






原文:https://mp.weixin.qq.com/s/GePUujUbJwx_8fyGo4elnA
还在为AI助手无法理解文档中的图表而苦恼吗?传统RAG系统面对包含图像、表格的复杂文档时总是"视而不见",导致回答不完整、信息缺失。 Dify 1.9.0的Knowledge Pipeline功能彻底改变了这一现状!
通过集成强大的MinerU工具,现在可以轻松从PDF、Word、PPT等多种格式文档中提取图像,将其存储为URL并实现文本-图像混合输出。 这意味着你的AI助手不仅能"读懂"文字,还能"看懂"图表,让回答更加准确和完整!
🚀 Knowledge Pipeline:RAG架构的革命性升级
什么是Knowledge Pipeline?
Knowledge Pipeline是Dify 1.9.0引入的全新知识处理架构,它将传统的文档处理流程模块化,让用户可以像搭积木一样自由组合各种处理节点。
核心工作流程:

为什么需要图像提取功能?
传统RAG系统的三大痛点:
-
• 🔗 数据源集成受限:只能处理纯文本内容
-
• 🖼️ 关键元素缺失:无法识别表格、图表等视觉信息
-
• ✂️ 分块效果不佳:复杂版面处理能力不足
Knowledge Pipeline通过MinerU工具完美解决了这些问题,实现了真正的多模态知识处理。
🛠️ MinerU:文档解析的超级引擎
核心技术特性
MinerU是一个高质量的文档转换工具,专门为复杂文档解析而生:
1. 多格式支持
-
• 支持PDF、DOC、DOCX、PPT、PPTX、PNG、JPG、JPEG等格式
-
• 自动识别文档类型并选择最佳解析策略
2. 智能图像提取
-
• 精确识别文档中的图像、图表、表格
-
• 自动提取图像描述和标题信息
-
• 将图像路径替换为可预览的URL(有效期由FILES_ACCESS_TIMEOUT控制)
3. 版面结构保持
-
• 移除页眉、页脚、页码等干扰元素
-
• 保持原文档的标题、段落、列表结构
-
• 支持单列、多列和复杂版面的智能识别
4. 多语言OCR能力
-
• 支持多种语言的OCR识别
-
• 自动检测扫描PDF和乱码PDF
-
• 混合OCR文本提取,结合文本模式和OCR模式的优势
📋 实战操作:10分钟搭建图像提取流水线
步骤1:环境准备
1.1 确保Dify版本
