



今天这篇文章给大家盘点一下NeurIPS 2025中和模型结构优化相关的工作。这些优化属于相对通用的模型结构优化,可以迁移到各个深度学习领域。优化的结构包括attention计算方式、稀疏attention、KV cache、Dense网络等多个维度。NeurlPS’25的通用模型结构优化更多集中在性能优化上,也可以看出在大模型时代,如何无损压缩模型计算量、参数量是一个最为核心的课题。
1
Gated Attention强化信息有效性
Gated attention是对self-attention计算方式的一种优化,其核心思路是在attention计算结果中引入一个gate门控模块,对无效信息进行过滤。例如,当一个序列中的各个key和query都没关系时,attention中的softmax仍然会强制生成一个和为1的权重list对value进行加权,但是这部分信息对于模型来说是噪声。因此文中引入了一个gate结构,在attention计算结果之后对无效信息进行过滤。
文中尝试了在不同位置引入这个gate结构,最优的结构为:在每个head计算完attention结果后,用输入结果和对应的gate结果进行element-wise的加权。其中gate使用映射成QKV之前的表征作为输入,每个head使用一个独立的权重W进行线性变化,接一个sigmoid激活函数得到门控打分。
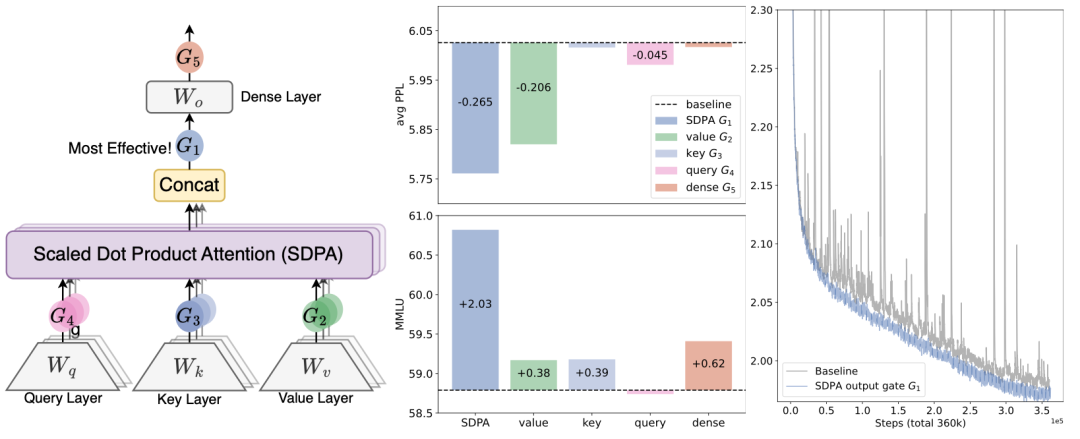
论文标题:Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
2
MGLU压缩GLU参数量
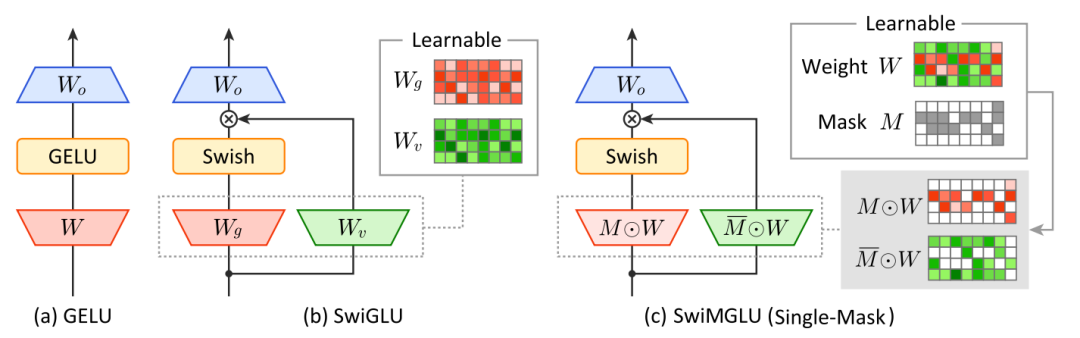
