




 本文深入探讨了Apache Flink中的GROUPINGSETS功能,它允许在GROUPBY查询中进行多维度组合的聚合,并展示了如何在代码中实现。同时,文章也介绍了TTL(Time To Live)机制,用于限制状态的生存时间以防止资源耗尽,但可能会影响统计准确性。
本文深入探讨了Apache Flink中的GROUPINGSETS功能,它允许在GROUPBY查询中进行多维度组合的聚合,并展示了如何在代码中实现。同时,文章也介绍了TTL(Time To Live)机制,用于限制状态的生存时间以防止资源耗尽,但可能会影响统计准确性。
文章目录
1. GROUPING SETS
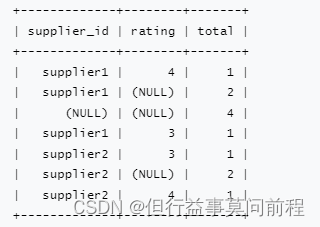
在一个GROUP BY 查询中,根据不同的维度组合进行聚合。GROUPING SETS就是一种将多个GROUP BY逻辑UNION在一起。GROUPING SETS会把在单个GROUP BY逻辑中没有参与GROUP BY的那一列置为NULL值。空分组集意味着所有行都聚合到一个组中
SELECT supplier_id, rating, COUNT(*) AS total
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS ((supplier_id, rating), (supplier_id), ())
代码实例:
public class TableExample {
public static void main(String[] args) throws Exception {
// 获取流执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