确保使用Dify 1.9.0或更高版本,该版本引入了Knowledge Pipeline功能。
1.2 配置文件存储
在.env文件中正确配置文件存储设置:
# 重要:FILES_URL设置
FILES_URL=http://your-ip:port注意:FILES_URL不要设置为Minio的外网地址,应使用Dify API服务地址,这样可以避免401认证错误。
步骤2:安装MinerU插件
2.1 进入插件市场
-
• 登录Dify平台
-
• 导航至"工具" → "插件市场"
-
• 搜索"MinerU"插件并添加
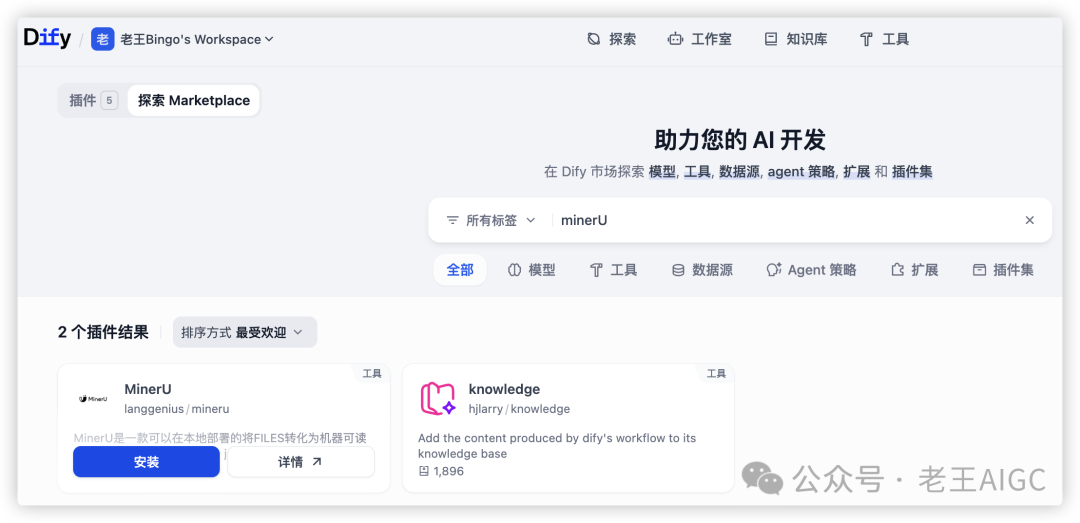
2.2 配置MinerU参数
使用官方API(推荐,目前官网可以免费申请):申请地址为https://mineru.net/
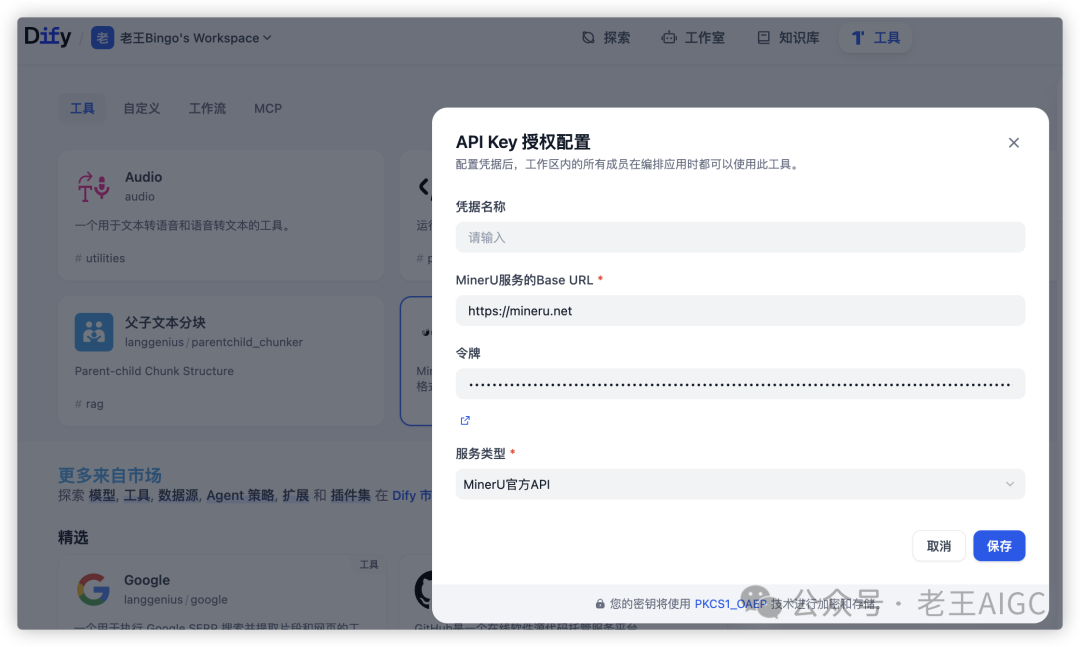
使用本地部署:
Base URL: http://YOUR_LOCAL_IP:8888
Token: 留空(本地部署不需要)
Service Type: Local Deployment步骤3:创建Knowledge Pipeline
