



随着 DeepSeek-OCR 的爆火,“视觉压缩”和“文本压缩”成为了热门研究方向。东北大学自然语言处理实验室与小牛翻译团队最新发表的一篇论文《Position IDs Matter: An Enhanced Position Layout for Efficient Context Compression in Large Language Models》提出,仅通过改变输入标记(token)的“位置编号”,无需调整模型结构,就能显著提升图像与文本的压缩效果!
听起来很离谱对吧?但它的原理其实很好懂。
把压缩过程想象成一群记录员在记录信息
在处理图像或文本时,模型会安排一组“记录员”负责概括、压缩前面所有的数据。
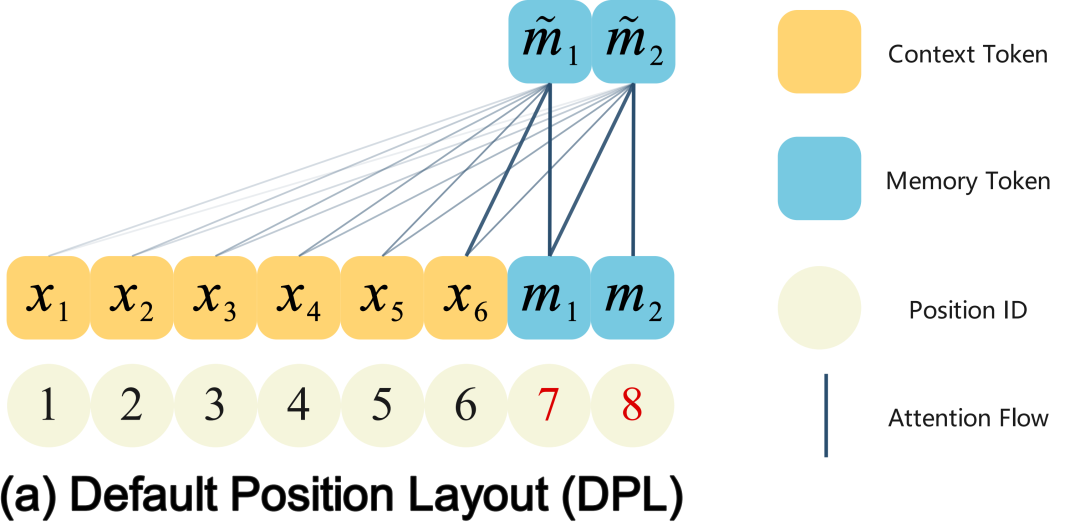
以往做法都是这样:
- 所有内容(x1~x6)排在前面
- 记录员(m1,m2)排在最后面
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
这样做有一个好处:
记录员在最后能看到所有内容,理论上更好总结前面的信息。
但问题来了——
距离太远,看不清!
记录员虽然能“看到”前面的所有信息,但距离太远,注意力效果会变差,就像隔着很远看黑板一样,能看见但看不清,于是压缩质量就变差了。
那把记录员移到前面不就好了?
有人想过把记录员移到前面。但立刻会遇到另一个问题:记录员如果放到前面,能离前面的内容更近,看得清,但看不到后面大部分内容。
等于直接变瞎。
那我们能不能让记录员“身体在后面,但心(虚拟位置)在前面”?
我们的具体做法:
- 记录员的真实位置仍然放在最后
- 给它们分配虚拟的前排位置编号(记录员m1的编号变为2,记录员m2的编号变为5),注意力机制会把它们当成在前排:
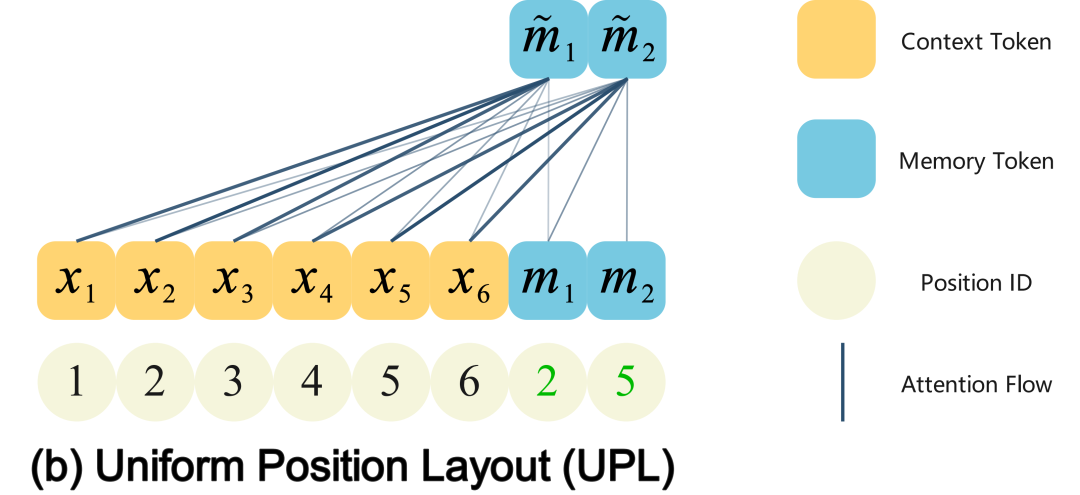
这样一来:
- 既能看到全部信息(因为实际位置在后面)
- 又能更清晰地关注前面的内容(因为位置编码假装它们在前面)
这就像:
让记录员坐在教室最后一排,但给他们一副 VR 眼镜,让他们感觉自己就坐在每一排中间。
效果:压缩变得更轻松,信息提取更准确!
