieId:
def __init__(self):
self.chromedriver_path = "Goole浏览器驱动器存放路径"
def get_specific_h5_cookie_id(self):
# 设置Chrome浏览器选项
chrome_options = Options()
chrome_options.add_argument("--headless") # 注释掉以便观察浏览器行为
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
# 指定ChromeDriver路径
service = Service(executable_path=self.chromedriver_path)
# 初始化浏览器
driver = webdriver.Chrome(service=service, options=chrome_options)
try:
# 访问目标网站
driver.get("https://www.elong.com/")
# 等待页面加载完成(可根据实际情况调整等待时间)
time.sleep(1) # 延长等待时间确保所有cookie设置完成
# 获取所有cookies
cookies = driver.get_cookies()
# 查找特定条件的H5CookieId
target_cookie = None
for cookie in cookies:
if cookie['name'] == 'H5CookieId' and cookie.get('domain') == '.elong.com' and 'expiry' in cookie:
# 将Unix时间戳转换为可读格式
expiry_date = datetime.fromtimestamp(cookie['expiry']).strftime('%Y-%m-%dT%H:%M:%S.%fZ')
target_cookie = {
'value': cookie['value'],
'expiry': expiry_date,
}
break
if target_cookie:
return target_cookie
else:
print("未找到符合条件的H5CookieId")
# 打印所有H5CookieId供调试
print("\n所有H5CookieId信息:")
for cookie in cookies:
if cookie['name'] == 'H5CookieId':
expiry = 'Session' if 'expiry' not in cookie else datetime.fromtimestamp(cookie['expiry']).strftime(
'%Y-%m-%dT%H:%M:%S.%fZ')
print(f"值: {cookie['value']}, 过期时间: {expiry}, Domain: {cookie.get('domain', 'N/A')}")
return None
except Exception as e:
print(f"获取cookie时出错: {e}")
return None
finally:
# 关闭浏览器
# input("按回车键关闭浏览器...") # 暂停以便查看浏览器状态
driver.quit()
return target_cookie
# 调用函数
if __name__ == "__main__":
h5cd = H5CookieId()
target_cookie = h5cd.get_specific_h5_cookie_id()
if target_cookie:
print("\n成功获取目标H5CookieId:")
print(f"值: {target_cookie['value']}")
print(f"过期时间: {target_cookie['expiry']}")
4.运行代码即可获取到酒店数据:
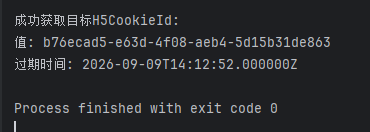
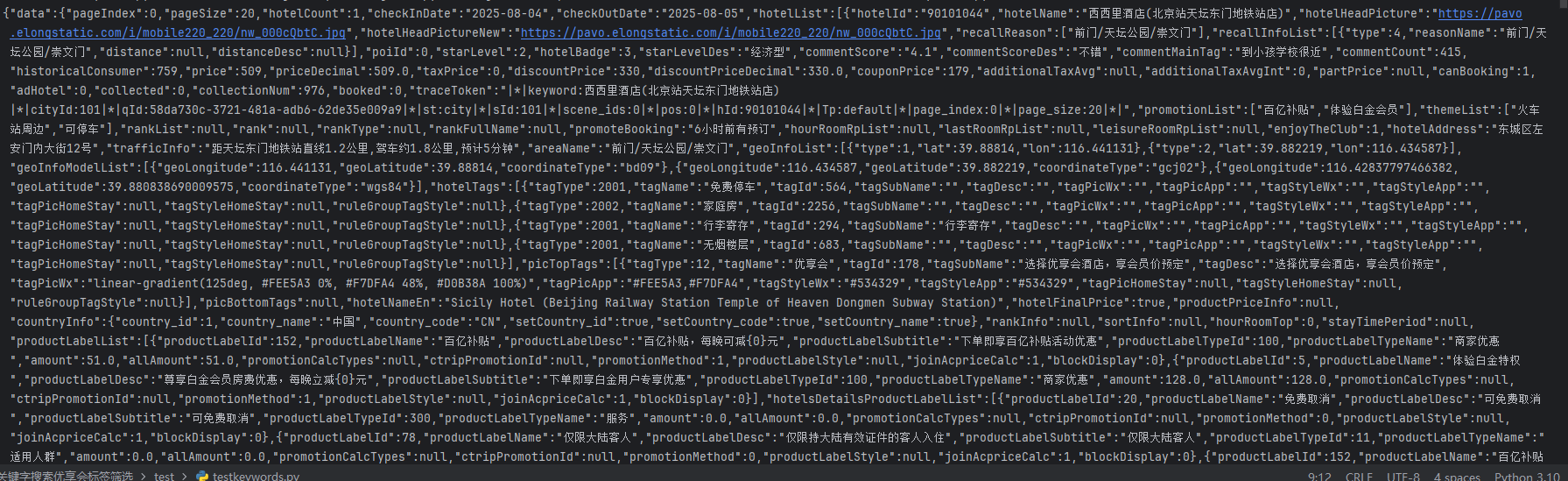
以下数据字段是作者分析的自己所需的子段然后存入csv文件的,可以根据自己需要从response中取出。

三、酒店详细房间数据爬取
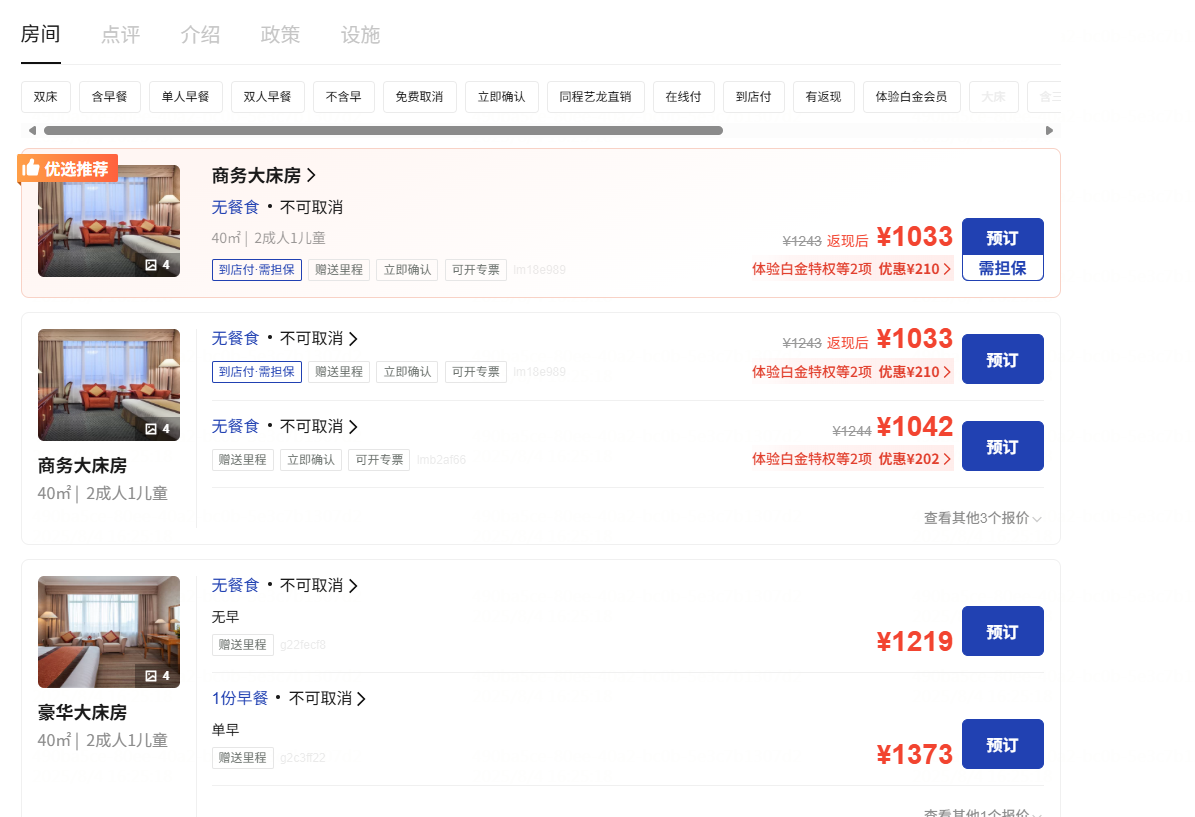
1.点击酒店跳转到详情页面,可以看到不同房间套餐的信息。
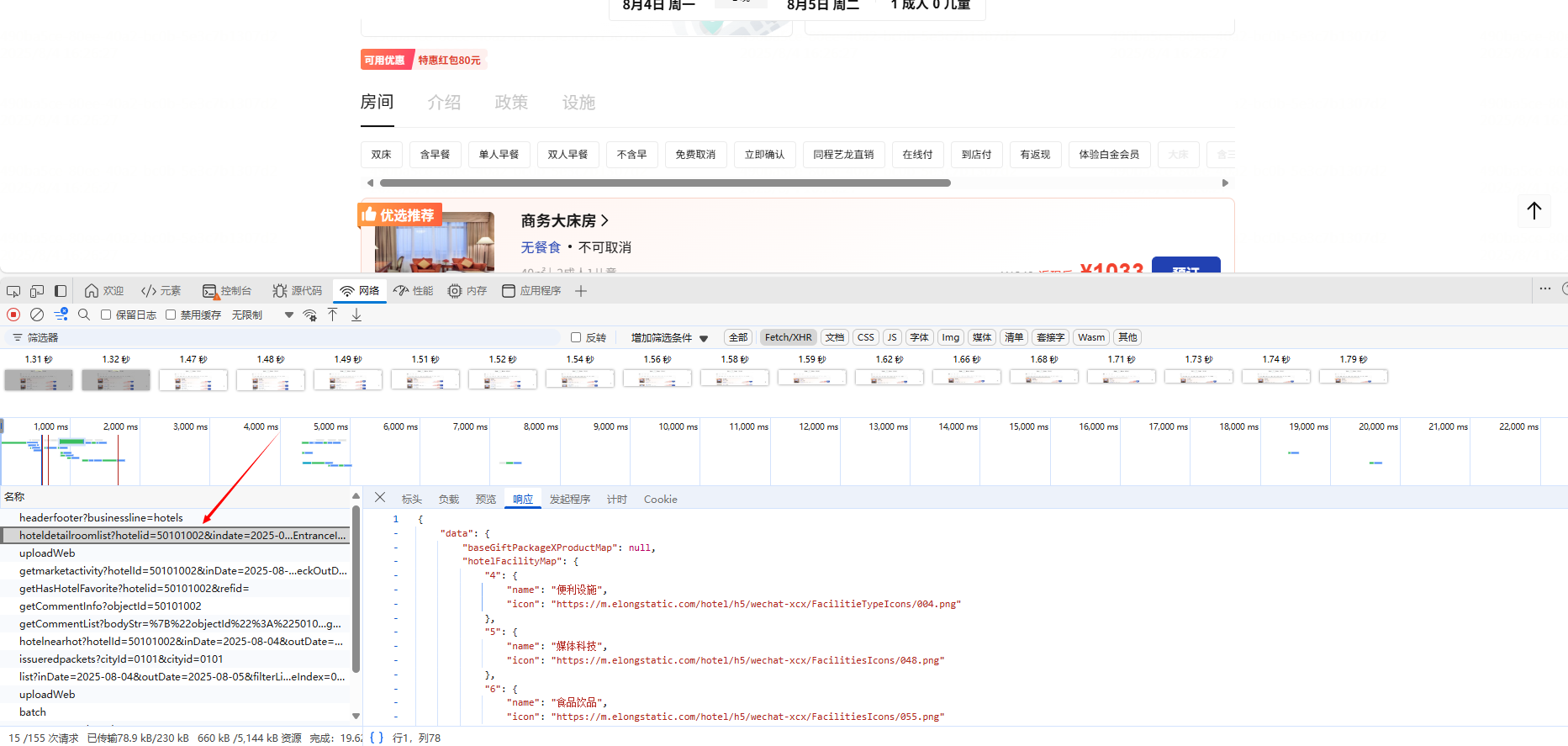
2.查看网络请求可以发现调用了一个叫hoteldetailroomlist接口拿到的房间数据。
3.本地模拟请求:
import execjs
import requests
cookies = {
'SessionToken': '3b9a9220-1691-4d7a-9e6b-25eb398ddb9e622'
}
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0', 'user-dun': 'x7NxxxxxIJjRT+xxI8x2dqbWHiYIzxCIIlWq8XN+W3tJx9827iot5fc5zxC6cX4/TsCxIryODMyqSlfM8tetZpj+SF6XoTof23XrkSn0ciHNmVrnfxlVPPgX6xi91gelFBv3BUiAAUv9r+1OHMivrHBYSFsMfr7rOfZrni4ekoT/6SihmF3/jCi9mVvhrfJi+iJl6orQcarZj20ppq9ZuUF1kFfmzCiyqMuAuoiYOSfczgyEc2UAlRZWZo2k6DjNlRy+pLSV1XkFmUqfZR0AnLBwPCikrl4/A39eLbsX++qX3DPNf5BNa3MgHNYyGNBZvtptZzcLak5gBMMMbTyVm/CWcM+VuS8v5/k6wVJZW+PI3v+xG8RRWiNOGi5W4FT2IdTMpFycW97wqYKKopVMDMNMwMyRAfMOBKbtUxsAk25gQMMRMNMMwUySa5pK98dGIMMOQpya4VqvnJc/4auky0cQ4aukywqrvpzATXqEfOzcTZq9J8/clodZZe24zLi7gbyZuFt2t2DrnKG+IsCWis5R'}
params = {
'hotelid': '20956845',
'indate': '2025-08-19',
'outdate': '2025-08-20',