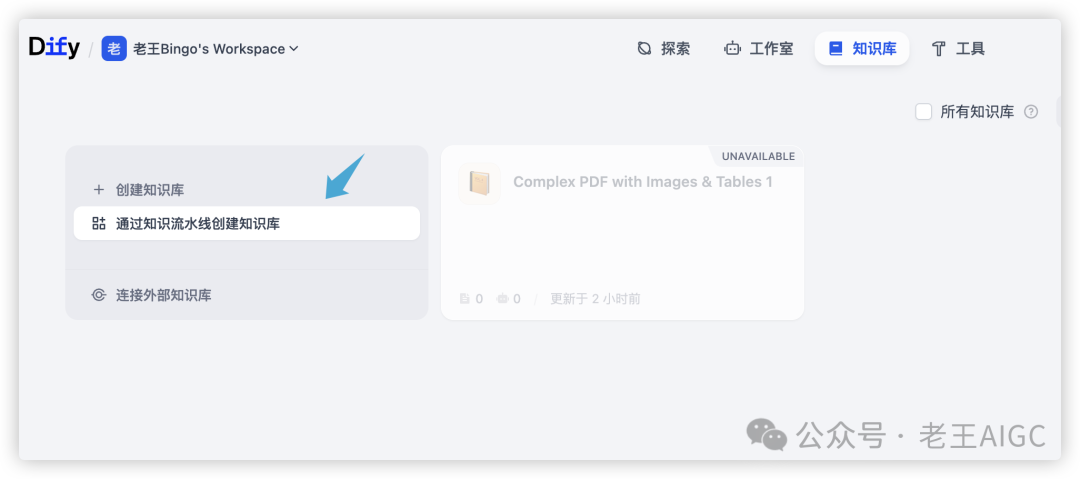
3.1 新建知识库
-
• 在Dify中创建新的知识库
-
• 选择"Knowledge Pipeline"模式
• 配置Embedding和Rerank模型
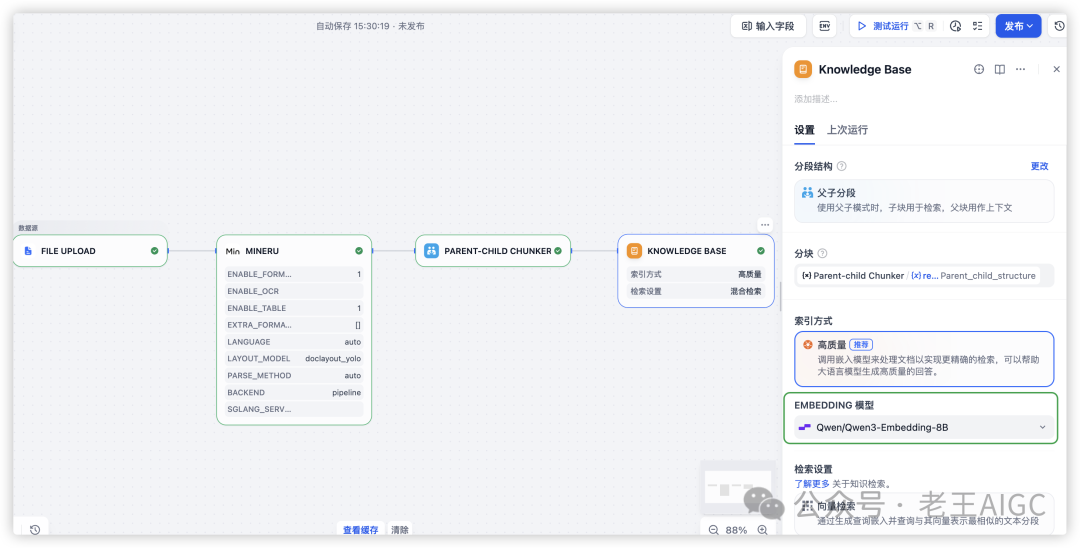
3.2 选择处理模板
选择"Complex PDF with Images & Tables"模板,该模板专为复杂文档设计:
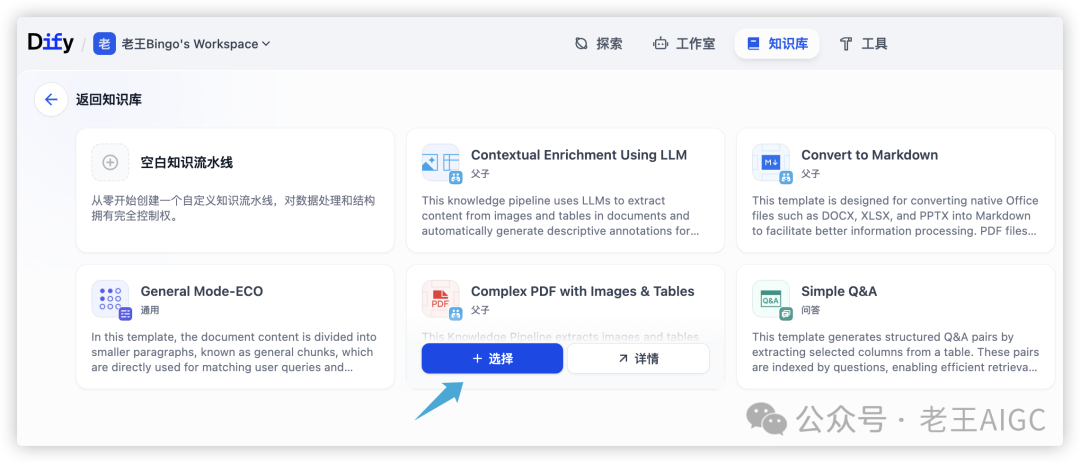
模板配置参数:
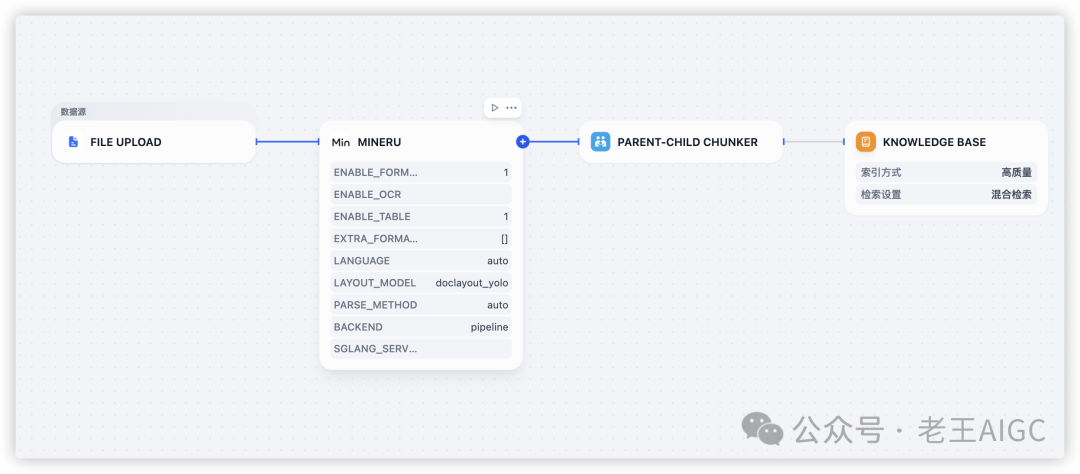
步骤4:配置处理流水线
4.1 MinerU节点配置
-
• 启用公式识别:提高数学公式处理精度
-
• 启用表格识别:确保表格结构完整保留
-
• 语言设置为"auto":自动识别文档语言
-
• 选择doclayout_yolo模型:获得最佳版面分析效果
4.2 Parent-Child分块配置
采用两层级信息访问机制:
-
