







 该专栏为热销专栏榜 第22名
该专栏为热销专栏榜 第22名一、本文介绍
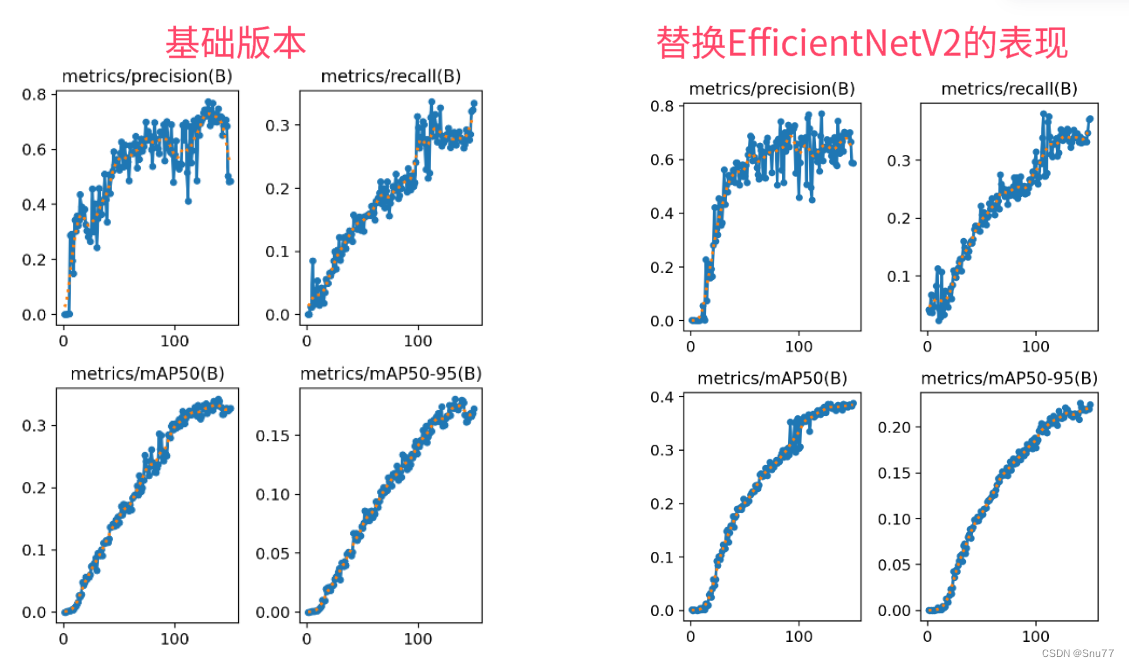
这次给大家带来的改进机制是EfficientNetV2,其在其V1版本通过均衡地缩放网络的深度、宽度和分辨率,以提高卷积神经网络的性能的基础上,又提出了一种改进的渐进式学习方法,通过在训练过程中逐步增加图像尺寸并适应性调整正则化来加快训练速度,同时保持准确性。所以其相对于V1版本的改进主要是在速度和效率上的改进(但是经过我实验我觉得V2不如V1快,可能是我使用的不是同一等级的版本,大家也可以进行一下对比)。本文通过介绍其主要框架原理,然后教大家如何添加该网络结构到网络模型中。
(本文内容可根据yolov11的N、S、M、L、X进行二次缩放,轻量化更上一层)。
目录

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2057
2057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











