




Redis 主从架构
Redis 主从工作原理
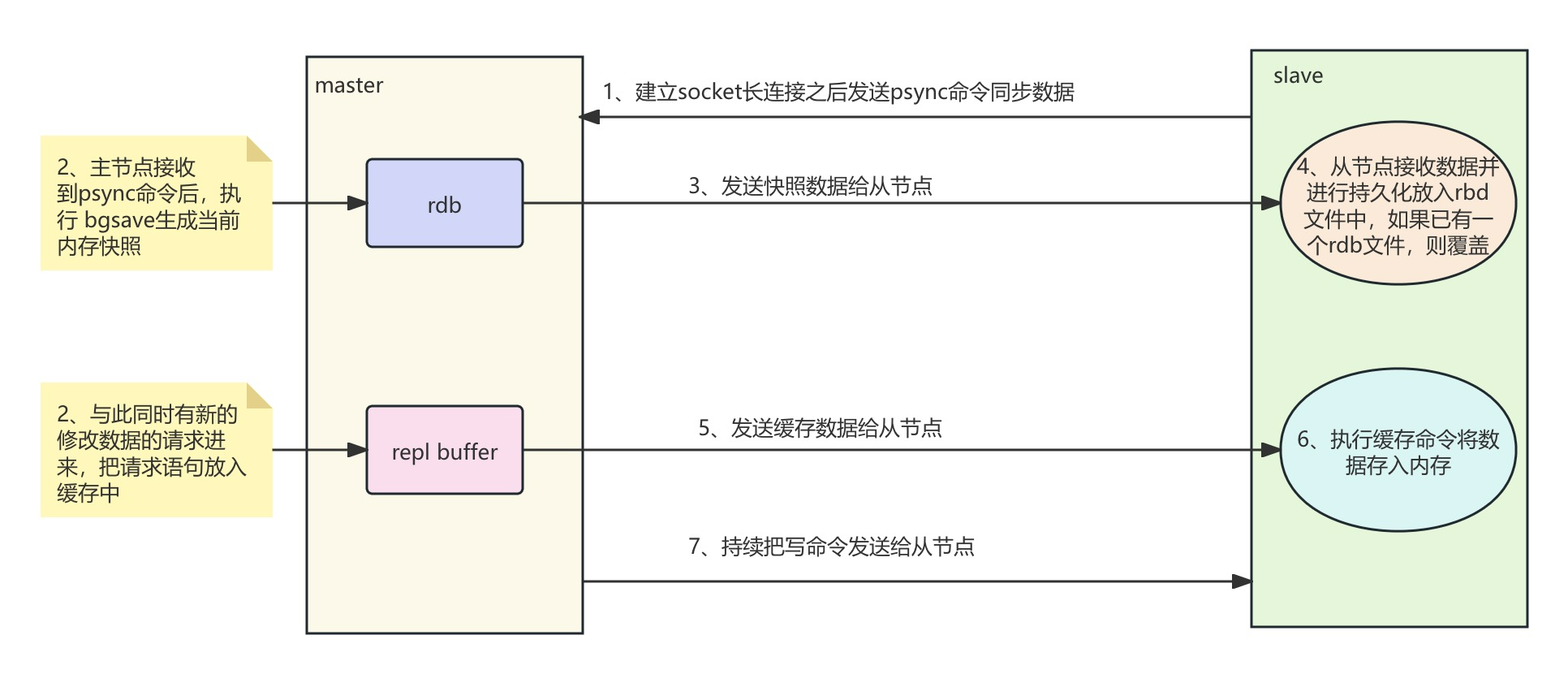
全量复制
当 slave 从节点连接到 master 主节点时,向 master 发送 PSYNC 命令请求复制数据。
master 接收到 PSYNC 命令会执行 bgsave 命令进行数据持久化,生成最新的 rdb 数据快照文件。
数据持久化完成后,master 会把这个文件发送给 slave,slave 接收到 rdb 文件后,把数据持久化生成 rdb 文件,然后把数据加载到内存中。
在数据持久化过程中,仍会有新的修改指令,这些指令会被 master 保存到内存(repl buffer)中,当 slave 完成对 rdb 文件的备份,即把数据加载到内存之后,master 会把内存中的指令发送给 slave。、
全量复制流程图
注意:如果有多个 slave 同时向 master 发送复制请求,master 只会生成一个 rdb 文件。
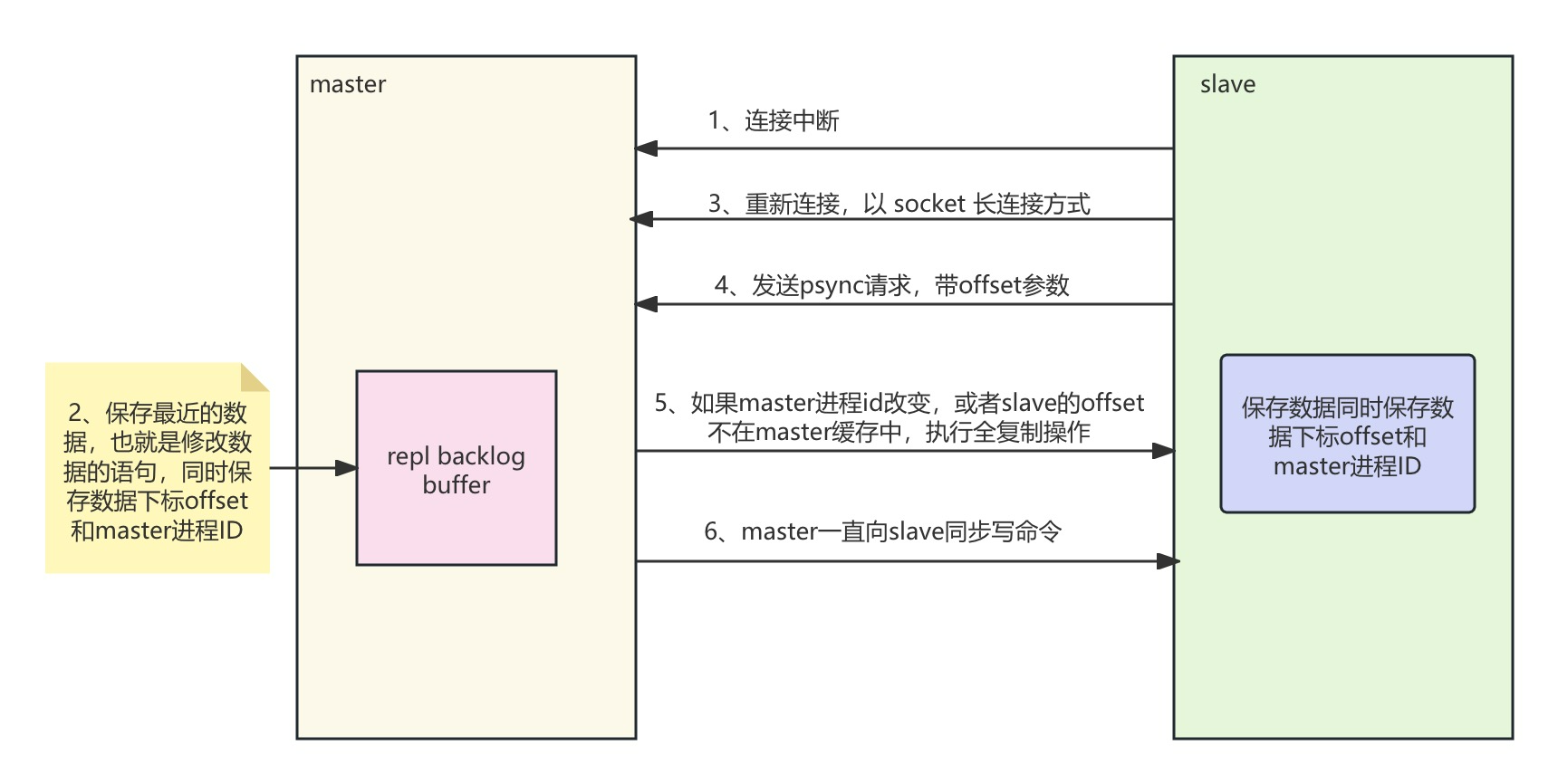
数据部分复制
当 slave 和 master 断开重连,断开时间不是很久,如果使用全量复制有些耗费性能,这时可以选择部分数据复制。
master 会维护一快内存(repl backlog buffer),用来放最近执行的修改数据指令;slave 会维护一个标数据下标 offset,用来表示已经同步到哪条数据了。
如果 slave 维护的 offset 在 master 的 repl backlog buffer 中,master 会把 offset 之后的数据一次性全部同步给 slave;否则进行全量复制。