这个非常简单的小 trick,让模型在视觉压缩、文本压缩上都有明显提升:
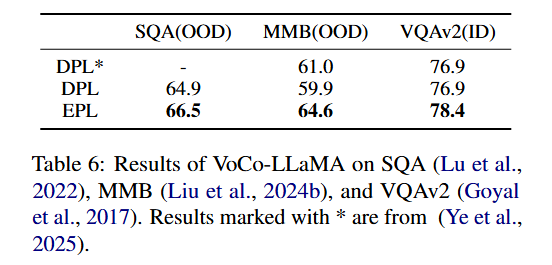
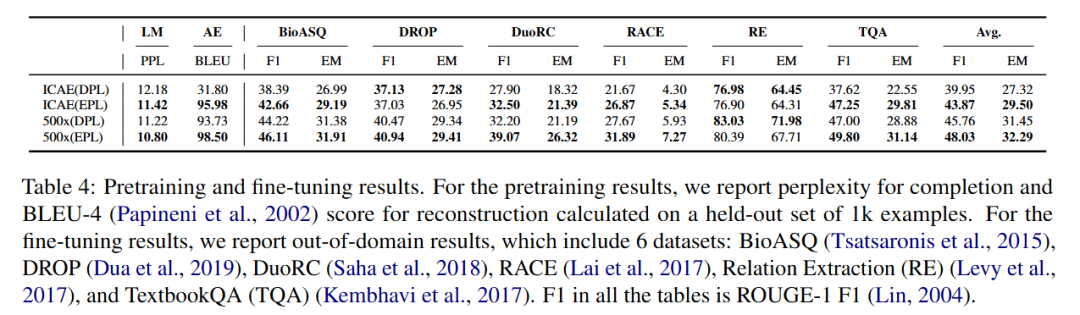
同时还能加速训练收敛:
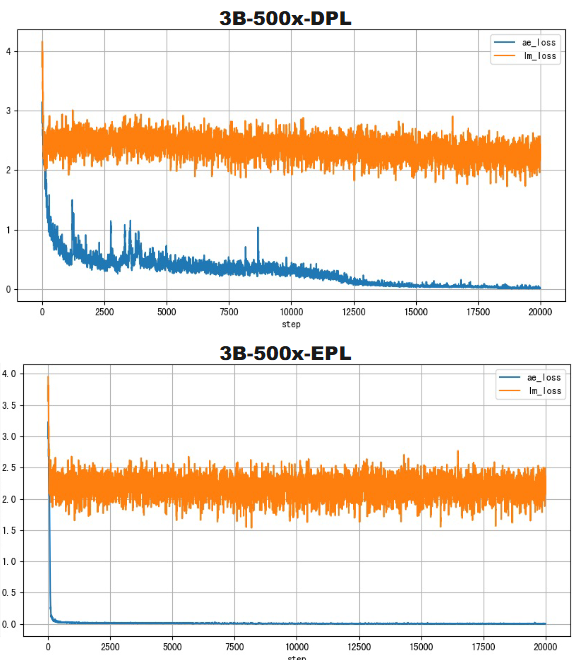
可以说是:
几乎没什么成本,却能换来很大的收益。
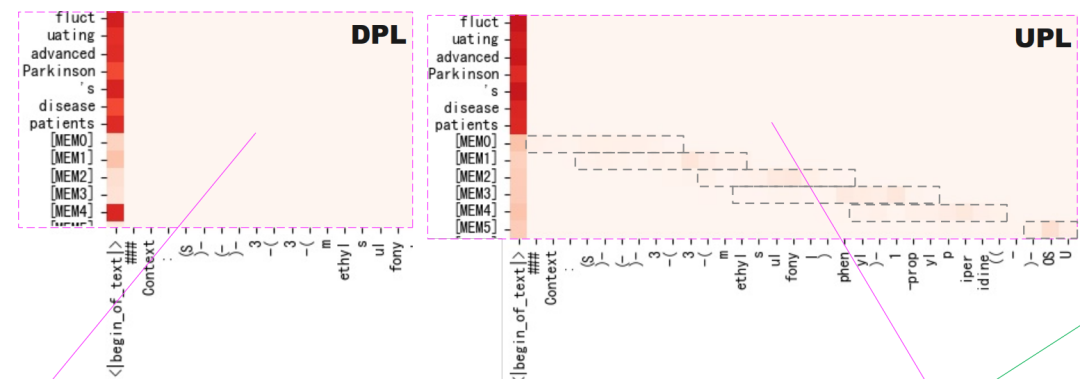
分析实验:改变位置编号确实能让记录员关注前面的信息
从下面的注意力图,我们可以观察到在原先的虚拟位置分配策略(DPL)中记录员([MEM0]~[MEM5])注意力不在前面的信息中;而使用我们的虚拟位置分配策略(UPL)能让记录员的关注到前面的信息。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









