




 本文分析了Kafka生产者在批量发送消息时的一个潜在问题,由于全局变量`drainIndex`导致部分TopicPartition的消息无法均衡发送。在极端情况下,这可能会使一些消息长时间滞留。提出了解决方案,即每个Node维护独立的遍历索引,以确保所有队列都能被正确遍历,从而避免消息发送延迟。
本文分析了Kafka生产者在批量发送消息时的一个潜在问题,由于全局变量`drainIndex`导致部分TopicPartition的消息无法均衡发送。在极端情况下,这可能会使一些消息长时间滞留。提出了解决方案,即每个Node维护独立的遍历索引,以确保所有队列都能被正确遍历,从而避免消息发送延迟。
最近在看Kafka生产者源码的时候, 感觉有个地方可以改进一下, 具体的问题和解决方案都在下面。
问题代码
RecordAccumulator#drainBatchesForOneNode
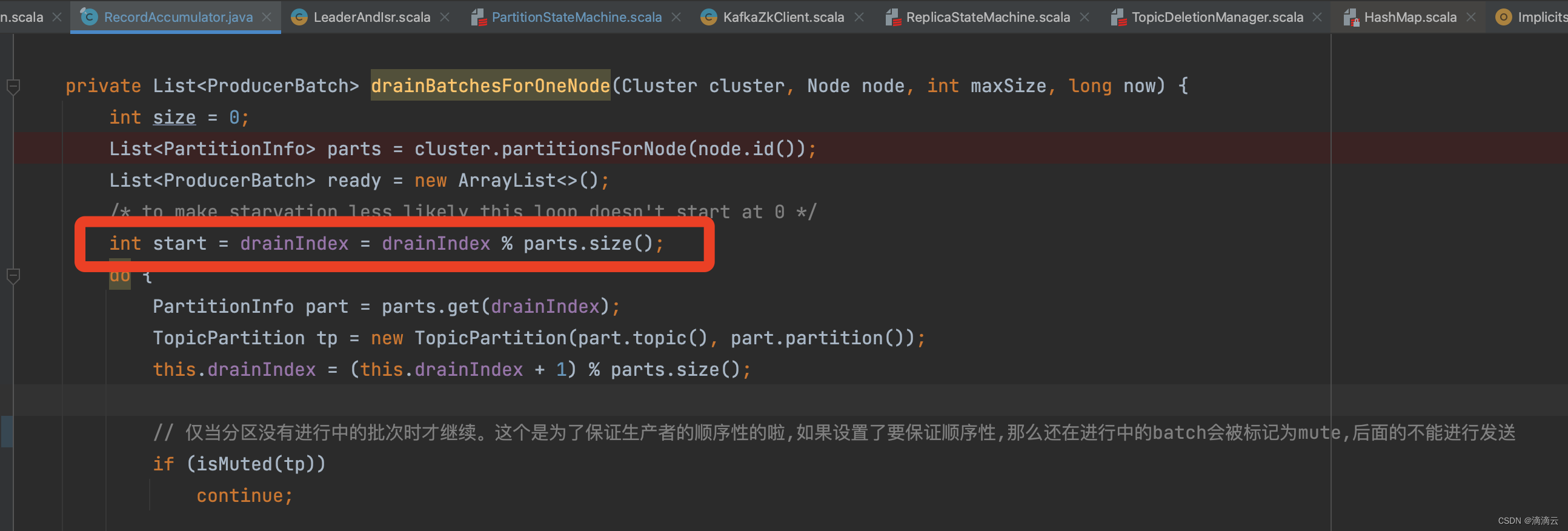
问题出在这个, private int drainIndex;
代码预期
这端代码的逻辑, 是计算出发往每个Node的ProducerBatchs,是批量发送。
