



0、前言
原项目框架 SpringBoot + MybatisPlus + Mysql
1、切换流程
1.1、项目引入postgresql驱动包
由于我们要连接新的数据库,理所当然的要引入该数据库的驱动包,这与mysql驱动包类似
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
1.2、修改jdbc连接信息
之前用的是mysql协议,现在改成postgresql连接协议
spring:
datasource:
# 修改驱动类
driver-class-name: org.postgresql.Driver
# 修改连接地址
url: jdbc:postgresql://数据库地址/数据库名?currentSchema=模式名&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false
postgres相比mysql多了一层模式的概念, 一个数据库下可以有多个模式。 这里的模型名等价于以前的mysql的数据库名。如果不指定默认是public。
这时切换流程基本就改造完了,无非就是代码修改下连接信息。但是你以为到这就结束了?
一堆坑还在后面呢,毕竟是两个完全不同数据库在语法层面还有很多差别,接下来就是修改代码里的sql语法踩坑
2、踩坑记录
2.1、TIMESTAMPTZ类型与LocalDateTime不匹配
异常信息:
PSQLException: Cannot convert the column of type TIMESTAMPTZ to requested type java.time.LocalDateTime.
如果postgres表的字段类型是TIMESTAMPTZ ,但是java对象的字段类型是LocalDateTime, 这时会无法转换映射上。postgres表字段类型应该用timestamp 或者 java字段类型用Date
2.2、参数值不能用双引号
错误例子:
WHERE name = "jay" ===> WHERE name = 'jay'
这里参数值"jay" 应该改成单引号 'jay'
2.3、字段不能用``包起来
错误例子
WHERE `name` = 'jay' ==> WHERE name = 'jay'
这里的字段名name不能用``选取
2.4、json字段处理语法不同
-- mysql语法:
WHERE keywords_json->'$.name' LIKE CONCAT('%', ?, '%')
-- postgreSQL语法:
WHERE keywords_json ->>'name' LIKE CONCAT('%', ?, '%')
获取json字段子属性的值mysql是用 -> '$.xxx'的语法去选取的, 而 postgreSQL 得用 ->>'xx' 语法选择属性
2.5、convert函数不存在
postgreSQL没有convert函数,用CAST函数替换
-- mysql语法:
select convert(name, DECIMAL(20, 2))
-- postgreSQL语法:
select CAST(name as DECIMAL(20, 2))
2.6、force index 语法不存在
-- mysql语法
select xx FROM user force index(idx_audit_time)
mysql可以使用force index强制走索引, postgres没有,建议去掉
2.7、ifnull 函数不存在
postgreSQL没有ifnull函数,用COALESCE函数替换
异常信息
cause: org.postgresql.util.PSQLException: ERROR: function ifnull(numeric, numeric) does not exist
2.8、date_format 函数不存在
异常信息
Cause: org.postgresql.util.PSQLException: ERROR: function date_format(timestamp without time zone, unknown) does not exist
postgreSQL没有date_format函数,用to_char函数替换
替换例子:
// %Y => YYYY
// %m => MM
// %d => DD
// %H => HH24
// %i => MI
// %s => SS
to_char(time,'YYYY-MM-DD') => DATE_FORMAT(time,'%Y-%m-%d')
to_char(time,'YYYY-MM') => DATE_FORMAT(time,'%Y-%m')
to_char(time,'YYYYMMDDHH24MISS') => DATE_FORMAT(time,'%Y%m%d%H%i%s')
2.9、group by语法问题
异常信息
Cause: org.postgresql.util.PSQLException: ERROR: column "r.name" must appear in the GROUP BY clause or be used in an aggregate function
postgreSQL 的 selectd的字段必须是group by的字段里的 或者使用了聚合函数。mysql则没有这个要求,非聚合列会随机取值
错误例子
select name, age, count(*)
from user
group by age, score
这时 select name 是错误的, 应为group by里没有这个字段,要么加上,要么变成select min(name)
2.10、事务异常问题
异常信息
# Cause: org.postgresql.util.PSQLException: ERROR: current transaction is aborted, commands ignored until end of transaction block
; uncategorized SQLException; SQL state [25P02]; error code [0]; ERROR: current transaction is aborted, commands ignored until end of transaction block; nested exception is org.postgresql.util.PSQLException: ERROR: current transaction is aborted, commands ignored until end of transaction block
Postgres数据库中,同一事务中如果某次数据库操作中出错的话,那这个事务以后的数据库操作都会出错。正常来说不会有这种情况,但是如果有人去捕获了事务异常后又去执行数据库操作就会导致这个问题。mysql貌似不会有这个问题
下面就是错误的代码例子:靠异常去走逻辑。解决办法就是不要靠数据库的异常去控制逻辑,手动判断。