GLU是目前深度学习中最常用的激活函数,SwiGLU等GLU变种也是大模型中目前的主要激活函数。GLU激活函数计算逻辑是用两组不同的参数对输入进行线性变化后,一组使用sigmoid、swish等激活函数生成门控结果,再和另一组进行element-wise相乘完成对输入的非线性变换。这种方式相比ReLU额外增加了一组线性映射计算量,增加了模型参数存储空间。
文中提出了一种引入Mask版本的GLU,其核心是让上述两组线性变换的参数矩阵共享成同一组参数,然后使用一个可学习mask矩阵对这组参数进行拆分,拆成两组参数实现后续的GLU计算。通过这种方式,实现了GLU计算不额外引入参数量的目的。
文中进一步引入多组不同类型的mask结果,使用不同mask结果对矩阵进行不同类型的拆分后,进行多组GLU结果的融合,实现接近无损的参数压缩。
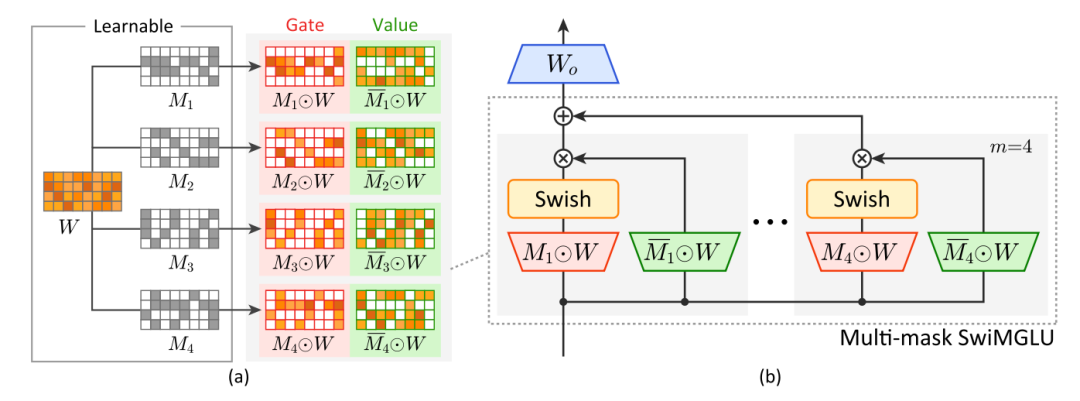
论文标题:Masked Gated Linear Unit
3
时间维度的KV Cache压缩
KV cache是大模型推断、生成式中的一个关键技术,由于其在推断时需要进行next-token prediction,需要重复计算历史的attention结果,提前对历史计算过的key和value结果进行缓存,可以大幅提升推断时的性能。在此基础上,存在多个进一步提升性能的方法,例如multi-query attention通过共享不同head的key和value参数、MLA通过对key和value进行低秩分解等进一步优化性能。