• Parent块:保存完整上下文信息
-
• Child块:包含具体细节内容
-
• 平衡检索精度和内容完整性
4.3 知识库索引配置
-
• High-Quality模式:适合对准确性要求极高的场景
-
• Economical模式:适合大批量文档处理
步骤5:测试和调试
5.1 单步测试
-
• 上传测试文档(建议选择包含图表的PDF)
-
• 点击"测试运行"执行单个节点
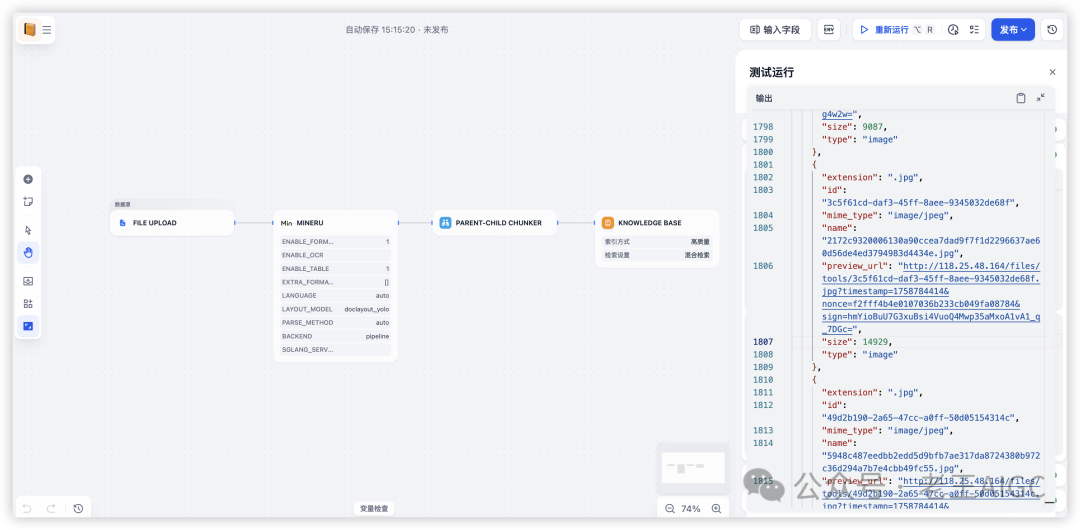
-
• 检查MinerU输出的图像URL是否可访问
5.2 变量检查
在变量检查器中查看:
-
•
text:解析后的Markdown文本 -
•
images:提取的图像URL列表 -
•
json:结构化的内容数据 -
•
files:额外格式文件(如HTML、DOCX)
5.3 预览效果
使用Markdown预览功能查看最终输出效果,确保图像正确嵌入。
步骤6:发布和应用
6.1 发布流水线
测试无误后,点击"发布"使流水线生效。
6.2 批量处理
上传多个文档进行批量处理,系统会自动:
-
• 提取所有图像并生成URL
-
