







一、本文介绍
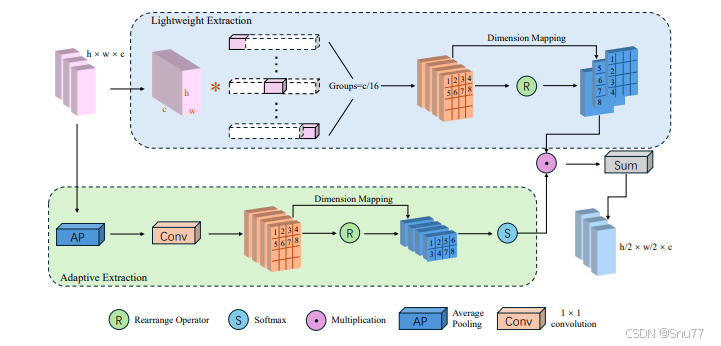
本文给大家带来的一个改进机制是最新由LSM-YOLO提出的轻量化自适应特征提取(Lightweight Adaptive Extraction, LAE)模块,其是LSM-YOLO模型中的关键模块,旨在进行多尺度特征提取,同时降低计算成本。LAE通过以下方式实现更有效的特征提取:多尺度特征提取、自适应特征提取。LAE模块可以在不增加额外参数的情况下提高了模型对ROI区域的检测性能。
欢迎大家订阅我的专栏一起学习YOLO!
目录
二、LAE结构介绍
官方论文地址: 官方论文地址点击此处即可跳转
官方代码地址: 官方代码地址点击此处即可跳转


 订阅专栏 解锁全文
订阅专栏 解锁全文


















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