这篇文章则在另一个维度进行KV cache优化,提出了在时间维度上进行压缩,直接减少打分计算量。在MLA基础上,引入一个压缩系数,将相邻的s个token的低秩结果进行融合,融合方法是使用一组可学习的权重进行相邻token的加权求和。通过这种方式,将多个token的低秩向量进行融合。由于不同输入样本的序列长度不同,因此使用hyper-network生成权重,输入所有token的低秩向量,输出每个token对应的融合权重。
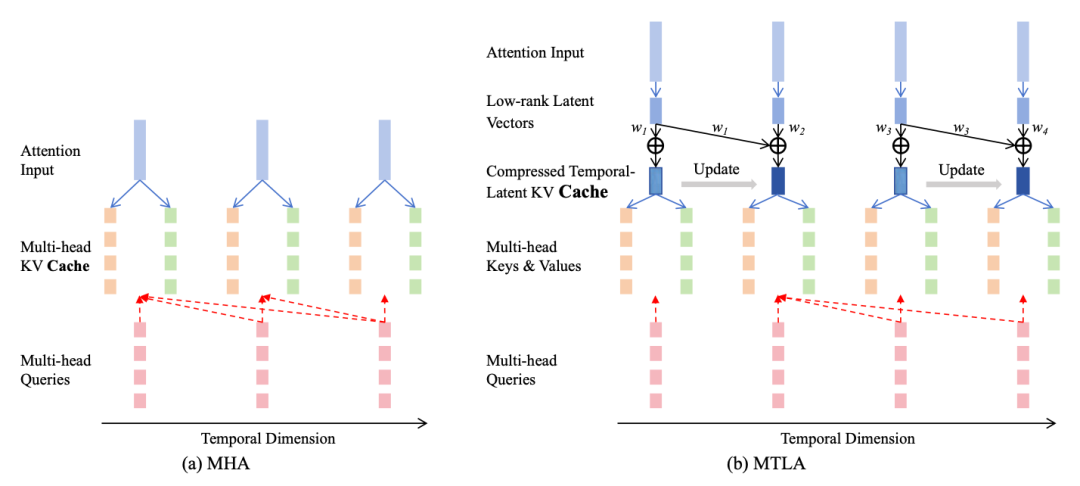
论文标题:Multi-head Temporal Latent Attention
4
SeerAttention蒸馏提升长序列计算效率
Attention的计算时间复杂度随着序列长度提升呈指数提升,因此如何提升长序列的attention计算效率是一个比较关键的问题。本文提出了一种简洁的优化方法,通过pooling的方式直接在序列维度进行聚合,并蒸馏原始的完整attention结果。
具体建模上,对于query和key的原始输入序列结果,使用包括max-pooling、mean-pooling等多种pooling方式进行相邻token信息的汇聚,并过一层MLP映射,得到相比原始输入序列长度维度大幅缩减的压缩版本,再基于这个缩短后的序列进行内积、softmax等的计算,得到一个压缩版本的attention打分结果,文中称为AttentionGate。同时,对于完整的query和key计算得到的attention矩阵,使用max-pooling作为ground truth,用KL散度进行蒸馏。线上应用时,使用阈值卡控topK进行AttentionGate的二值化处理。通过这种方式,大幅降低了长序列attention计算的复杂度,并能接近效果无损。
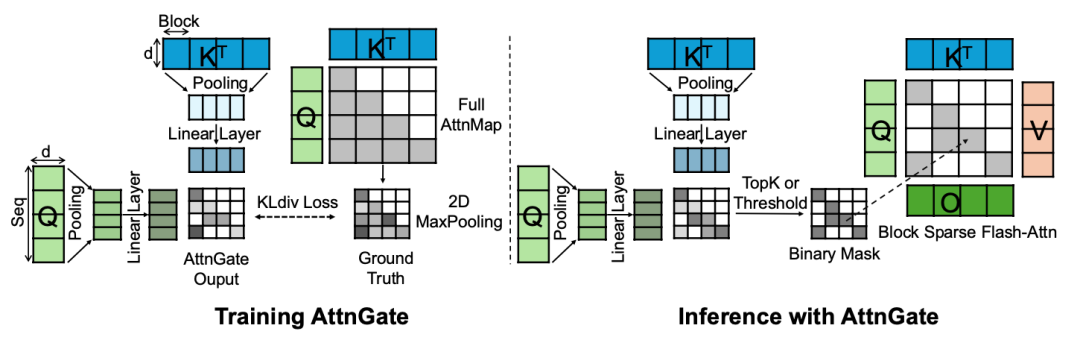