数据部分复制流程图
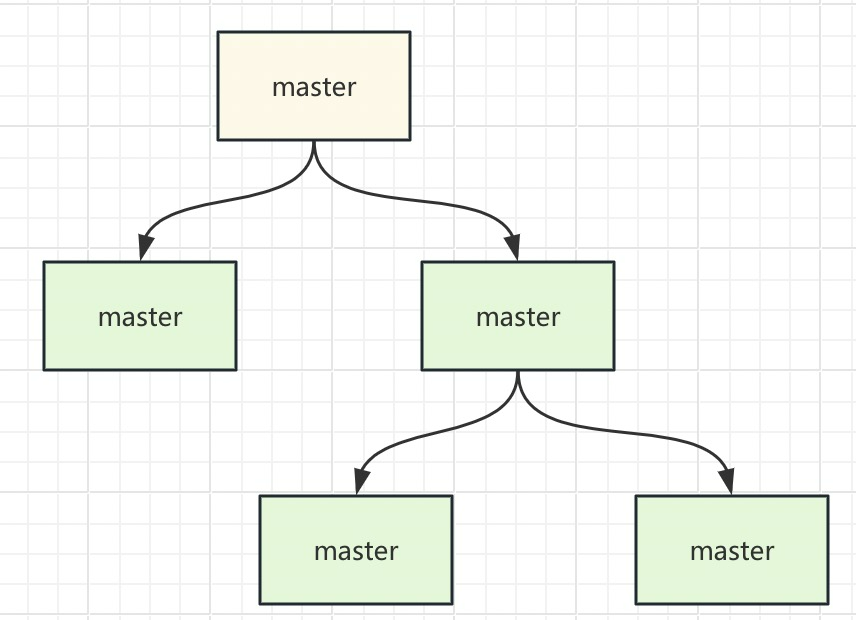
Redis 主从复制风暴
定义: 当从节点太多,同时向主节点请求全量复制,主节点压力过大。
解决办法: 让部分从节点作为另一部分从节点的主节点。
Redis 哨兵模式
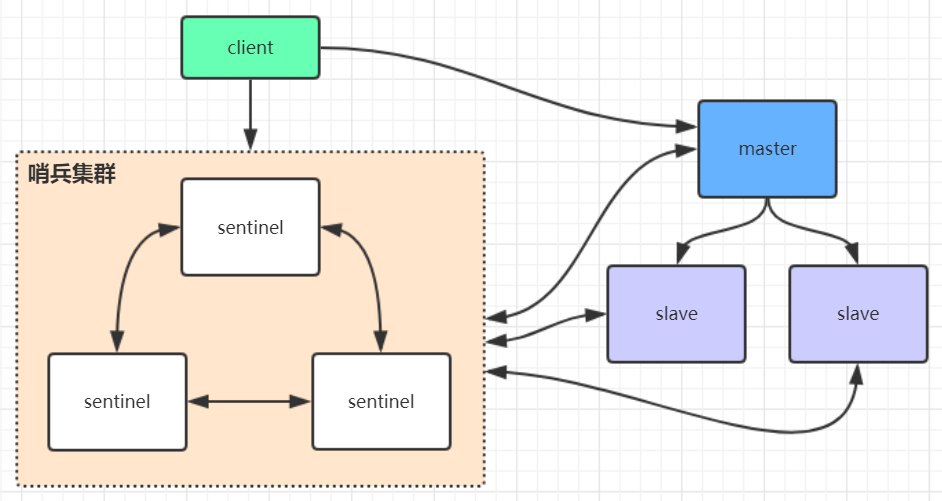
Redis 哨兵模式工作原理
哨兵节点不提供读写功能,只是用来监视 master, slave 节点。
当 client 第一次访问 master 时,是通过 sentinal 代理访问的,之后就不用了,可以直接访问 master 节点。
当 master 节点发生变化时,sentinal 会在第一时间感知到,并且将新的 master 告知给 client。
Redis 哨兵模式缺点
- 只有一个主节点提供对外服务,没办法支持很高的并发。
- 内存不宜设置的过大。如果内存过大会使数据恢复或者主从同步的效率降低,一般不超过 10G。
- 在主从切换的时候会出现访问瞬断的情况,丢失数据。
Redis Cluster 集群模式
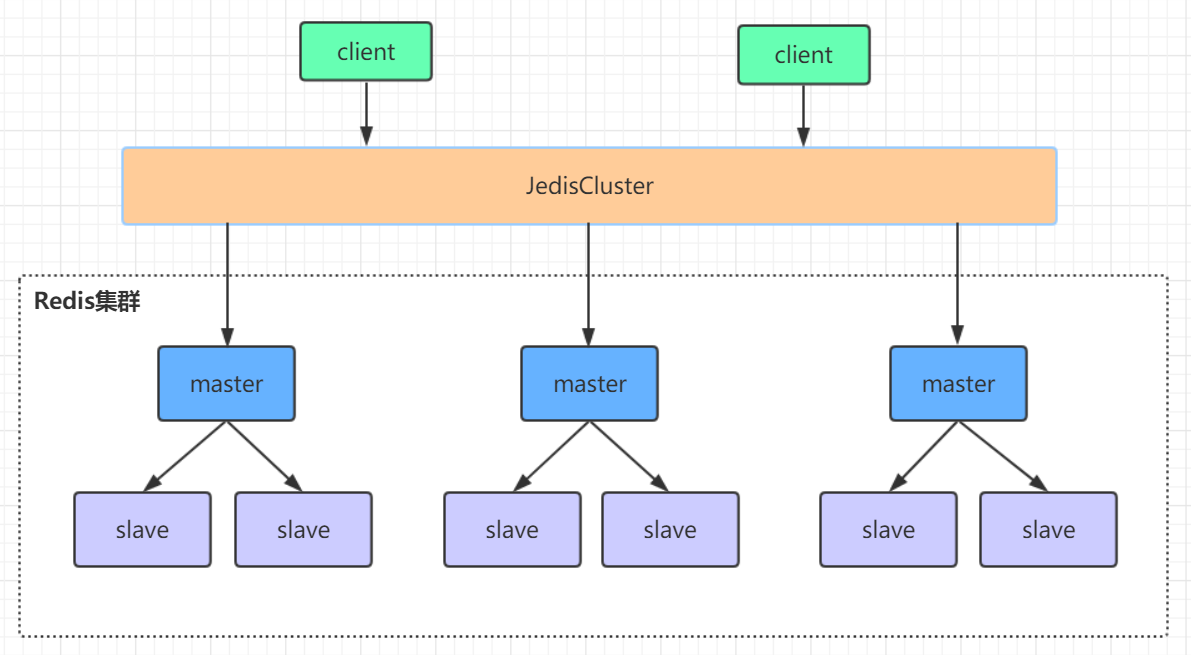 定义: redis 集群是由多个主从节点构成的分布式服务器群,具有复制,高可用和分片特性。可以自动完成节点移除和故障转移的功能。集群模式没有中心节点,可水平扩展,官方建议不超过 1000 个。
定义: redis 集群是由多个主从节点构成的分布式服务器群,具有复制,高可用和分片特性。可以自动完成节点移除和故障转移的功能。集群模式没有中心节点,可水平扩展,官方建议不超过 1000 个。
Redis 集群工作原理
