 Pandas高级应用解析
Pandas高级应用解析





 本文深入探讨了Python数据分析库Pandas的高级应用,包括分类数据的处理、Groupby的高级用法以及链式编程技术。重点讲解了如何通过分类数据提高数据处理效率,Groupby在时间序列数据上的应用限制,以及如何利用DataFrame.assign和管道方法实现更简洁的代码编写。
本文深入探讨了Python数据分析库Pandas的高级应用,包括分类数据的处理、Groupby的高级用法以及链式编程技术。重点讲解了如何通过分类数据提高数据处理效率,Groupby在时间序列数据上的应用限制,以及如何利用DataFrame.assign和管道方法实现更简洁的代码编写。
《利用python进行数据分析》
第12章 pandas高级应用
12.1 分类数据
- 背景和目的
在数据仓库中,最好的方法是使用所谓的包含不同值的维表(Dimension Table),将主要的参数存储为引用维表整数键:
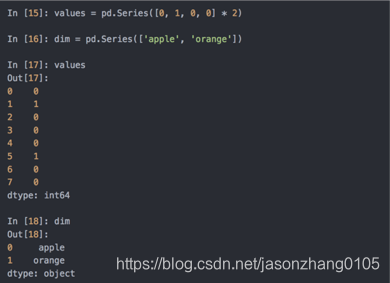
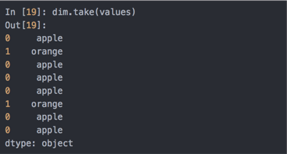
可以使用take方法存储原始的字符串Series:
- 用分类进行计算
Seed ( )方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数。
- 用分类提高性能
若数据的实际分类集超出了数据中的值,可以使用set_categories方法改变:
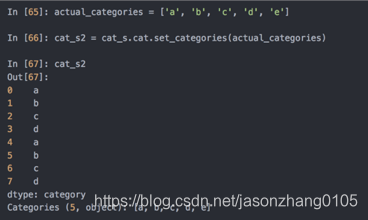
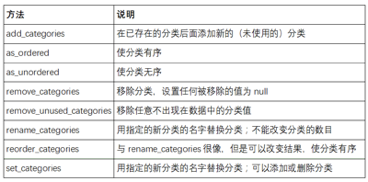
pandas的Series的分类方法:
12.2 Groupby高级应用
- 分组转换和“解封”GroupBy
使用TimeGrouper的限制是时间必须是Series或DataFrame的索引。
12.3 链式编程技术
DataFrame.assign方法是一个df[k] = v形式的函数式的列分配方法。它不是就地修改对象,而是返回新的修改过的DataFrame。
- 管道方法
需要使用自己的函数或第三方库的函数时要用到管道方法,当使用接收、返回series或DataFrame对象的函数式,需要调用pipe将其重写,f(df)和df.pipe(f)是等价的,但是pipe使得链式声明更容易。



















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