'adultsNumber': '1',
'childrenAges': '',
'filterList': '',
'rechargeTicket': '1',
'searchEntranceId': 'h5_home',
'traceToken': '',
'if': '',
'of': '',
'ch': '',
'refid': '',
}
response = requests.get('https://www.elong.com/tapi/v4/hoteldetailroomlist', params=params, cookies=cookies, headers=headers)
if response.json().get('errorMessage') == "未获取到登录信息":
print("SessionToken 已过期")
def get_min_price_room_info(json_data):
# 解析JSON数据
data = json_data
# 获取房间信息列表
room_info_list = data['data']['roomInfoList']
result = []
for room_info in room_info_list:
# 获取房间ID和名称
room_id = room_info['mRoomId']
room_name = room_info['roomInfoName']
# 获取该房间的所有套餐
rp_list = room_info['rpList']
# 找出价格最低的套餐
min_price_rp = None
for rp in rp_list:
price_info = rp['productPriceInfo']
ratePlanId = rp['ratePlanId'] # 套餐id
current_price = price_info['priceSubCouponD'] # 现价
original_price = price_info['pricePromotionBeforeD'] # 原价
available = rp['available'] # 是否可以预订
productName = rp['productName'] # 餐食信息
minStocks = rp['minStocks'] # 可能是房间剩余数量
# 比较找到最低价格套餐
if min_price_rp is None or current_price < min_price_rp['current_price']:
min_price_rp = {
'ratePlanId': ratePlanId,
'current_price': current_price,
'original_price': original_price,
'available': available,
'productName': productName,
'minStocks': minStocks,
}
if min_price_rp:
result.append({
'room_id': room_id,
'room_name': room_name,
'ratePlanId': min_price_rp['ratePlanId'],
