




 本文介绍了如何利用Python进行数据分析,特别是模型构建。讨论了pandas在数据预处理中的作用,如何通过.values属性与NumPy数组交互。此外,详细讲解了Patsy库的公式语法,用于创建统计模型设计矩阵。接着,概述了statsmodels库,包括线性模型、时间序列分析等,并展示了如何拟合线性模型。最后,提到了scikit-learn,一个强大的机器学习库,提供了多种监督和非监督学习方法。
本文介绍了如何利用Python进行数据分析,特别是模型构建。讨论了pandas在数据预处理中的作用,如何通过.values属性与NumPy数组交互。此外,详细讲解了Patsy库的公式语法,用于创建统计模型设计矩阵。接着,概述了statsmodels库,包括线性模型、时间序列分析等,并展示了如何拟合线性模型。最后,提到了scikit-learn,一个强大的机器学习库,提供了多种监督和非监督学习方法。
第13章 Python建模库介绍
13.1 pandas于模型代码的接口
模型开发的通常工作流是使用pandas进行数据加载和清洗,然后切换到建模库进行建模。开发模型的重要一环是机器学习中的“特征工程”。它可以描述从原始数据集中提取信息的任何数据转换或分析,这些数据集可能在建模中有用。
pandas与其它分析库通常是靠NumPy的数组联系起来的。将DataFrame转换为NumPy数组,可以使用.values属性:

要转换回DataFrame,可以传递一个二维ndarray(N维数组的类型),可带有列名:

笔记:最好当数据是均匀的时候使用.values属性。例如,全是数值类型。如果数据是不均匀的,结果会是Python对象的ndarray:

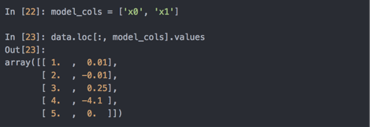
一些模型,可能只想使用列的子集,使用loc,用values作索引:
假设数据集中有一个非数值列:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









