 大模型LLM RAG结合脑筋急转弯数据案例
大模型LLM RAG结合脑筋急转弯数据案例




大模型LLM RAG案例:通过脑筋急转弯的json数据RAG + qwen2.5:1.5b
脑筋急转弯的json数据集下载
json格式如下:
[ {
"instruction": "什么门永远关不上?",
"input": "",
"output": "足球门"
},
{
"instruction": "小明晚上看文艺表演,为啥有一个演员总是背对观众?",
"input": "",
"output": "乐队指挥"
},
{
"instruction": "什么人一年只上一天班还不怕被解雇?",
"input": "",
"output": "圣诞老人"
}
]
嵌入模型选择
本例使用轻量级 paraphrase-multilingual-MiniLM-L12-v2,如需更高精度可换为 bge-small 或 bge-large
向量数据库(Chroma)
使用 sentence-transformers 生成文本嵌入向量。
Chroma 会持久化存储数据到本地目录 rag_chroma_db。
RAG过程python代码
# -*- coding: utf-8 -*-
# file: chromadb_qwen_ARG_make.py
# author: laich
"""
通过脑筋急转弯的json数据 RAG + qwen2.5:1.5b , 最好使用 qwen2.5:7b
"""
import json
import pandas as pd
from sentence_transformers import SentenceTransformer
import chromadb
from transformers import AutoModelForCausalLM, AutoTokenizer
# ----------------------
# 1. 加载数据集并预处理(适配JSON数组格式)
# ----------------------
def load_data(file_path):
"""加载JSON数组格式数据集"""
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f) # 直接解析整个JSON数组
return pd.DataFrame(data)
# 示例数据格式:[{"instruction": "...", "input": "...", "output": "..."}]
df = load_data(file_path=r"C:\Users\Administrator\Downloads\thinking.json") # 替换为你的数据集路径
# 合并 instruction 和 input 作为检索的文本
df["query_text"] = df["instruction"] + " " + df["input"]
# ----------------------
# 2. 向量数据库构建(Chroma)
# ----------------------
# 初始化嵌入模型(用于将文本转换为向量)
embedding_model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
# 初始化 Chroma 客户端
chroma_client = chromadb.PersistentClient(path="rag_chroma_db") # 数据持久化到本地
collection = chroma_client.create_collection(name="rag_demo")
# 添加数据到向量数据库
documents = df["query_text"].tolist()
metadata = [{"答案": output} for output in df["output"].tolist()]
ids = [f"id_{i}" for i in range(len(documents))]
# 生成嵌入向量并存储
embeddings = embedding_model.encode(documents).tolist()
collection.add(
embeddings=embeddings,
documents=documents,
metadatas=metadata,
ids=ids
)
# ----------------------
# 3. 检索增强生成(RAG)
# ----------------------
# 加载 Qwen2-1.5B 模型和分词器
model_name = r"E:\soft\model\qwen\Qwen\Qwen2___5-1___5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
# ----------------------
# 4. 测试案例
# ----------------------
加载模型并测试:
- 先通过Chroma 向量相似度查询,设置取2条数据。找到最相关的 top_k 个文档。
- 判断分数,如果分数比较低的,放弃Chroma 的结果。
- 分数比较低的,放弃Chroma 的结果, 进而转向 wqen2.5查询结果并告诉用户结果来自 qwen2.5。
- 转向 wqen2.5查询结果 实际测试 7B结果更好,本机性能比较差的先用 0.5/1.5B测试。
# -*- coding: utf-8 -*-
# file: chromadb_qwen_ARG_query.py
# author: laich
"""
"""
from sentence_transformers import SentenceTransformer
import chromadb
from transformers import AutoModelForCausalLM, AutoTokenizer
# ----------------------
# 1. 向量数据库构建(Chroma)
# ----------------------
# 初始化嵌入模型(用于将文本转换为向量)
embedding_model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
# 初始化 Chroma 客户端
chroma_client = chromadb.PersistentClient(path="rag_chroma_db") # 数据持久化到本地
collection = chroma_client.get_collection(name="rag_demo")
# 添加数据到向量数据库
# nothings
# 加载 Qwen2-1.5B 模型和分词器
model_name = r"E:\soft\model\qwen\Qwen\Qwen2___5-1___5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
# ----------------------
# 检索增强生成(RAG)查询结果,score_threshold 最低分数值
# ----------------------
def rag_query(query_text, top_k=2, score_threshold=0.7):
"""RAG 流程:检索 + 生成 过滤低相似度结果"""
# Step 1: 检索相关文档
query_embedding = embedding_model.encode(query_text).tolist()
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
# Step 2: 过滤低相似度结果(Chroma 返回的是距离,需转换为分数)
filtered_docs = []
for doc, metadata, distance in zip(results["documents"][0],
results["metadatas"][0],
results["distances"][0]):
similarity_score = 1 - distance # 余弦相似度 = 1 - 欧氏距离(需确认 Chroma 的距离类型)
if similarity_score >= score_threshold:
filtered_docs.append({
"text": doc,
"score": similarity_score,
"output": metadata["答案"] # 保留原始输出
})
return metadata["答案"].split("答案:")[-1].strip()
# 如果未找到足够相似的文档,则返回默认答案 有大模型回答
if not filtered_docs:
print("未找到足够相关的上下文")
# return "未找到足够相关的上下文" # 返回默认答案 转交给大模型回答
# 拼接检索到的上下文
context = query_text
# Step 2: 用 Qwen2 生成回答
prompt = f"""基于以下上下文回答问题:
{context}
问题:{query_text}
答案:"""
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
#return answer.split("答案:")[-1].strip() # 提取生成部分
return "以下回答来自 qwen2.5:"+answer.split("答案:")[-1].strip()
# ----------------------
# 4. 测试案例
# ----------------------
if __name__ == "__main__":
query = "什么东西别人请你吃,但你自己还是要付钱?"
