




 本文详细介绍了Apache Flink的状态管理,包括有状态计算的概念、状态的分类(托管状态、原始状态、算子状态和按键分区状态)及其使用,如值状态、列表状态、映射状态、归约状态和聚合状态。此外,还讲解了状态的生存时间(TTL)和算子状态的实现,以及状态持久化和状态后端,如检查点、状态后端(HashMapStateBackend和EmbeddedRocksDBStateBackend)的配置与选择。
本文详细介绍了Apache Flink的状态管理,包括有状态计算的概念、状态的分类(托管状态、原始状态、算子状态和按键分区状态)及其使用,如值状态、列表状态、映射状态、归约状态和聚合状态。此外,还讲解了状态的生存时间(TTL)和算子状态的实现,以及状态持久化和状态后端,如检查点、状态后端(HashMapStateBackend和EmbeddedRocksDBStateBackend)的配置与选择。
文章目录
1. Flink 中的状态
1.1 有状态算子
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果
有状态的算子任务,除当前数据外,还需要一些其他数据来得到计算结果。
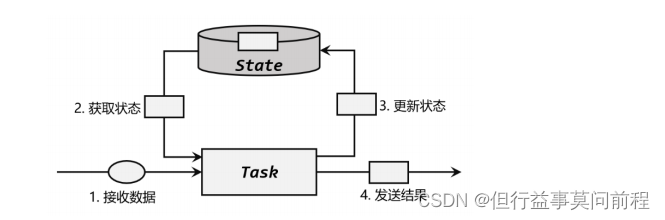
最常见的状态(state),就是之前到达的数据,或者由之前数据计算出的某个结果
如:
sum计算时,需要保存之前所有数据的和;窗口算子中会保存已经到达的所有数据;检索先有下单行为,后有支付行为的事件模式(event pattern),也应该把之前的行为保存下来
1.2 状态的管理
Flink 将状态直接保存在内存中来保证性能,并通过分布式扩展来提高吞吐量。Flink 有一套完整的状态管理机制,将底层一些核心功能全部封装起来,包括状态的高效存储和访问、持久化保存和故障恢复,以及资源扩展时的调整
------ 状态的访问权限。 Flink 上的聚合和窗口操作,一般都是基于 KeyedStream的,数据会按照 key 的哈希值进行分区,聚合处理的结果只对当前 key 有效。然而同一个分区( slot)上执行的任务实例,可能会包含多个 key 的数据,它们同时访问和更改本地变量,就会导致计算结果错误
------ 容错性,也就是故障后的恢复。状态只保存在内存中显然是不够稳定的,需要将它持久化保存,做一个备份;在发生故障后可以从这个备份中恢复状态
------ 分布式应用的横向扩展性。处理的数据量增大时,相应地对计算资源扩容,调大并行度。这时就涉及到了状态的重组调整
1.3 状态的分类
1.3.1 托管状态(Managed State)和原始状态(Raw State)
托管状态就是由 Flink 统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由 Flink 实现;而原始状态则是自定义的,相当于就是开辟了一块内存,需要自己管理,实现状态的序列化和故障恢复
托管状态是由 Flink 的运行时(Runtime)来托管的;在配置容错机制后,状态会自动持久化保存,并在发生故障时自动恢复。当应用发生横向扩展时,状态也会自动地重组分配到所有的子任务实例上。对于具体的状态内容,Flink 提供了值状态(ValueState)、列表状态(ListState)、映射状态(MapState)、聚合状态(AggregateState)等多种结构,内部支持各种数据类型。聚合、窗口等算子中内置的状态,都是托管状态;也可以在富函数类(RichFunction)中通过上下文来自定义状态
原始状态全部需要自定义。Flink 不会对状态进行任何自动操作,也不知道状态的具体数据类型,只会把它当作最原始的字节(Byte)数组来存储
所以只有在遇到托管状态无法实现的特殊需求时,才会考虑使用原始状态;绝大多数应用场景,用 Flink 提供的算子或者自定义托管状态来实现需求
1.3.2 算子状态(Operator State)和按键分区状态(Keyed State)
将托管状态分为两类:算子状态和按键分区状态
(1)算子状态(Operator State)
状态作用范围限定为当前的算子任务实例,只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个“分区”,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的