论文标题:SeerAttention: Self-distilled Attention Gating for Efficient Long-context Prefilling
5
EUGens新型MLP网络
FFN一直是大模型中计算资源耗费比较大的模块。这篇文章中提出一种新的MLP形式,能够减少参数计算量。原始的MLP网络,使用输入x和可学习参数矩阵W进行点乘,再过一个激活函数得到。本文提出的EUGen,其基础形式将x和W进行解耦,W和x分别过一个激活函数后,使用一个映射网络进行降维,再在最后对两个降维的结果计算内积。在Transformer中,使用这种结构替代原来的FFN,大幅降低了计算量。
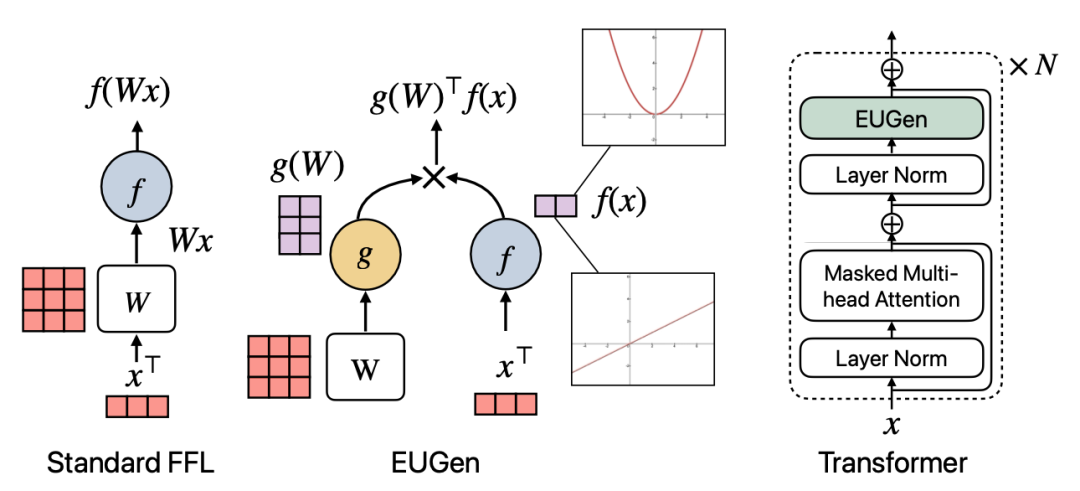
论文标题:EUGens: Efficient, Unified, and General Dense Layers
6
Spark Attention构建稀疏FFN和Attention
在对大模型Transformer结构中的FFN分析时,可以发现其中只有部分神经元对应的值是比较大的,对应FFN天然存在稀疏性。基于上述发现,本文提出了Spark Attention,对Transformer中的FFN和attention结构进行了稀疏化。
在FFN结构上,原来的计算逻辑是,第一层输入乘一个矩阵W1升维,过激活函数,第二层乘一个矩阵W2还原维度。Spark Attention中,第一层进行改动,只保留过激活函数之后数值topK的输出结果,其余的都置为0。同时,参考了Gated-FFN方案中,会在第一层FFN中引入一个类似GLU的结构,本文将输入拆分成两个部分,套用Gated-FFN,前一部分过激活函数保留topK,后一部分使用单独的参数映射后进行element-wise相乘。整体计算公式如下:
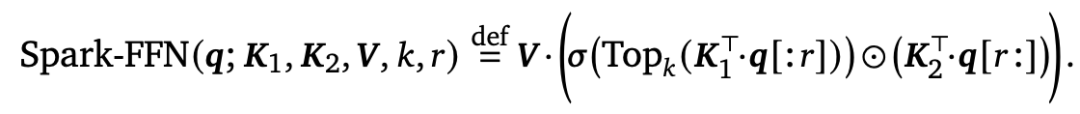
在attention的结构中也采用类似的方法进行计算。在topK的选取上,采用了Statistical Top-k算法,能够在不对原始各个值进行排序的情况下近似选出topK结果。
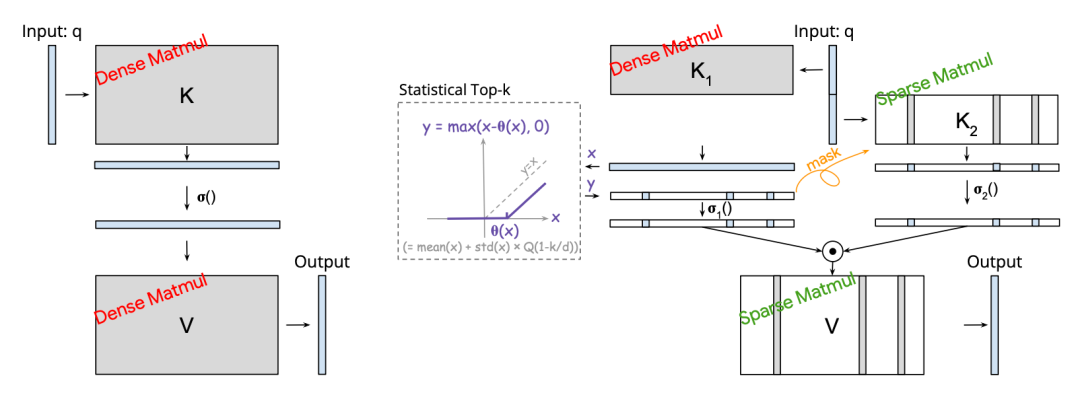
论文标题:Spark Transformer: Reactivating Sparsity in FFN and Attention
7
HybridNorm混合归一化提升Transformer性能
Normalization是Transformer中的一个核心组件,用于提升Transformer训练的收敛速度。常见的Normalization方法包括pre-norm和post-norm。Pre-norm对每一层的输入进行normalization,而post-norm则是对attention+残差计算结果之后进行normlization。
本文提出了一种混合归一化的方式进一步提升Transformer收敛速度。首先,引入了QKV-norm,在计算attention前,对每个query、key、value分别进行归一化。其次,在FFN部分采用post-norm。
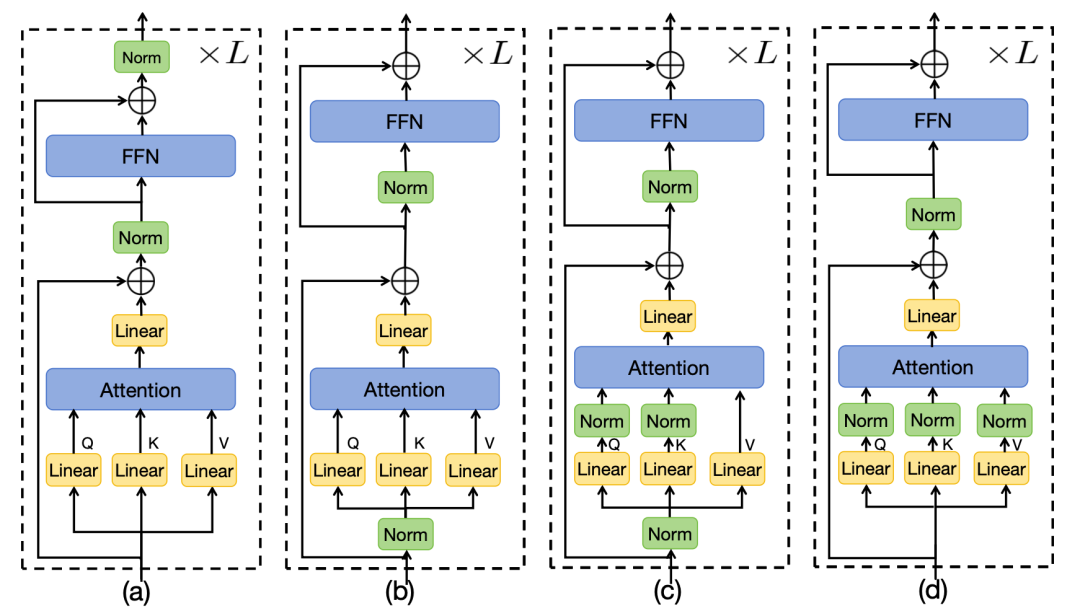
论文标题:HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

















 2379
2379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