Redis Cluster 将所有数据分为 16384 个 slots(槽位),每个节点负责其中一部分槽位,每个节点可以看到槽位的全部信息。
计算槽位(槽位定位算法)
使用 CRC16 算法对 key 进行 hash 获得一个整数值,这个值对 16384 取模后的结果,就是这个 key 要存放的槽位位置
HASH_SLOT = CRC16(key) mod 16384
跳转重定位
当客户端连接集群时,会得到一份槽位配置信息并将其缓存在客户端本地。
如果计算的槽位不在这个节点 A 上,这个节点会告诉客户端跳去这个槽位所在的节点 B 上,并且执行指令。
Redis 集群节点间的通信机制
元数据: 集群节点信息,主从角色,节点数量,各节点共享的数据等。
集中式
每个 Redis 节点维护了一份本地集群视图,就是它对整个集群当前状态的认识。一个节点的元数据一旦变更,会立即更新到本节点的内存结构中,同时将更新信息同步到其他节点,其他节点读取时就能看到最新的状态。
优点: 时效性非常好,同步更新。
缺点: 如果一个节点频繁更新元数据,再向其余节点同步时 CPU 和内存压力上升,网络压力加大,元数据维护延迟或不一致风险上升。
Gossip 通信机制

如图所示,Gossip 是一种去中心化的、“类似传染”式的消息传播协议。接收到消息的节点会把消息同步出去,而不是只由一个节点向其余节点同步消息。
优点: 元数据更新比较发散,降低了压力。
缺点: 更新会有延迟,存在短期不一致的情况出现。
Redis 集群选举原理
集群选举发生在 master 变为 FAIL 时,slave 期望自己变为 master,会像其余节点发送参与竞选请求,由其余的 master 节点决定这个 slave 是否可以选举成功。