• 保持文档结构和格式
-
• 创建可检索的知识条目
🎯 效果展示:10分钟搭建图表检索工作流
工作流架构设计
我们来搭建一个简单的知识库检索工作流,演示如何让AI"看懂"文档中的图表:
用户输入问题
知识库检索节点
LLM处理节点
返回结果
Knowledge Pipeline知识库
检索到的文本+图片URL
智能分析+格式化输出
实战演示步骤
第1步:创建测试知识库
-
1. 选择"Complex PDF with Images & Tables"模板
-
2. 上传包含图表的PDF文档(如财务报告、学术论文、数据分析报告)
第2步:搭建检索工作流
-
1. 创建新的工作流应用
-
2. 添加以下节点:
开始节点配置:
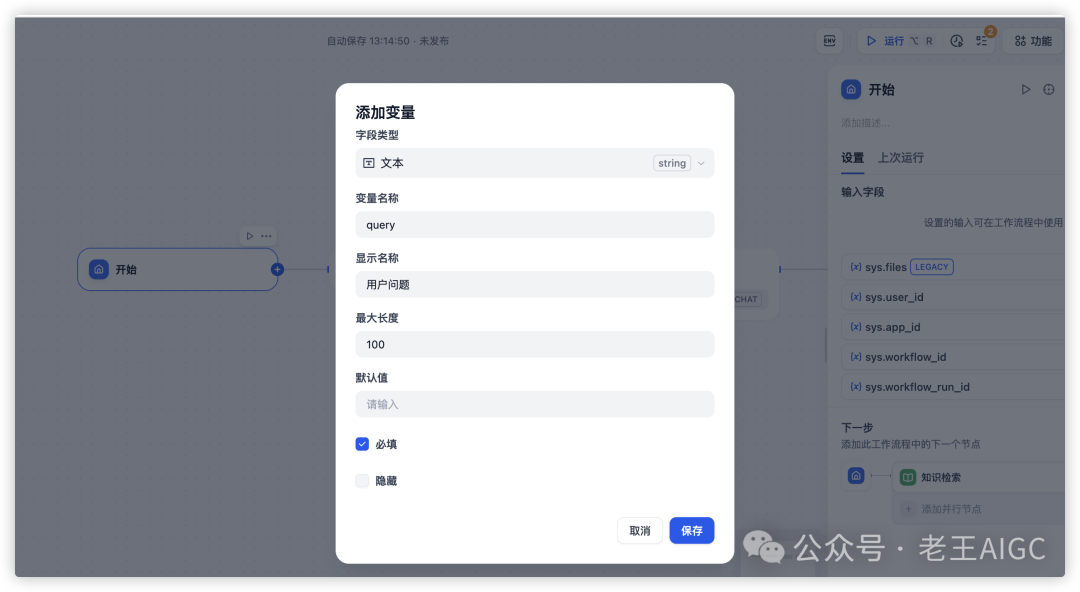
知识库检索节点配置:
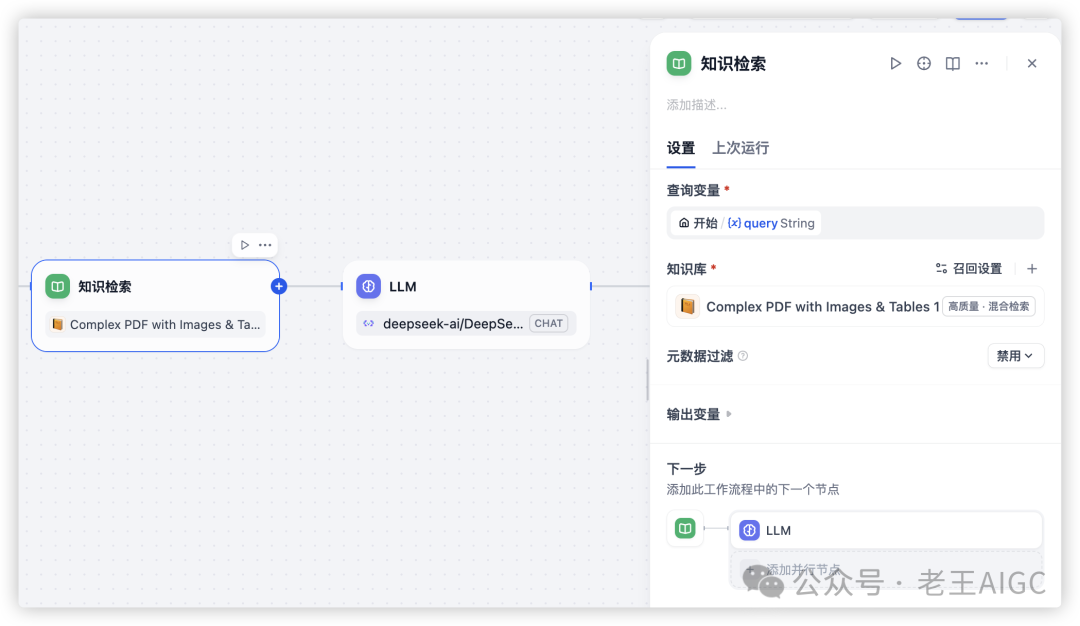
LLM节点提示词模板:
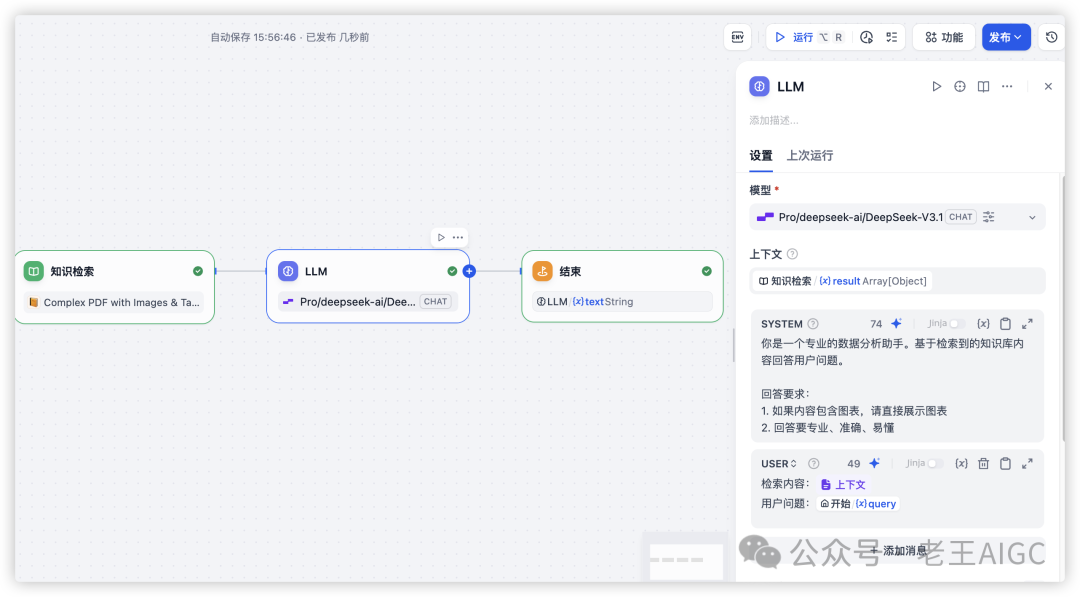
第3步:测试效果
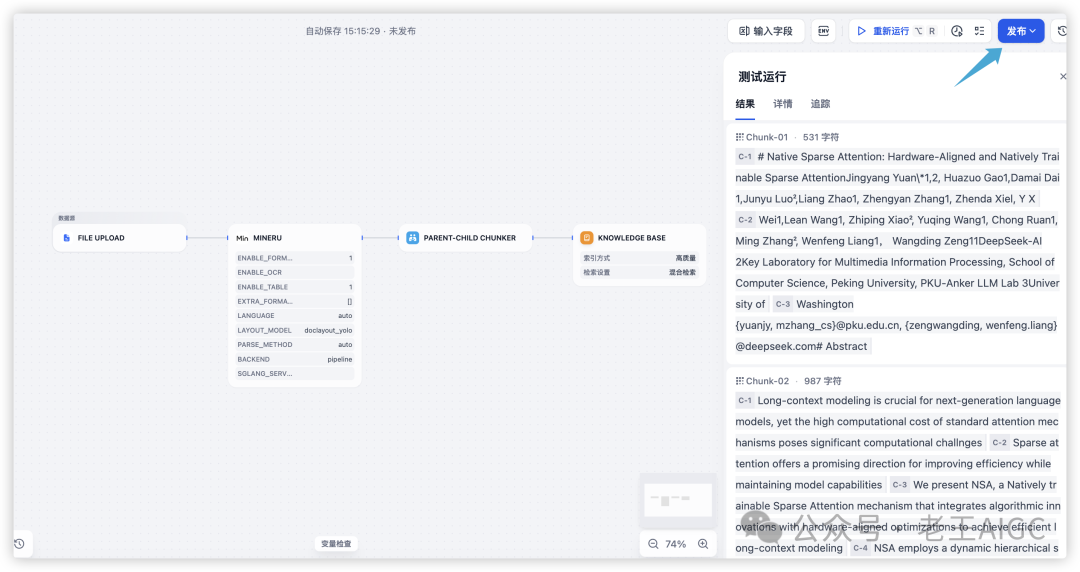