因为发送一次的请求量是有限的(max.request.size), 所以一次可能只能发几个ProducerBatch. 那么这次发送了之后, 需要记录一下这里是遍历到了哪个Batch, 下次再次遍历的时候能够接着上一次遍历发送。
简单来说呢就是下图这样
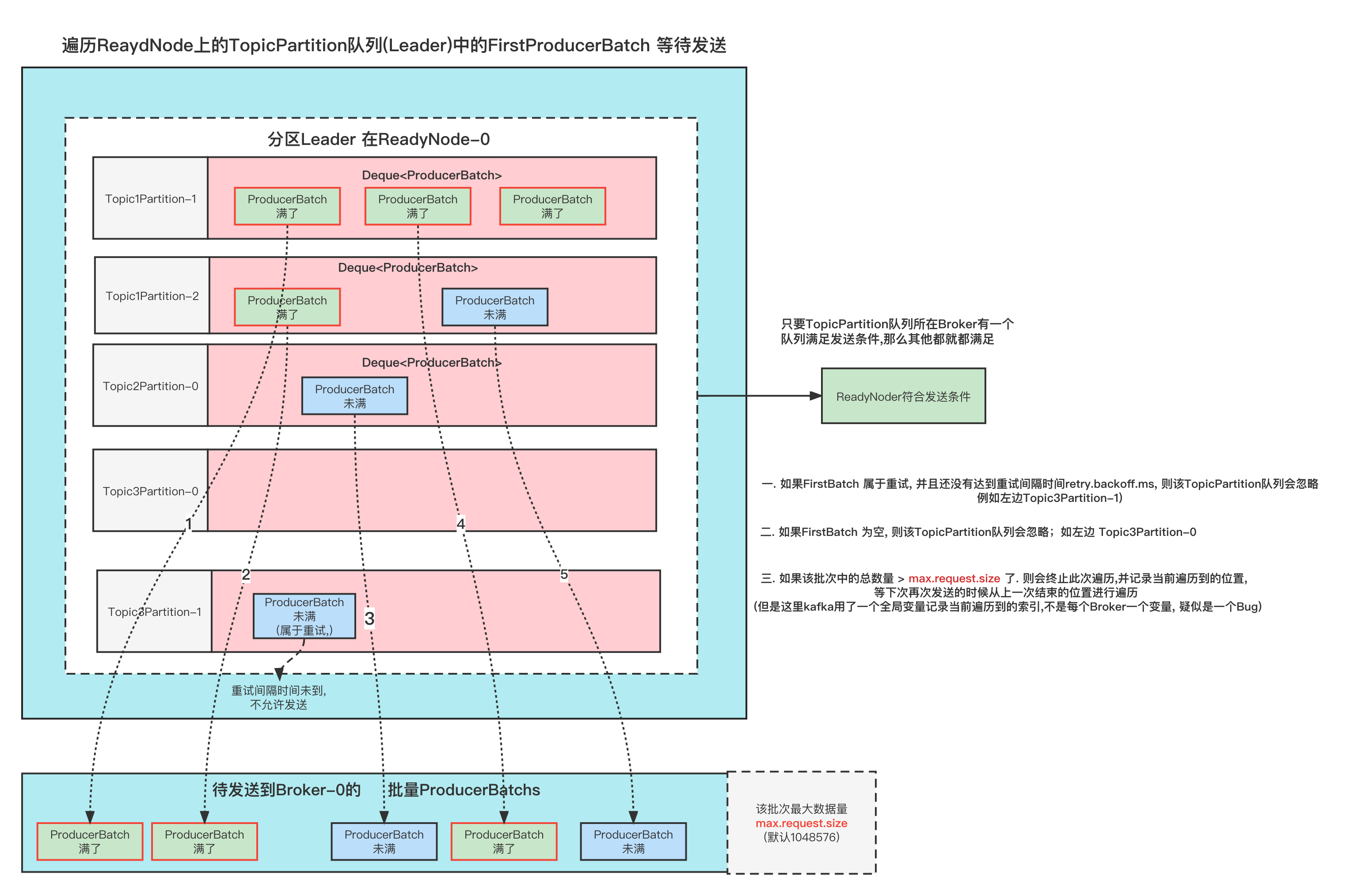
实际情况
但是呢, 因为上面的索引drainIndex 是一个全局变量, 是RecordAccumulator共享的。
那么通常会有很多个Node需要进行遍历, 上一个Node的索引会接着被第二个第三个Node接着使用,那么也就无法比较均衡合理的让每个TopicPartition都遍历到.
正常情况下其实这样也没有事情, 如果不出现极端情况的下,基本上都能遍历到。
怕就怕极端情况, 导致有很多TopicPartition不能够遍历到,也就会造成一部分消息一直发送不出去。
造成的影响
导致部分消息一直发送不出去、或者很久才能够发送出去。
触发异常情况的一个Case
该Case场景如下:
生产者向3个Node发送消息
每个Node都是3个TopicPartition
每个TopicPartition队列都一直源
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 1770
1770



 到【灌水乐园】发言
到【灌水乐园】发言







