



前言
假设你的系统里有100万个用户,然后你要轮询重试的获取每个用户的身份信息, 如果你还在使用SpringRetry和GuavaRetry 之类的这种单任务的同步重试框架,那你可能到猴年马月也处理不完,即使加再多的机器和线程也是杯水车薪,而Fast-Retry正是为这种场景而生。
Fast-Retry
一个高性能的多任务重试框架,支持百万级任务的异步重试、以及支持编程式和注解声明式等多种使用方式、 也支持自定义结果重试逻辑。
What is this?
与主流的Spring-Retry、Guava-Retry等单任务同步重试框架不同,Fast-Retry是一个支持异步重试框架,支持异步任务的重试、超时等待、回调。
Spring-Retry、Guava-Retry均无法支持大批量任务的重试,即使加入线程池也无法解决,因为实际每个重试任务都是单独的同步逻辑,然后会会占用过多线程资源导致大量任务在等待处理,随着任务数的增加,系统吞吐量大大降低,性能指数级降低,而Fast-Retry在异步重试下的性能是前者的指数倍。
下图是三者的性能对比
-
测试线程池: 8个固定线程
-
单个任务逻辑: 轮询5次,隔2秒重试一次,总耗时10秒
-
未测预计公式:当我们使用线程池的时候, 一般线程池中 总任务处理耗时 = 任务数/并发度 x 单个任务重试耗时
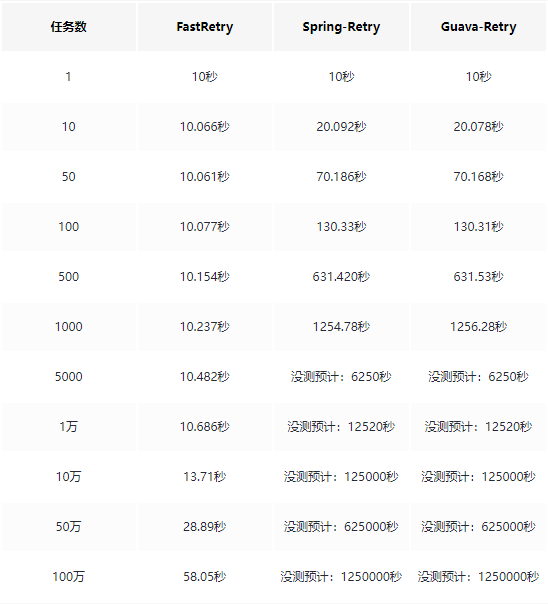
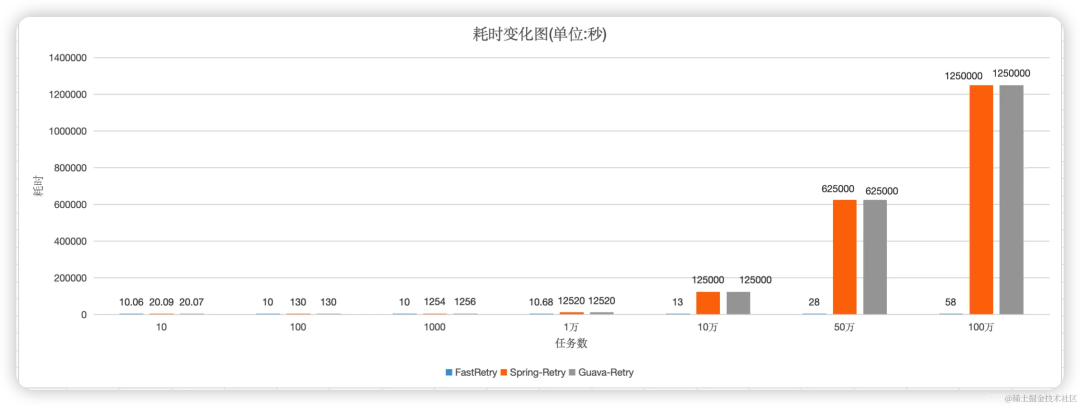
可以看到即使是处理100万个任务,Fast-Retry的性能也比Spring-Retry和Guava-Retry处理在50个任务时的性能还要快的多的多属实降维打击,这么快的秘密在于除了是异步,重要的是当别人在重试间隔里休息的时候,Fast-Retry还在不停忙命的工作着。
即使抛开性能不谈,SpringRetry使用繁琐,不支持根据结果的进行重试,GuavaRetry虽然支持,但是又没有提供注解声明式的使用。
快速开始
引入依赖
<dependency>
<groupId>io.github.burukeyou</groupId>
<artifactId>fast-retry-all</artifactId>
<version>0.2.0</version>
</dependency>
有以下三种方式去构建我们的重试任务
使用重试队列
RetryTask就是可以配置我们重试任务的一些逻辑,比如怎么重试,怎么获取重试结果,隔多久后重试,在什么情况下重试。它可以帮助我们更加自由的去构建重试任务的逻辑。但如果只是简单使用,强烈建议使用FastRetryBuilder 或者 @FastRetry注解
RetryQueue就是一个执行和调度我们重试任务的核心角色,其在使用上与线程池的API方法基本一致
ExecutorService executorService = Executors.newFixedThreadPool(8);
RetryQueue queue = new FastRetryQueue(executorService);
RetryTask<String> task = new RetryTask<String>() {
int result = 0 ;
// 下一次重试的间隔
@Override
public long waitRetryTime() {
return 2000;
}
// 执行重试,每次重试回调此方法
@Override
public boolean retry() {
return ++result < 5;
}
// 获取重试结果
@Override
public String getResult() {
return result + "";
}
};
CompletableFuture<String> future = queue.submit(task);
log.info("任务结束 结果:{}",future.get());
