



啥是微调?为啥要微调?什么时候微调?
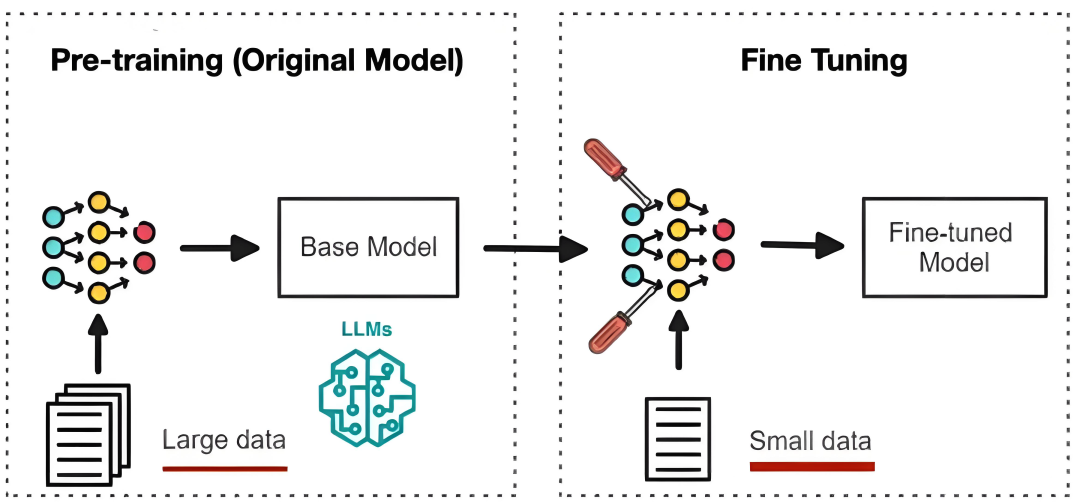
Fine-tuning(微调/精调)
指在预训练模型上,用特定任务的数据进行额外训练,微调模型参数,使其适应新任务。
预训练模型:
已在大规模数据上学习通用特征的基础模型(如qwen、deepseek)
belike: 应届毕业生
特点: 啥都会点,但缺特定行业经验
微调后:
注入领域专属知识(如金融、法律)使模型具备特定场景下的专业能力
belike: 培训后的牛马
特点: 专业打工人,业务能力杠杠的
Fine-tuning的优势
省钱省力:微调就像站在了“巨人(预训练模型)的肩膀上”,避免了从零训练所需的巨大算力和数据成本。
性能强劲:在高质量领域数据上微调能显著提升模型在特定任务上的准确性和可靠性,使其表现远超通用模型。
灵活个性:可以塑造模型的风格和性格,使其输出更符合业务需求,如特定的文风、话术或决策逻辑。
Fine-tuning的类型
微调方法有很多种,从训练数据是否标注,可分为监督微调(SFT)和其他,从参数策略角度,可分为全量微调和高效微调。
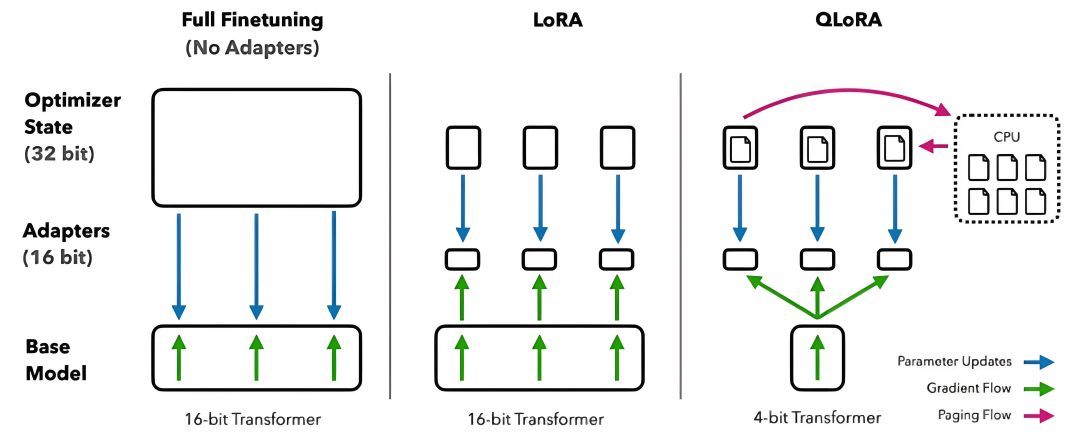
全量微调
把所有参数都训练一遍,算力消耗大,但对模型改造更彻底
高效微调
只训练底模的部分参数,通过修改部分参数调整模型整体能力,LoRA是其中的一种常用策略,(QLoRA类似于它的pro版,更轻量)
什么时候选择Fine-tunning?
RAG的本质是给大模型添加参考书
适用于:知识更新快/要引用外部资料(如智能客服、基于公司资料问答)
Fine-tuning的本质是培养大模型成为某个领域的专家
适用于:任务风格固定/要改变模型说话方式(如特定领域的医疗/法律顾问)
总结
微调就是培养大模型成为领域专家
它省钱省力、性能强劲、灵活个性
全量 vs 高效/LoRA
要让大模型学新技能/风格用微调
要给大模型查资料用RAG
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

















 2425
2425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









