




论文链接:http://xxx.itp.ac.cn/pdf/2003.05664v3
CondInst是ECCV20上的一篇关于实例分割的文章,个人感觉和YOLACT的思路有相似之处(CondInst最后的处理更加直接简洁)。作者将全卷积网络应用在实例分割的task上,通过采用动态生成的conditional convolution,解决了之前全卷积网络在实例分割上不work的问题。
涉及的问题
作者首先分析了经典的Mask RCNN的问题:(1)由于采用bbox先做框定,所以对于一些不规则的instance,bbox中会掺杂大量的背景信息或者其他实例的杂讯;(2)由于要区分前景和背景信息,因此mask head需要足够大的感受野来编码上下文信息,所以就导致了较多卷积层的堆叠,造成了计算的复杂;(3)ROI操作需要将不同尺寸的区域统一到相同区域,因此对于面积较大的instance,会损失很多精度。
随后作者又分析了FCN的问题:FCN在语义分割等领域已经非常出色,虽然语义分割和实例分割很相似,但FCN在实例分割上依旧不太work(远比不上ROI系列的算法)。究其原因,是因为FCN很难区分一张图像中有相同特征的实例,而实例分割要求我们将所有的实例区分开来;而ROI算法就可以将不同的instance裁剪出来,再逐一进行mask的预测。所以实例分割需要两类信息:(1)appearance:每一个目标的外观特征,即属于什么类别;(2)location:如果一张img有多个同类物体,要通过位置信息区分出他们的不同。
CondInst
