




一、fork创建进程
使用fork函数创建一个进程
pid_t fork(void);
fork函数调用成功,返回两次
返回值为0, 代表当前进程是子进程
返回值非负数, 代表当前进程为父进程
调用失败,返回-1
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t pid;
printf("father id:%d\n",getpid());
//在没有调用fork函数之前先看一下进程号是多少
pid=fork();
//用pid接收fork的返回值
if(pid>0){
printf("this is father print,pid = %d\n",getpid());
}//做个判断验证一下fork函数创建的进程他们的返回值
else if(pid==0){
printf("this is child print,child pid is:%d\n",getpid());
}
return 0;
}

二、fork的返回值 以及 父子进程的数据交互方式
这里利用代码可以了解 父进程的返回值retpid正好是子进程的ID号
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t pid;
pid_t pid2;
pid_t retpid;
int data=10;
pid = getpid();
printf("before pid is:%d\n",pid);
retpid=fork();
//定义一个变量接收fork的返回值
pid2=getpid();
printf("after pid is:%d\n",pid2);
if(pid==pid2){
printf("this is father print,retpid is:%d\n",retpid);
}else{
printf("this is child print,child pid is:%d,retpid is:%d\n",getpid(),retpid);
data+=10;
}
printf("data is:%d\n",data);
return 0;
}
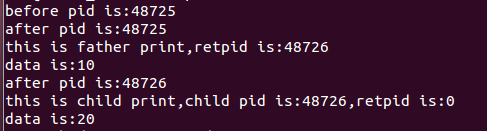
同时 在这里我们利用data的值还证明了一个问题 在旧的Linux系统中的copy方式为 全copy 新的 则为copy on write 如果子进程对值有做修改 则copy相应的值修改 如果没有则为共享数据原则
三、fork创建子进程的一般目的
(1)一个父进程希望复制自己,使父、子进程同时执行不同的代码段。
这在网络服务进程中是常见的——父进程等待客服端的服务请求。当这种请求到达时,父进程调用fork,使子进程处理此请求。父进程则继续等待下一个服务请求到达。
这里做个代码模拟一下场景
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t pid;
int data;
while(1){
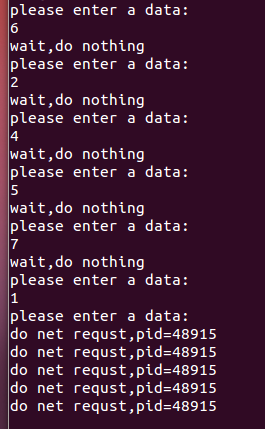
printf("please enter a data:\n");
scanf("%d",&data);
if(data==1){//当输入为1时创建进程
pid=fork();
if(pid>0){
//父进程闲置
}
else if(pid==0){
while(1){
printf("do net requst,pid=%d\n",getpid());
//子进程打印自己的进程id号
sleep(3); //间隔3秒
}
}
}
else{
printf("wait,do nothing\n"); //输入其他数字 反馈信息
}
}
return 0;
}
(2)一个进程要执行一个不同的程序。这对shell是常见的情况。在这种情况下,子进程从fork返回后立即调用exec。
总结
由fork创建的新进程被称为子进程(child process)。fork函数被调用一次,但返回两次。两次返回的唯一区别是子进程的返回值是0,而父进程的返回值是新子进程的进程ID。
子进程和父进程继续执行fork调用之后的指令。子进程是父进程的副本。例如,子进程获得父进程数据空间、堆和栈的副本。
由于在fork之后经常跟随着exec,所以现在的很多实现并不执行一个父进程数据段、栈和堆的完全复制。作为替代,使用了写时复制(Copy-On-Write,COW)技术。这些区域由父、子进程共享,而且内核将它们的访问权限改变为只读的。

















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