使用FastRetryBuilder
底层还是使用的RetryQueue去处理, 只是帮我们简化了构建RetryTask的逻辑
RetryResultPolicy<String> resultPolicy = result -> result.equals("444");
FastRetryer<String> retryer = FastRetryBuilder.<String>builder()
.attemptMaxTimes(3)
.waitRetryTime(3, TimeUnit.SECONDS)
.retryIfException(true)
.retryIfExceptionOfType(TimeoutException.class)
.exceptionRecover(true)
.resultPolicy(resultPolicy)
.build();
CompletableFuture<String> future = retryer.submit(() -> {
log.info("重试");
//throw new Exception("test");
//int i = 1/0;
if (0 < 10){
throw new TimeoutException("test");
}
return "444";
});
String o = future.get();
log.info("结果{}", o);
使用@FastRetry注解
底层还是使用的RetryQueue去处理, 只是帮我们简化了构建RetryTask的逻辑,并且与Spring进行整合能对Spring的bean标记了FastRetry注解的方法进行代理, 提供了重试任务注解声明式的使用方式
-
依赖Spring环境,所以需要在Spring配置类加上
@EnableFastRetry注解启用配置,这个@FastRetry注解的使用才会生效 -
如果将结果类型使用
CompletableFuture包装,自动进行异步轮询返回,否则同步阻塞等待重试结果。(推荐)
下面定义等价于RetryQueue.execute方法
// 如果发生异常,每隔两秒重试一次
@FastRetry(retryWait = @RetryWait(delay = 2))
public String retryTask(){
return "success";
}
下面定义等价于 RetryQueue.submit方法,支持异步轮询
@FastRetry(retryWait = @RetryWait(delay = 2))
public CompletableFuture<String> retryTask(){
return CompletableFuture.completedFuture("success");
}
自定义重试注解
如果不喜欢或者需要更加通用化的贴近业务的重试注解,提供一些默认的参数和处理逻辑,可以自行定义一个重试注解并标记上@FastRetry并指定factory,然后实现AnnotationRetryTaskFactory接口实现自己的构建重试任务的逻辑即可。@FastRetry默认实现就是:FastRetryAnnotationRetryTaskFactory
使用建议
无论是使用以上哪种方式去构建你的重试任务,都建议使用异步重试的方法,即返回结果是CompletableFuture的方法, 然后使用CompletableFuture的whenComplete方法去等待异步重试任务的执行结果。
其他
github项目地址
https://github.com/burukeYou/fast-retry
maven仓库地址
https://central.sonatype.com/artifact/io.github.burukeyou/fast-retry-all


















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