所以作者提出了CondInst,可以看作是一个instance-aware的FCN。受动态卷积的启发,CondInst的网络参数是根据instance的不同而变化的,而这个网络参数的作用是编码一些instance的特征(例如位置、形状或者外观信息)。因此根据不同实例对应的conditional mask,把他们分配到整个特征图上,就可以避免ROI操作,从而直接得到每一个instance的mask。
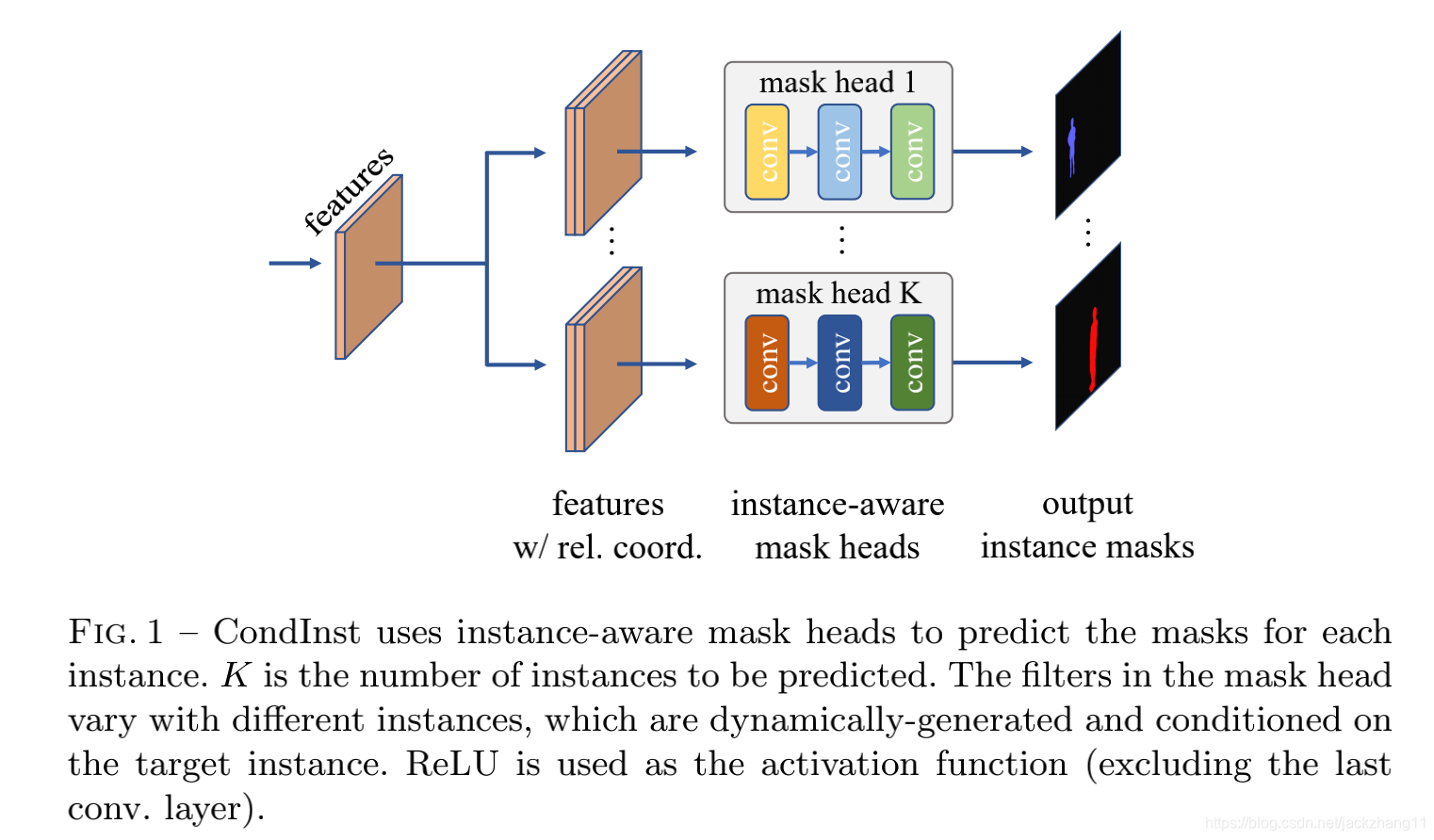
如上图所示,一张img上有K个实例,就需要动态地生成K个mask head,每一个head在他们的filter中都含有目标实例的一些特征,因此不同的mask作用到特征图时,只会根据各自编码特征,去响应拥有特征的实例所对应的pixel。进而得到不同instance的mask。
Architecture
下图为CondInst的模型图:
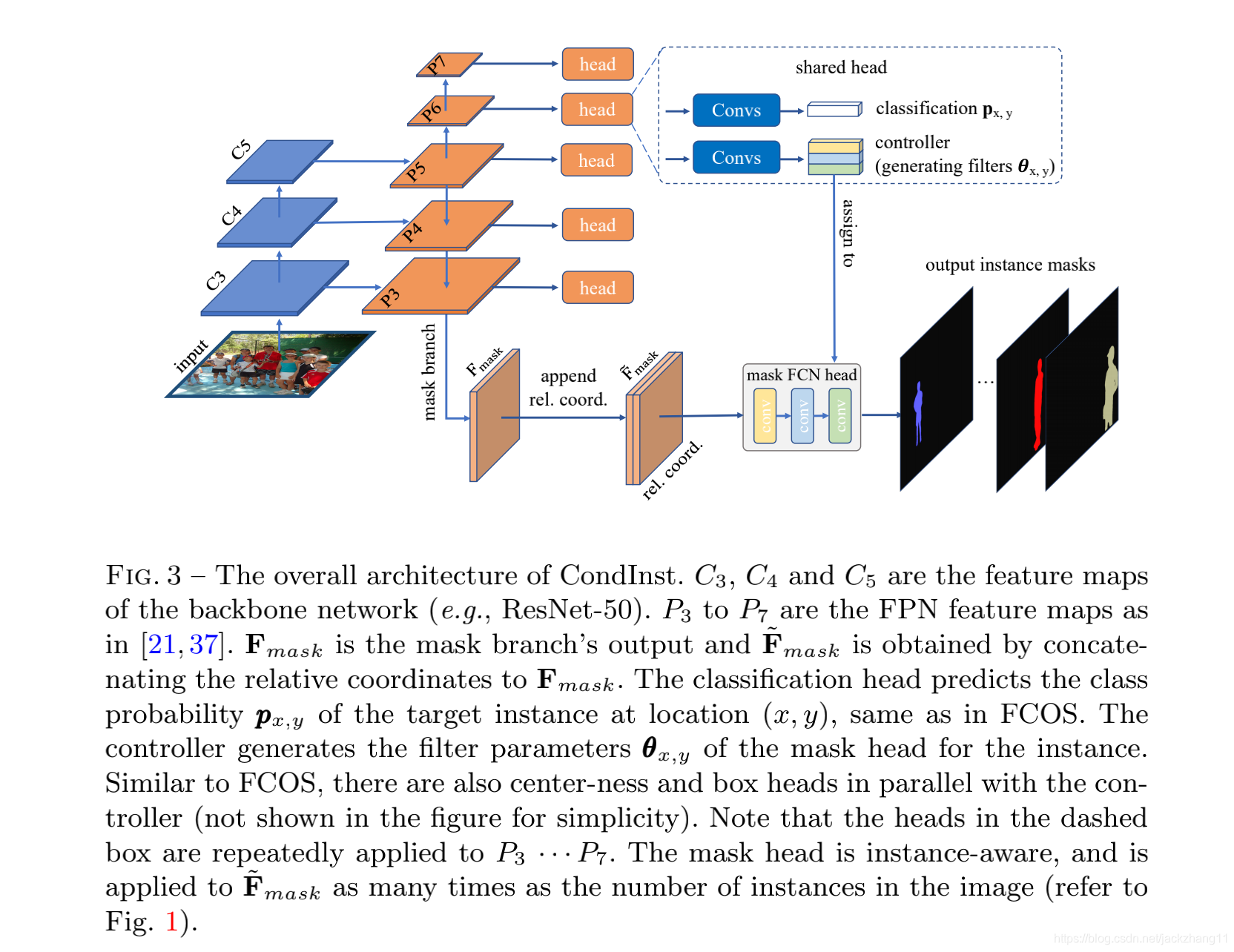
backbone采用ResNet50,采用FPN结构。下面的mask branch是P3经过卷积得到的特征图,FmaskF_{mask}Fmask,其维度C=8,然后又经过一个类似于coordconv的操作,加上了两个维度的position信息,得到了F~mask\widetilde{F}_{mask}F mask,维度为8+2=10。上面的部分针对不同尺度的特征图(P3-P7),得到分类向量px,yp_{x,y}px,y,以及controller里面的参数θx,y\theta_{x,y}θ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2981
2981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