算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别——因为本
地变量的作用域也是当前任务实例。在使用时,需进一步实现 CheckpointedFunction 接口
(2)按键分区状态(Keyed State)
状态是根据输入流中定义的键(key)来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,也就 keyBy 之后才可以使用
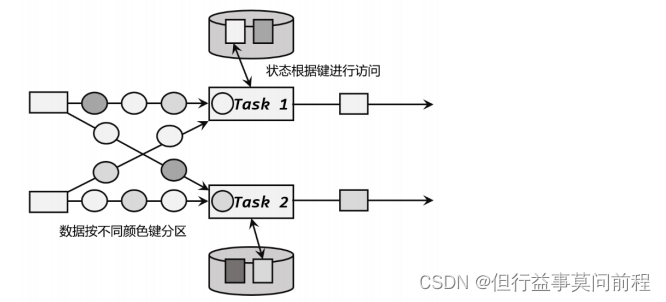
2. 按键分区状态(Keyed State)
2.1 概念
因为一个并行子任务可能会处理多个 key 的数据,所以 Flink 需要对 Keyed State 进行一些特殊优化。在底层,Keyed State 类似于一个分布式的映射(map)数据结构,所有的状态会根据 key 保存成键值对(key-value)的形式。这样当一条数据到来时,任务就会自动将状态的访问范围限定为当前数据的 key,从 map 存储中读取出对应的状态值。所以具有相同 key 的所有数据都会到访问相同的状态,而不同 key 的状态之间是彼此隔离的
在应用的并行度改变时,状态也需要随之进行重组。不同 key 对应的 Keyed State可以进一步组成所谓的键组(key groups),每一组都对应着一个并行子任务。键组是 Flink 重新分配 Keyed State 的单元,键组的数量就等于定义的最大并行度。当算子并行度发生改变时,Keyed State 就会按照当前的并行度重新平均分配,保证运行时各个子任务的负载相同
2.2 支持的结构类型
2.2.1 值状态(ValueState)
public interface ValueState<T> extends State {
T value() throws IOException;
void update(T value) throws IOException;
}
T value():获取当前状态的值;
update(T value):对状态进行更新,传入的参数 value 就是要覆写的状态值
在具体使用时,为了让运行时上下文清楚到底是哪个状态,需要创建一个状态描述器(StateDescriptor)来提供状态的基本信息

代码
使用用户 id 来进行分流,然后分别统计每个用户的 pv 数据,隔一段时间发送 pv 的统计结果
public class PeriodicPvExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream.print("input");
// 统计每个用户的 pv,隔一段时间(10s)输出一次结果
stream.keyBy(data -> data.user)
.process(new PeriodicPvResult())
.print();
env.execute();
}
// 注册定时器,周期性输出 pv
public static class PeriodicPvResult extends KeyedProcessFunction<String, Event, String> {
ValueState<Long> countState;
ValueState<Long> timerTsState;
@Override
public void open(Configuration parameters) throws Exception {
countState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("count", Long.class));
timerTsState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("timerTs", Long.class));
}
@Override
public void processElement(Event value, Context ctx, Collector<String> out) throws Exception {
// 更新 count 值
Long count = countState.value();
if (count == null) {
countState.update(1L);
} else {
countState.update(count + 1);
}
// 注册定时器
if (timerTsState.value() == null) {
ctx.timerService().registerEventTimeTimer(value.timestamp + 10 * 1000L);
timerTsState.update(value.timestamp + 10 * 1000L);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
out.collect(ctx.getCurrentKey() + " pv: " + countState.value());
// 清空状态
timerTsState.clear();
}
}
}
2.2.2 列表状态(ListState)
将需要保存的数据,以列表(List)的形式组织起来
Iterable<T> get():获取当前的列表状态,返回的是一个可迭代类型 Iterable<T>;
update(List<T> values):传入一个列表 values,直接对状态进行覆盖;
add(T value):在状态列表中添加一个元素 value;
addAll(List<T> values):向列表中添加多个元素,以列表 values 形式传入
代码:
两条流的全量 Join,SELECT * FROM A INNER JOIN B WHERE A.id = B.id;
public class TwoStreamFullJoinExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple3<String, String, Long>> stream1 = env.fromElements(
Tuple3.of("a", "stream-1", 1000L),
Tuple3.of("b", "stream-1", 2000L)
)
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> t, long l) {
return t.f2;
}
})
);
SingleOutputStreamOperator<Tuple3<String, String, Long>> stream2 = env.fromElements(
Tuple3.of("a", "stream-2", 3000L),
Tuple3.of("b", "stream-2" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5486
5486


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










