







一、本文介绍
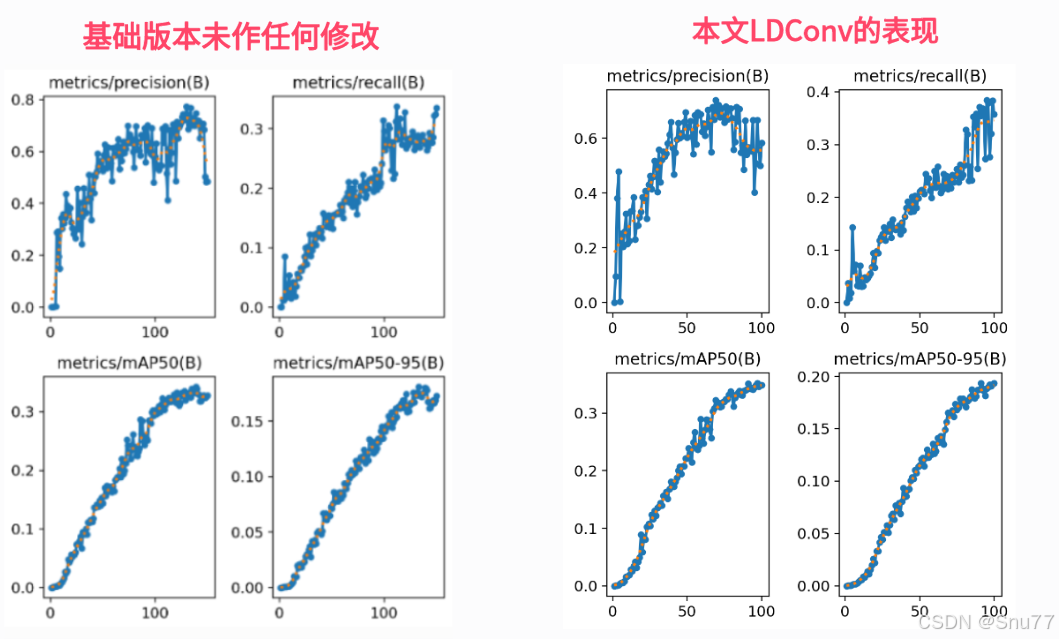
本文给大家带来的最新改进机制是利用2024最新的线性可变形卷积LDConv替换YOLOv11的传统下采样操作(值得一提的是这个作者和RFAConv是同一个作者),介绍了一种新型的卷积操作——线性可变形卷积(LDConv)。LDConv 旨在解决标准卷积操作的局限性,标准卷积在固定形状和大小的局部窗口中进行采样,难以动态适应不同物体的形状。可变形卷积(Deformable Conv)虽然允许灵活的采样位置,但其参数数量随着卷积核大小呈平方增长,计算效率较低。LDConv 提供了比可变形卷积更大的灵活性,允许卷积核的参数数量呈线性增长,从而克服了可变形卷积参数数量平方增长的问题,该方法可以起到轻量化的作用。
欢迎大家订阅我的专栏一起学习YOLO!
目录
二、原理介绍

官方论文地址: 官方论文地址点击此处即可跳转
官方代码地址: 官方代码地址点击此处即可跳转

这篇文章题为《LDConv: 用于改进卷积神经网络的线性可变形卷积》

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 3935
3935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











