




最近工作的时候发现一个问题:测试在跑sysbench threads的时候,发现小核所用的时间远远小于大核(小核cpu0~cpu5,大核cpu6~cpu7)。
小核只需要12.59s跑完以上测试,而大核却需要192s。
| taskset -c 7 ./sysbench --test=threads run | Running the test with following options: Threads fairness: |
| taskset -c 3 ./sysbench --test=threads run | sysbench: multi-threaded system evaluation benchmark Running the test with following options: Threads started! General statistics: Threads fairness: |
1.sysbench 介绍
GitHub - akopytov/sysbench: Scriptable database and system performance benchmark
上述的taskset -c 7 ./sysbench --test=threads run 最终会使用到:
int threads_execute_event(sb_event_t *sb_req, int thread_id)
{
unsigned int i;
sb_threads_request_t *threads_req = &sb_req->u.threads_request;
(void) thread_id; /* unused */
for(i = 0; i < thread_yields; i++)
{
pthread_mutex_lock(&test_mutexes[threads_req->lock_num]);
YIELD();
pthread_mutex_unlock(&test_mutexes[threads_req->lock_num]);
}
return 0;
}
这里面涉及到这yield的操作了。
2.yield操作
在操作系统内核中,YIELD()是一种机制,用于主动放弃当前线程的 CPU 时间片,从而允许其他线程运行。它通常被用来优化调度器的行为,在某些情况下可以减少不必要的上下文切换开销。
在 Linux 内核中,YIELD()并不是一个独立的函数名称,而是通过 schedule() 或者类似的调度接口来间接实现。以下是其核心逻辑:
-
当一个线程调用了类似于 yield 的行为时,该线程会被标记为可运行状态并重新加入就绪队列。
-
随后,调度程序会选择另一个合适的线程继续执行,而不是强制让当前线程保持占用 CPU。
3.使用火焰图分析

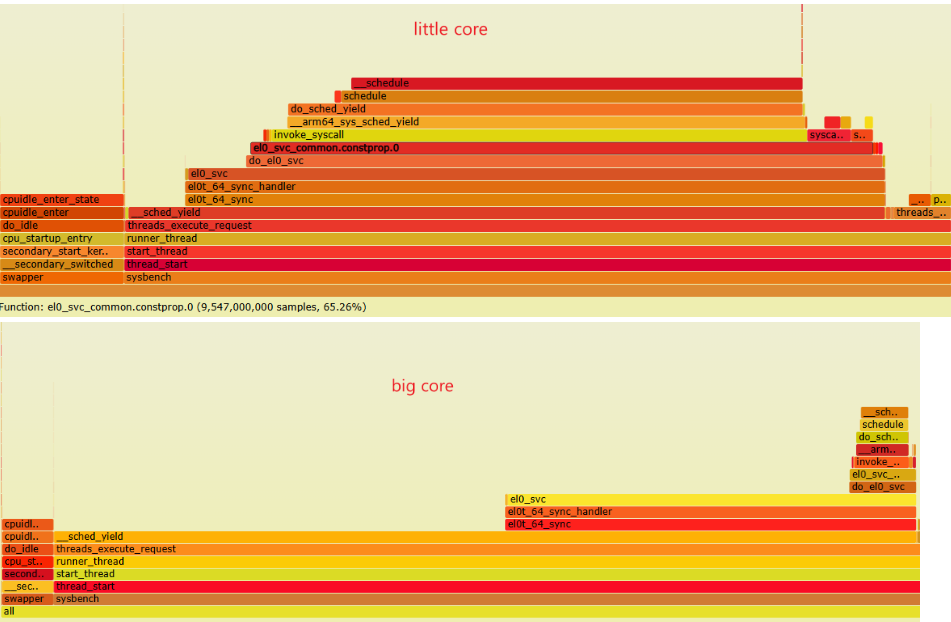
从火焰图中也可以看出big core 上的__shed_yield 时间消耗的比较多。

















 1571
1571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









