







 该专栏为热销专栏榜 第6名
该专栏为热销专栏榜 第6名 本文深入探讨YOLOv8的DAT改进,即Vision Transformer with Deformable Attention,介绍了DAT的主要思想、网络结构及与传统机制的对比。通过实践展示了DAT在目标检测任务中的应用,并提供了即插即用的代码块,指导如何将DAT添加到网络中,以提升模型性能。
本文深入探讨YOLOv8的DAT改进,即Vision Transformer with Deformable Attention,介绍了DAT的主要思想、网络结构及与传统机制的对比。通过实践展示了DAT在目标检测任务中的应用,并提供了即插即用的代码块,指导如何将DAT添加到网络中,以提升模型性能。
一、本文介绍
本文给大家带来的是YOLOv8改进DAT(Vision Transformer with Deformable Attention)的教程,其发布于2022年CVPR2022上同时被评选为Best Paper,由此可以证明其是一种十分有效的改进机制,其主要的核心思想是:引入可变形注意力机制和动态采样点(听着是不是和可变形动态卷积DCN挺相似)。同时在网络结构中引入一个DAT计算量由8.9GFLOPs涨到了9.4GFLOPs。本文的讲解主要包含三方面:DAT的网络结构思想、DAttention的代码复现,如何添加DAttention到你的结构中实现涨点,下面先来分享我测试的对比图(因为资源有限,我只用了100张图片的数据集进行了100个epoch的训练,虽然这个实验不能产生确定性的结论,但是可以作为一个参考)。
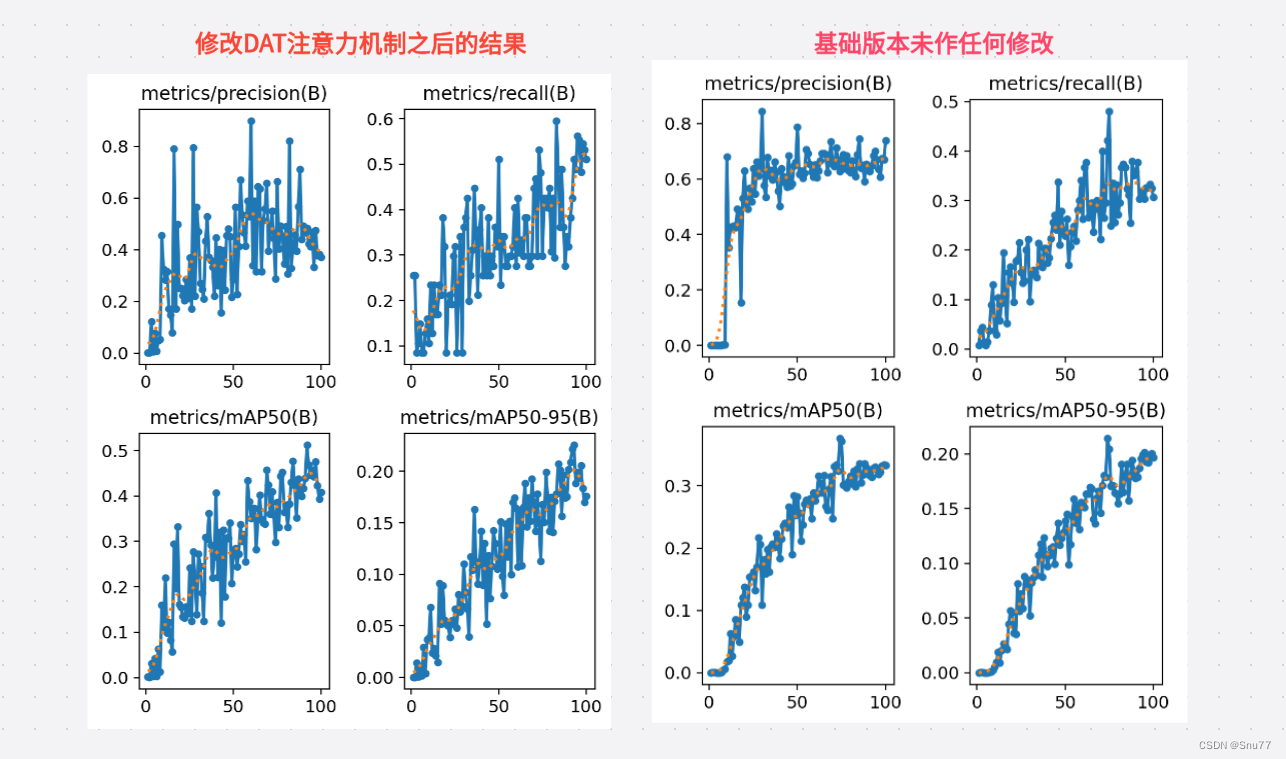
适用检测对象->各种检测目标都可以使用,并不针对于某一特定的目标有效。
目录
二、DAT的网络结构思想

论文地址: DAT论文地址
官方地址:官方代码的地址</

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











