




 本文深入探讨了Java并发编程中的核心容器与框架,包括ConcurrentHashMap的锁分段技术、ConcurrentLinkedQueue的非阻塞算法,以及各种阻塞队列的特性与应用场景。同时,解析了Fork/Join框架的工作窃取算法和设计原理。
本文深入探讨了Java并发编程中的核心容器与框架,包括ConcurrentHashMap的锁分段技术、ConcurrentLinkedQueue的非阻塞算法,以及各种阻塞队列的特性与应用场景。同时,解析了Fork/Join框架的工作窃取算法和设计原理。
Java并发编程艺术学习笔记(五)
Java并发容器和框架
Java为开发者也提供了许多开发容器和框架,可以从每节的原理分析来学习其中精妙的并发程序。
一.ConcurrentHashMap的实现原理和使用
Ⅰ.为什么要使用ConcurrentHashMap
在并发编程的时候如果使用HashMap可能会导致程序死循环,但是线程安全的HashTable效率又十分低下。所以需要一个线程安全又高效的ConcurrentHashMap。
(1)线程不安全的HashMap
在多线程环境中,使用HashMap进行put操作会引起死循环,导致CPU的利用率接近100%。原因是多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,会产生死循环来获取Entry。
(2)效率低下的HashTable
HashTable容器使用的是synchronized来保证线程安全的,但是效率十分低下,当一个线程put操作时,另外一个线程非但不能添加元素也不能读取元素。
(3)ConcurrentHashMap的锁分段技术可以有效提高并发访问率
锁分段技术是容器中有多把锁,每一把锁用于锁容器中的一部分数据,当多线程访问容器中不同数据段的数据时,线程之间就不会产生竞争和,从而可以有效的提高并发访问效率。
Ⅱ.ConcurrentHashMap的结构
结构是由Segment数组结构和HashEntry数组结构构成的。Segment是一种可重入锁,在其中扮演了锁的结构;HashEntry主要用于储存键值对数据。Segment的结构跟HashMap相似就是数组加链表的实现形式,每个HashEntry就是一个链表结构的元素,每个Segment守护着一个HashEntry数组中的元素,当对HashEntry数组进行修改的时候需要获得它对应的Segment锁。具体结构如下:
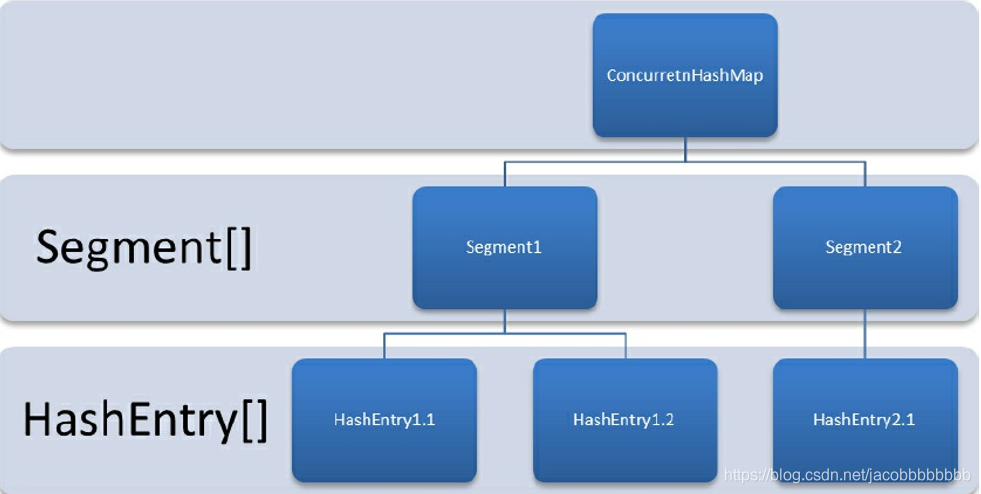
Ⅲ.ConcurrentHashMap的初始化
初始化方法时通过initialCapacity,loadFactor和concurrencyLevel等几个参数。
1.初始化segments数组
segments数组的长度ssize是通过concurrentLevel来计算得到的。需要得出一个大于等于concurrentLevel的最小2的N次方来作为ssize的值。
2.初始化segmentShift和segmentMask
这两个全局变量是在定位segment散列算法中使用,sshift等于ssize从1向左移动位的次数。segmentShift用来定位参加散列运算的位数,segmentShift等于32减去sshift,用32是因为hash()方法输出的最大数是32位,segmentMask是散列运算的掩码,等于ssize减去1,掩码的二进制各个数都是1。
3.初始化每个segment
输入参数initialCapacity是初始化容量。loadfactor是每个segment的负载因子。cap是segment里HashEntry数组的长度,它等于initialCapacity除以ssize的倍数c,如果c大于1,就会取大于等于2的N次方值,所以cap不是1就是2的N次方。segment的容量是threshold=(int)cap*loadFactor。
Ⅳ.定位Segment
Ⅴ.ConcurrentHashMap的操作
操作主要有3种–get操作/put操作/size操作
1.get操作
先进行一次再散列,再使用这个散列的值通过散列运算定位到segment,再通过散列算法定位到元素。
get方法高效之处在于整个get方法并不需要加锁,除非读到的值是个空值才需要加锁重读。做到不加锁的原因是它的get方法里将要用到的共享变量都定义成了volatile类型。这就是一个用volatile替换锁的一种经典实现场景。
2.put操作
为了线程安全,在进行put操作的时候必须加锁,put方法首先定位到了Segment,然后在Segment里面进行插入工作,需要经历两个步骤:
(1)是否需要扩容
在插入元素前先会判断Segment中的hashEntry数组是否已经超过容量,如果超过了就需要对数组进行扩容。Segment比hashmap的扩容更合适是因为segment是元素插入前进行判断,而hashmap是元素插入后,这样避免了hashmap可能发生的无效的扩容。
(2)如何扩容