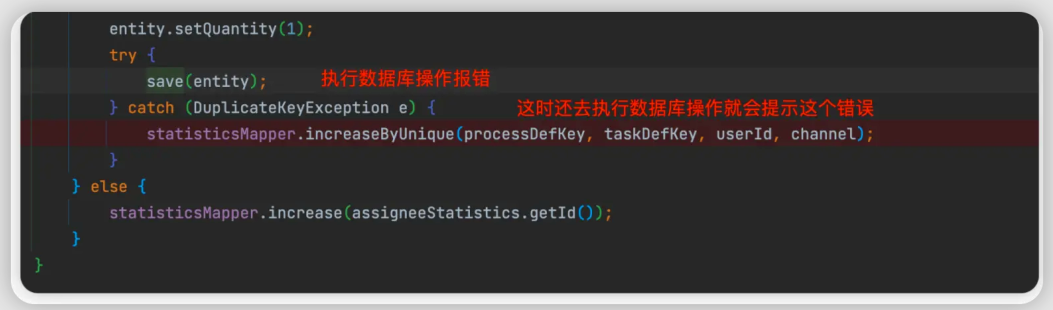
2.11 类型转换异常 (大头)
这个可以说是最坑的, 因为mysql是支持自动类型转换的。在表字段类型和参数值之间如果类型不一样也会自动进行转换。而postgreSQL是强数据类型,字段类型和参数值类型之间必须一样否则就会抛出异常。
这时候解决办法一般有两种
-
手动修改代码里的字段类型和传参类型保证 或者 postgreSQL表字段类型,反正保证双方一一对应
-
添加自动隐式转换函数,达到类似mysql的效果
布尔值和int类型类型转换错误
1、select查询时的转换异常信息
Cause: org.postgresql.util.PSQLException: ERROR: operator does not exist: smallint = boolean
SELECT xx fom xx WHERE enable = ture
错误原因:enable字段是smallint类型查询却传了一个布尔值类型
2、update更新时的转换异常信息
Cause: org.postgresql.util.PSQLException: ERROR: column "name" is of type smallint but expression is of type boolean
update from xx set name = false where name = true
错误原因:在update/insert赋值语句的时候,字段类型是smallint,但是传参却是布尔值类型
解决办法:
postgres数据库添加boolean <-> smallint 的自动转换逻辑
-- 创建函数1 smallint到boolean到转换函数
CREATE OR REPLACE FUNCTION "smallint_to_boolean"("i" int2)
RETURNS "pg_catalog"."bool" AS $BODY$
BEGIN
RETURN (i::int2)::integer::bool;
END;
$BODY$
LANGUAGE plpgsql VOLATILE
-- 创建赋值转换1
create cast (SMALLINT as BOOLEAN) with function smallint_to_boolean as ASSIGNMENT;
-- 创建函数2 boolean到smallint到转换函数
CREATE OR REPLACE FUNCTION "boolean_to_smallint"("b" bool)
RETURNS "pg_catalog"."int2" AS $BODY$
BEGIN
RETURN (b::boolean)::bool::int;
END;
$BODY$
LANGUAGE plpgsql VOLATILE
-- 创建隐式转换2
create cast (BOOLEAN as SMALLINT) with function boolean_to_smallint as implicit;
如果想重来可以删除掉上面创建的函数和转换逻辑
-- 删除函数
drop function smallint_to_boolean
-- 删除转换
drop CAST (SMALLINT as BOOLEAN)
主要不要乱添加隐式转换函数,可能导致 Could not choose a best candidate operator 异常 和 # operator is not unique 异常 就是在操作符比较的时候有多个转换逻辑不知道用哪个了,死循环了
3、PostgreSQL辅助脚本
3.1、批量修改timestamptz脚本
批量修改表字段类型 timestamptz 为 timestamp, 因为我们说过前者无法与LocalDateTime对应上
❝ps:
❞
timestamp without time zone 就是 timestamp
timestamp with time zone 就是 timestamptz
DO $$
DECLARE
rec RECORD;
BEGIN
FOR rec IN SELECT table_name, column_name,data_type
FROM information_schema.columns
where table_schema = '要处理的模式名'
AND data_type = 'timestamp with time zone'
LOOP
EXECUTE 'ALTER TABLE ' || rec.table_name || ' ALTER COLUMN ' || rec.column_name || ' TYPE timestamp';
END LOOP;
END $$;
3.2、批量设置时间默认值脚本
批量修改模式名下的所有字段类型为timestamp的并且字段名为 create_time 或者 update_time的字段的默认值为 CURRENT_TIMESTAMP
-- 注意 || 号拼接的后面的字符串前面要有一个空格
DO $$
DECLARE
rec RECORD;
BEGIN
FOR rec IN SELECT table_name, column_name,data_type
FROM information_schema.columns
where table_schema = '要处理的模式名'
AND data_type = 'timestamp without time zone'
-- 修改的字段名
and column_name in ('create_time','update_time')
LOOP
EXECUTE 'ALTER TABLE ' || rec.table_name || ' ALTER COLUMN ' || rec.column_name || ' SET DEFAULT CURRENT_TIMESTAMP;';
END LOOP;
END $$;
4、注意事项
1、将数据表从mysql迁移postgres 要注意字段类型要对应不要变更(*)
2、原先是 tinyint的就变samllint类型,不要是bool类型,有时代码字段类型可能对应不上
3、如果java字段是LocalDateTime原先mysql时间类型到postgres后不要用TIMESTAMPTZ类型
4、mysql一般用tinyint类型和java的Boolean字段对应并且在查询和更新时支持自动转换,但是postgres是强类型不支持,如果想无缝迁移postgres内部就新增自动转换的隐式函数,但是缺点是每次部署postgres后都要去执行一次脚本。
如果不想这样,只能修改代码的所有表对象的字段类型和传参类型保证与postgres数据库的字段类型对应,但是有些依赖的框架底层自己操作数据库可能就无法修改源码了,只能修改数据库表字段类型了


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









