 解决Python编码与类型错误
解决Python编码与类型错误





 本文解决了在使用Python处理文件时常见的两个问题:UnicodeDecodeError和TypeError。前者由不正确的文件编码导致,通过指定正确的编码格式(如'utf-8')可以解决;后者通常是因为错误的文件打开模式,应确保使用正确的'r'或'r+'模式。
本文解决了在使用Python处理文件时常见的两个问题:UnicodeDecodeError和TypeError。前者由不正确的文件编码导致,通过指定正确的编码格式(如'utf-8')可以解决;后者通常是因为错误的文件打开模式,应确保使用正确的'r'或'r+'模式。
自拟需求:将一段对话解析出来,并规范命名格式为——人名_序号;
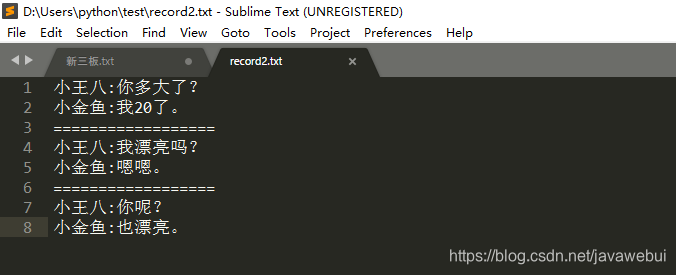
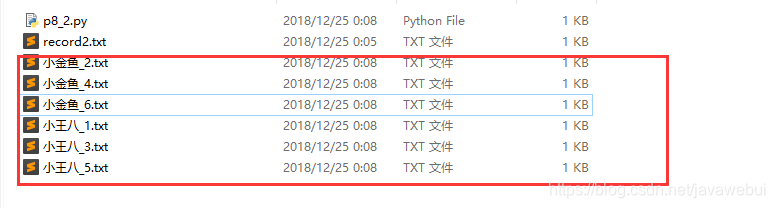
代码如下:

在完善这个功能之前遇到两个错误:
1.UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xab in position 8: illegal multibyte sequence
——这个是由于文件打开编码格式造成的:修改如下
如图:f=open(file_name,encoding=‘utf-8’)
io_file=open(file_name,‘w’,encoding=‘utf-8’)
2.TypeError: a bytes-like object is required, not 'str’
——这个是由于打开的方式写成了
如图:f=open(file_name,‘rb’),改为f=open(file_name,‘r’)或者f=open(file_name,encoding=‘utf-8’)即可。
祝大家编程顺利哈!


















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