当一个 master 有多个 slave 时,这些 slave 就会发生竞争,以下是竞争流程:
1、slave 发现 master 变为 FAIL。
2、将自己记录的集群 currentEpoch 加 1,广播 FAILOVER_AUTH_REQUEST 信息,只有 master 会响应这个请求。
3、master 节点判断请求者的合法性之后,向 slave 发送 FAILOVER_AUTH_ACK。每一个 master 只能响应一个请求,响应之后,对于其余的请求不再响应。
4、slave 收集获得的 FAILOVER_AUTH_ACK。
5、如果收到超过半数的 master 发来了 FAILOVER_AUTH_ACK,这个 slave 变为 master。
6、slave 广播消息通知其他节点。
注意: slave 并不是在 master 进入 FAIL 状态立马进行选举,而是等待一段时间。为了使其余节点能够收到 master 进入 FAIL 状态的消息,否则可能造成选举不成功。
Redis 集群面临的问题及解决办法
网络抖动
网络抖动是机房网络突然之间,部分连接变的不可访问。这种情况会导致主从频繁切换。
使用 cluster-node-timeout 可以解决这个问题,这个参数的意思是当某个节点持续 timeout 的时间失联时,才可以认定该节点失效,需要主从切换。
集群脑裂数据丢失问题
脑裂是指由于网络分区或节点故障,集群中原本只有一个主节点,出现了多个节点同时对外提供服务的情况,导致数据冲突、不一致、丢失等严重情况。
在集群模式下,主节点由于网络波动,在部分节点中失联,从节点发起投票并成功晋升为主节点,这时有两个节点可以接收到客户端的写请求。
如果老的主节点网络恢复了,这时他会成为新的主节点的从节点,导致之前客户端的写入数据丢失。
通过配置 min-slaves-to-write 这个参数可以解决这个问题
min-slaves-to-write 1 //写数据成功,最少同步的 slave 数量,可以按照大于半数机制配置
集群是否完整才能外提供服务
前提条件:其中一个主从架构全部处于故障未恢复。
通过 cluster-require-full-coverage 配置参数可以决定。
yes: 不可以
no: 可以
Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
至少需要三个 master 节点是因为从节点需要大于半数 master 节点支持才可以选举成功。如果只有两个 master,选举时只有一个 master ack,不能选举成功。
推荐奇数是从节省机器资源角度考虑的。奇数 master 可以在满足选举条件的情况下节省一个节点,例如比较 3 个 master 节点和 4 个 master 节点,当 1 个 master 宕机时,都能选举新的 master 节点;当 2 个 master 宕机时,均不可以选举新的 master 节点。
Redis集群使用批量操作命令
# 在key的前面加上{XX},这样计算槽位只会使用大括号里的值,确保这些信息放在一个槽位
mset {user1}:1:name zhuge {user1}:1:age 18

















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