扩容跟hashmap类似,不同的是concurrenthashmap只会对某个segment进行扩容。
3.size操作
如果要统计整个ConcurrentHashMap中的元素的大小,就必须统计所有segment里元素的大小后求和,segment的全局变量count是一个volatile变量,最安全的统计做法是在统计size的时候把所有segment的put、remove和clean方法全部锁住,但是这方法十分低效。
所以concurrenthashmap的做法是先尝试2次通过不锁住segment的方法来统计各个segment大小,如果统计的过程中count发生了变化在采用加锁的方式进行计算。在判断在统计过程中容器是否发生变化的方式是设置一个modCount变量,每次put、remove、clean操作都会将这个值加1,只要size的过程中判断这个值是否发生了变化就知道count有没有变化。
二.ConcurrentLinkedQueue
并发编程有些需要线程安全的队列,实现一个线程安全的队列有两种方法:一种是使用阻塞算法,另外一种是使用非阻塞算法。非阻塞方法主要是通过CAS的方式来实现的。
Ⅰ.ConcurrentLinkedQueue的结构
ConcurrentLinkedQueue是由head节点和tail节点组成,每个节点都有元素item和下一个节点next来构成,节点和节点之间通过next关联起来,组成一个链表结构的队列。默认情况下head节点储存的元素为空,tail节点等于head节点。
Ⅱ.入队列
入队列其实就是把节点加入队列的尾部。入队操作主要过程:
1.通过tail来找到真正的尾节点,将新的节点加入到真正尾节点的next节点。
2.如果tail的next节点不为空,将新的节点设置成tail节点(tail节点不总是真正的尾节点,而具体可以允许有多少个差距根据用户设定的HPOS值)。
入队列的源码如下:
public boolean offer(E e) {
checkNotNull(e);
//新建一个节点
final Node<E> newNode = new Node<E>(e);
//t设置成tail节点,p设置成真正的尾节点,暂时赋值为tail节点
for (Node<E> t = tail, p = t;;) {
//设置q为p的next节点
Node<E> q = p.next;
//如果q是空的,说明此时的p就是真正的尾节点
if (q == null) {
// p is last node
将真正尾节点p的next节点设置成新的新的节点
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
如果真正尾节点不等于尾节点,将tail节点设置成新的节点
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
如果p和q相同,那么只有一种可能那就是初始化的过程中都是NULL
else if (p == q)
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}
**为什么不让tail永远作为队列尾节点:因为这样就需要使用循环CAS来更新tail节点,而间隔1位就可以理论上减少一半的CAS操作,并且还可以根据HOPS来修改更新频率。本质上就是volatile读操作的开销远远大于volatile写操作的开销,而将volatile写的操作替代成volatile读的操作可以大大提高效率。
Ⅲ.出队列
出队列就是从队列里返回一个节点元素,并且清空该节点。具体过程:
1.如果head节点中有元素的时候,将会直接弹出head节点中的元素而不会更新head节点。
2.如果head中没有元素,队列才会更新head节点。
具体源码如下:
public E poll() {
restartFromHead:
for (;;) {
//将h设为头节点,p暂时引用为头节点
for (Node<E> h = head, p = h, q;;) {
//将item设置成p的元素内容
E item = p.item;
//如果p中的内容不为空,并且可以用cas将内容设置成空
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
//如果当时p不等于h,说明已经有其他线程修改了
if (p != h) // hop two nodes at a time
//更新下h引用,改成头节点往后的第一个不是null的节点
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
//如果头节点的next节点是null
else if ((q = p.next) == null) {
//将头节点更新为p
updateHead(h, p);
return null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
三.Java中的阻塞队列
Ⅰ.什么是阻塞队列
BlockingQueue是一个支持两个附加操作的队列,这两个附加的操作支持阻塞的插入和移除方法。