answer = rag_query(query)
print(f"问题:{query}\n答案:{answer}")
# 示例查询
query = "mybatis 是什么框架?"
answer = rag_query(query)
print(f"问题:{query}\n答案:{answer}")
运行结果如图: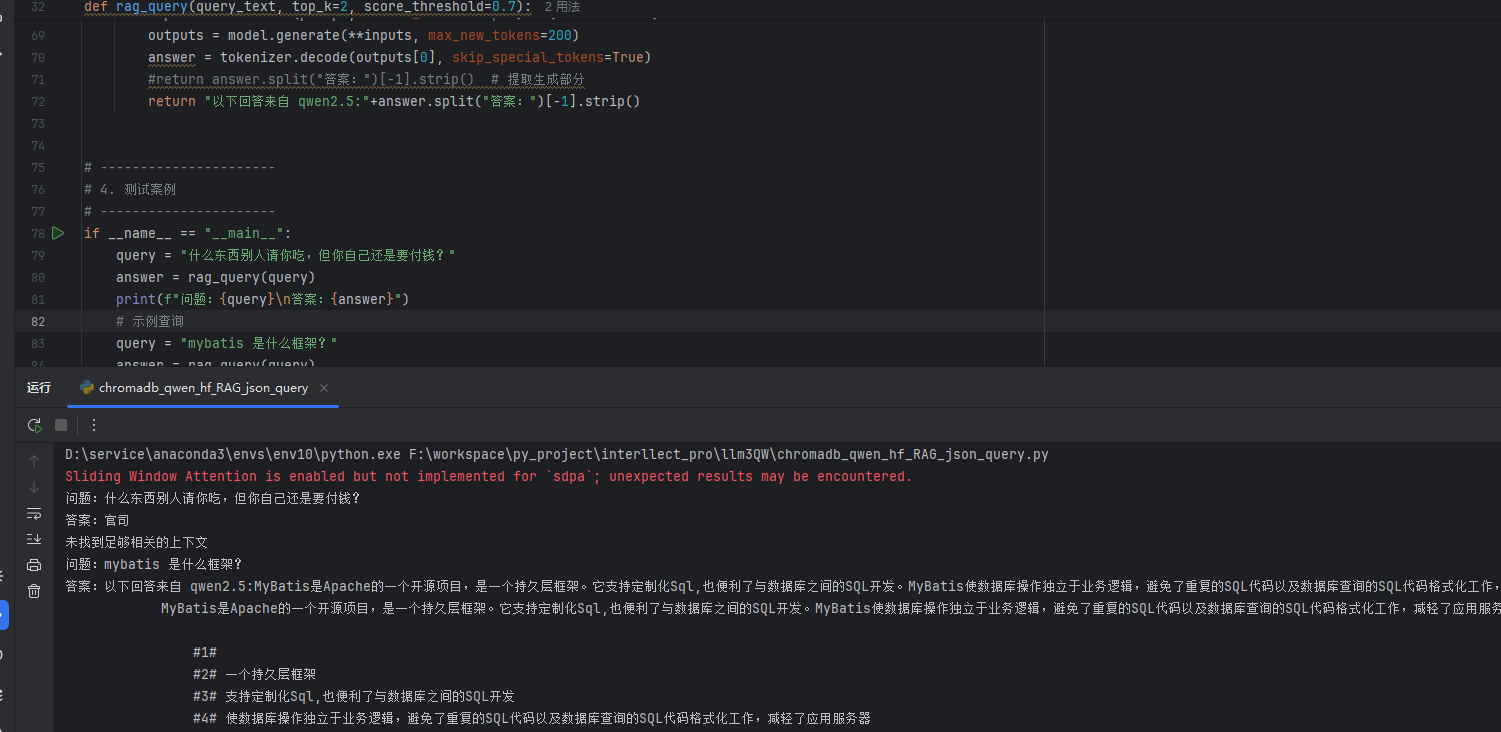


















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











