




 该专栏为热销专栏榜 第12名
该专栏为热销专栏榜 第12名 本文详细介绍了如何利用MobileNetV2的反转残差结构和线性瓶颈层改进RT-DETR。通过去除狭窄层的非线性,保持模型在轻量化的同时提升性能。此外,还讲解了SSDLite框架在移动目标检测中的应用。文中提供了核心代码修改步骤,帮助读者理解并实践MobileNetV2在网络结构中的应用。
本文详细介绍了如何利用MobileNetV2的反转残差结构和线性瓶颈层改进RT-DETR。通过去除狭窄层的非线性,保持模型在轻量化的同时提升性能。此外,还讲解了SSDLite框架在移动目标检测中的应用。文中提供了核心代码修改步骤,帮助读者理解并实践MobileNetV2在网络结构中的应用。
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
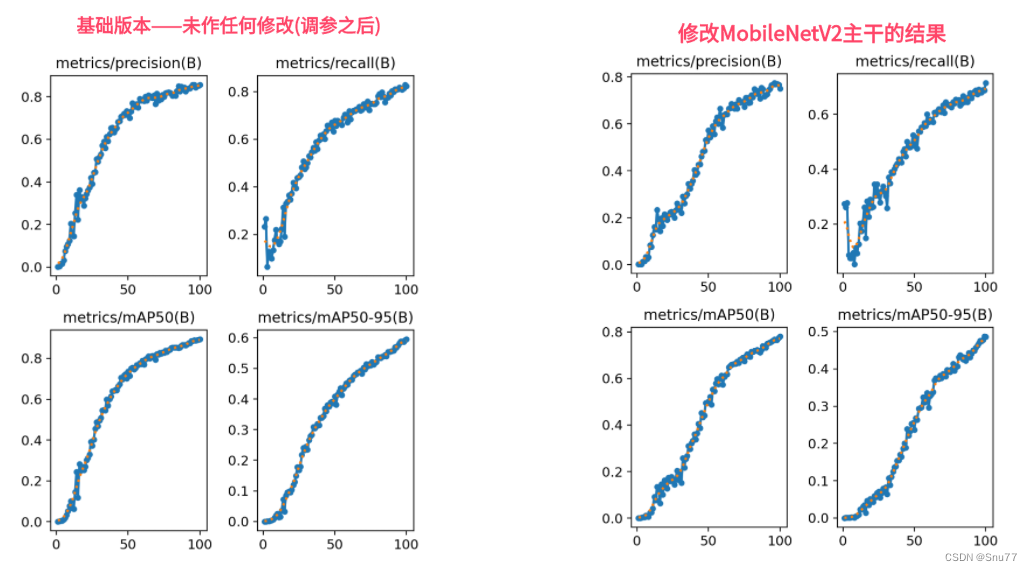
本文给大家带来的改进机制是MobileNetV2,其是专为移动和嵌入式视觉应用设计的轻量化网络结构。其在MobilNetV1的基础上采用反转残差结构和线性瓶颈层。这种结构通过轻量级的深度卷积和线性卷积过滤特征,同时去除狭窄层中的非线性,以维持表征能力。MobileNetV2在性能上和精度上都要比V1版本强很多,其在多种应用(如对象检测、细粒度分类、面部属性识别和大规模地理定位)中都展现了一定的有效性,这个模型大家看图片可以看出非常明显的上升趋势,但是我只训练了100epochs,但是如果可以加大一些轮次让其完全收敛估计精度差不多,但是MobileNetV2参数相对于ResNet18下降了百分之五十!。
目录
二、MobileNetV2的框架原理

官方论文地址:官方论文地址
官方代码地址:官方代码地址


 订阅专栏 解锁全文
订阅专栏 解锁全文


















 3543
3543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