(1)支持阻塞的插入方法:当队列满时,队列会阻塞插入元素的线程,直到队列不满。
(2)支持阻塞的移除方法:队列为空的时,获取元素的线程会阻塞来等待队列不为空为止。
阻塞队列常常用来生产者和消费者的场景,阻塞队列就是生产者用来存放元素,消费者用来获取元素的容器。

抛出异常:如果队列满的时候再次插入元素就会抛出异常;如果队列空的时候再次获取元素就会抛出异常。
返回特殊值:往队列插入元素的时候会返回元素是否插入成功,成功就返回true;如果时移除方法,从队列中取出一个元素,如果没有就返回null。
一直阻塞:上文说过。
超时退出:如果阻塞队列满时,生产者线程往队列中插入元素,队列会阻塞生产者线程一段时间,如果超过了指定的时间就会退出。
** 如果是无界阻塞队列,队列中不可能出现满的情况。
Ⅱ.Java中的阻塞队列
JDK7中一共提供了7个阻塞队列如下:
(1)ArrayBlockingQueue
一个用数组实现的有界阻塞队列,按照FIFO的原则进行排序。
默认是个不公平的访问队列,就是不保证阻塞的线程按照FIFO进入队列。
(2)LinkedBlockingQueue
链表实现的有界阻塞队列,按照FIFO对元素进行排序。
(3)PriorityBlockingQueue
一个支持优先级的无界阻塞队列,默认情况下元素采用自然顺序升序排列。也可以自己通过实现类来排序。
(4)DelayQueue
支持延时获取元素的无界阻塞队列,队列使用PriorityQueue来实现,队列中的元素必须实现Delayed接口,在创建元素的时候可以指定多久才能从队列中获取当前元素。只有延迟期满了才可以从队列中提取元素。
DelayQueue十分有用,可以将DelayQueue运用在如下的场景:
1️⃣缓存系统的设计
2️⃣定时任务调度
1.如何实现Delayed接口
第一步:在对象创建的时候初始化基本数据。
第二步:实现getDelay方法。返回当前元素还需要多长时间。
第三步:实现compareTo方法来指定元素的顺序。
2.如何实现延时阻塞队列
如果没有达到元素的延迟时间,就会阻塞该获取元素的进程。
(5)SynchronousQueue
这是一个不存储元素的阻塞队列,每一个put操作必须等待一个take操作,因此可以看成是生产者和消费者之间的传球手。
(6)LinkedTransferQueue
一个由链表结构组成的无界阻塞TransferQueue,比起其他的阻塞队列多了tryTransfer和transfer方法。
1️⃣transfer方法
如果有消费者在接收元素,使用transfer方法可以把元素从生产者立刻传送给消费者。如果没有消费者接收元素,transfer方法会将元素存放在队列的tail节点并且等到消费者消费了才返回。
2️⃣tryTransfer方法
用来试探生产者传入的元素是否能直接传给消费者,如果没有消费者等待接收元素,将会返回false。
(7)LinkedBlockingDeque
是一个由链表结构组成的双向阻塞队列,双向列表指的是可以从队列的两端插入和移出元素。
Ⅲ.阻塞队列的实现原理
使用通知模式实现。指的是生产者往满的队列中添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后会通知生产者当前队列可用。
四.Fork/Join框架
Ⅰ.什么是Fork/Join框架
java7提供的一个用于并发执行任务的框架,是一个把大任务分割成若干的小任务,最终汇总每个小任务结果后得到大人物结果的框架。
Ⅱ.工作窃取算法
工作窃取算法是指某个线程从其他队列中窃取任务来执行。为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务。
Ⅲ.Fork/Join框架的设计
步骤1:分割任务,有一个fork类将大任务分割成小任务,如果小任务还是很大就需要再次切割。
步骤2:执行任务并合并结果,分割的子任务分别放在双端队列中,然后几个启动线程分别从双端队列中获取任务并且执行,子任务执行完就把结果统一放在一个队列中,启动一个线程从队列中拿数据,然后合并这些数据。
Fork/Join使用两个类来完成上述的两件事:
(1)ForkJoinTask:首先要使用框架必须先创建一个ForkJoin任务,它提供了任务在执行fork()和join()操作的机制,通常情况下只要继承ForkJoin的子类就可以了,Fork/Join框架有两个子类:
1️⃣RecursiveAction:用来没有返回结果的任务。
2️⃣RecursiveTask:用来有返回结果的任务。
(2)ForkJoinPool:任务分割出的子任务会添加到当前工作线程所维护的双端队列中。

















&spm=1001.2101.3001.5002&articleId=104524224&d=1&t=3&u=498c554675d8414e9a93885dac8dc70f)
 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