测试问题,因为上传的是英文文档,输入: "Comparison of performance and efficiency between Ful Attention model and our NSA"
系统返回:
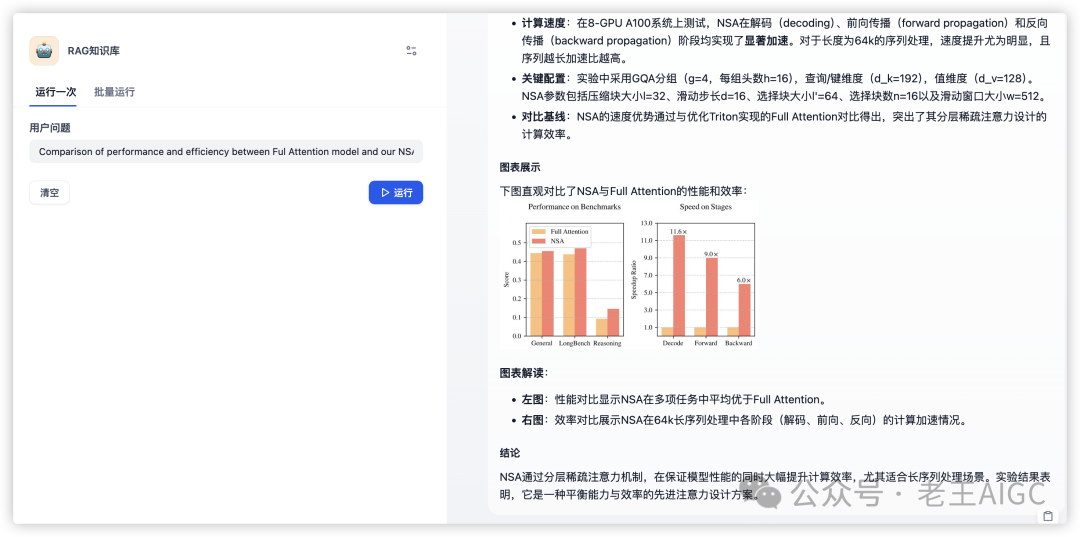
核心优势对比
| 功能特性 | 传统RAG | Knowledge Pipeline |
|---|---|---|
| 图表识别 | ❌ 无法处理 | ✅ 精准识别 |
| 图片URL | ❌ 不支持 | ✅ 自动生成 |
| 混合输出 | ❌ 纯文本 | ✅ 文本+图片 |
| 处理速度 | 🐌 较慢 | 🚀 提升500% |
❓ FAQ常见问题解答
Q1:图像URL无法访问怎么办?
A:检查FILES_URL配置,确保使用Dify API地址而非Minio外网地址。同时确认FILES_ACCESS_TIMEOUT设置合理的过期时间。
Q2:支持哪些文档格式?
A:支持PDF、DOC、DOCX、PPT、PPTX、PNG、JPG、JPEG等主流格式,基本覆盖日常办公需求。
Q3:如何提高图像提取准确率?
A:建议使用doclayout_yolo布局模型,启用OCR功能,并将语言设置为"auto"进行自动识别。
Q4:可以处理扫描版PDF吗?
A:完全支持!MinerU具备强大的OCR能力,支持84种语言的扫描文档识别。
Q5:如何优化大批量文档处理速度?
A:使用批处理功能,合理配置GPU加速,选择Economical索引模式可显著提升处理效率。
📚 推荐阅读
🎉 总结
Dify 1.9.0的Knowledge Pipeline功能真正实现了多模态RAG的突破,通过MinerU工具的强大解析能力,让AI助手具备了"看图说话"的能力。无论是技术文档、学术论文还是商业报告,都能得到完整准确的理解和回答。
立即行动建议:
-
1. 升级到Dify 1.9.0版本
-
2. 安装配置MinerU插件
-
3. 创建你的第一个图像提取流水线
-
4. 体验多模态RAG的强大威力
这不仅仅是技术升级,更是AI应用场景的重大扩展。从今天开始,让你的AI助手真正"看懂"世界!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