'original_price': min_price_rp['original_price'],
'current_price': min_price_rp['current_price'],
'available': min_price_rp['available'],
'productName': min_price_rp['productName'],
'minStocks': min_price_rp['minStocks'],
})
else:
print("套餐信息为空")
return result
try:
room_prices = get_min_price_room_info(response.json())
except Exception as e:
print(response.text)
print(e)
# 打印结果
for room in room_prices:
print(f"房间ID: {room['room_id']}")
print(f"房间名称: {room['room_name']}")
print(f"套餐id: {room['ratePlanId']}")
print(f"最低套餐原价: {room['original_price']}")
print(f"最低套餐现价: {room['current_price']}")
print(f"餐食信息: {room['productName']}")
print(f"是否可以预订: {room['available']}")
print(f"剩余房间数量: {room['minStocks']}")
print("-" * 30)
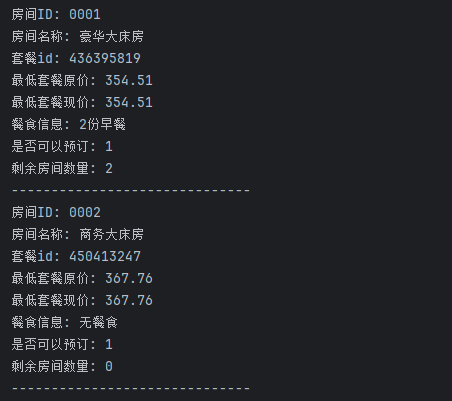
4.运行结果如下,我这里取出了房间价格等数据,还需要其他数据的话可以自行分析response结构进去拿取:

四、爬取艺龙所有城市id、以及城市name对应关系
1.通过请求gethotelcitysbyletter接口可以拿到城市id与name的对应关系
import sys
import requests
response = requests.get('https://www.elong.com/tapi/gethotelcitysbyletter')
all_data = response.json().get('data', [])
if not all_data:
print("返回数据为空")
print(response.text)
sys.exit()
data_dict = {}
for data in all_data:
city_id = data.get('cityId')
city_name = data.get('cityName')
data_dict[city_name] = city_id
print(data_dict)
2.运行结果如下,一共1400多个城市:
![]()
五、总结
可以把上述两个步骤连在一起,先采集酒店id,再通过酒店id来获取每个酒店的详情数据,如有问题可以联系博主。
内容仅供学习参考~

















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









