







最近看了一个视频教程,了解了一下yolov到底是怎么训练的,若真是从零开始的话,应该是用labelimg标注数据开始,不过这个番茄有现成的数据集并且已经标注好,就先拿来用,labelimg标注数据的用法到时也学习一下,做个备忘。
训练之前先说一下环境,如果有英伟达显卡的建议是用gpu来训练,我显卡型号是rtx3060Ti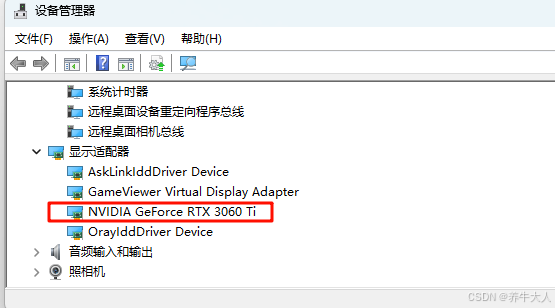
CUDA安装了12.4,安装torch的时候cuda版本不高于12.4应该就可以了, cmd中输入nvidia-smi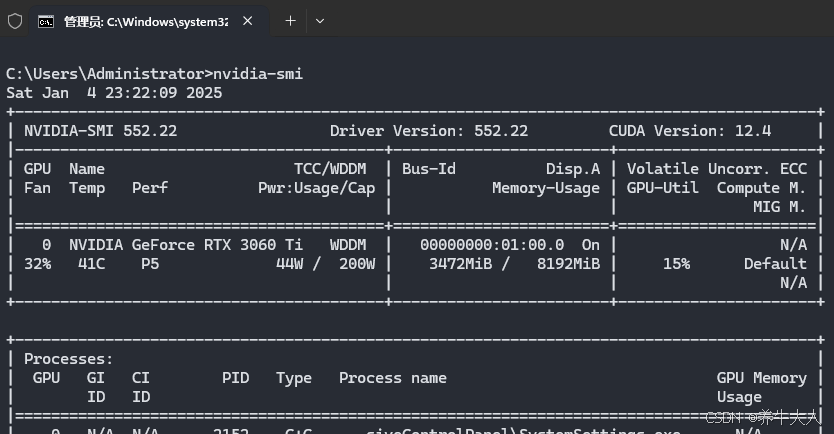
 cudnn用的是8.9.7 for 12.x,下载cudnn需要登录 ,以下链接可直接 迅雷 下载
cudnn用的是8.9.7 for 12.x,下载cudnn需要登录 ,以下链接可直接 迅雷 下载
https://developer.nvidia.com/downloads/compute/cudnn/secure/8.9.7/local_installers/12.x/cudnn-windows-x86_64-8.9.7.29_cuda12-archive.zip/
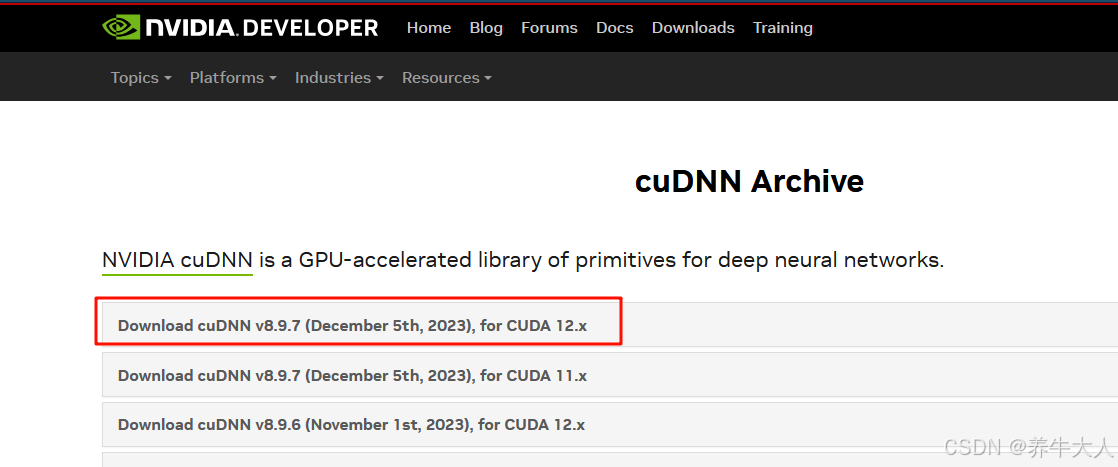
最好是使用conda环境,Anaconda或miniconda都可以
虚拟环境用的是比较常用的python3.9,创建命令如下
conda create -n yolo11_t221 python=3.9.19torch gpu版本安装命令,速度慢可想办法加速
conda install pytorch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 pytorch-cuda=12.1 -c pytorch -c nvidia还有其它很多库可以通过requirements.txt批量安装,注意torch部分要用官方命令,这里就注释了
安装命令:pip install -t requirement.txt
certifi==2024.8.30
charset-normalizer==3.3.2
colorama==0.4.6
contourpy==1.3.0
cycler==0.12.1
dill==0.3.9
filelock==3.13.1
fonttools==4.54.1
fsspec==2024.2.0
idna==3.10
Jinja2==3.1.3
kiwisolver==1.4.7
MarkupSafe==2.1.5
matplotlib==3.9.2
mpmath==1.3.0
networkx==3.2.1
numpy==1.26.3
opencv-python==4.10.0.84
packaging==24.1
pandas==2.2.3
pillow==10.2.0
psutil==6.0.0
py-cpuinfo==9.0.0
pyparsing==3.1.4
python-dateutil==2.9.0.post0
pytz==2024.2
PyYAML==6.0.2
requests==2.32.3
scipy==1.14.1
seaborn==0.13.2
six==1.16.0
sympy==1.12
# torch==2.2.1+cu121
# torchaudio==2.2.1+cu121
# torchvision==0.17.1+cu121
tqdm==4.66.5
typing_extensions==4.9.0
tzdata==2024.2
ultralytics==8.3.0
ultralytics-thop==2.0.8
urllib3==2.2.3
onnx>=1.12.0
onnxslim==0.1.34
onnxruntime需要注意的是:ultralytics版本如果安装最新的版本,会把torch升级到最新
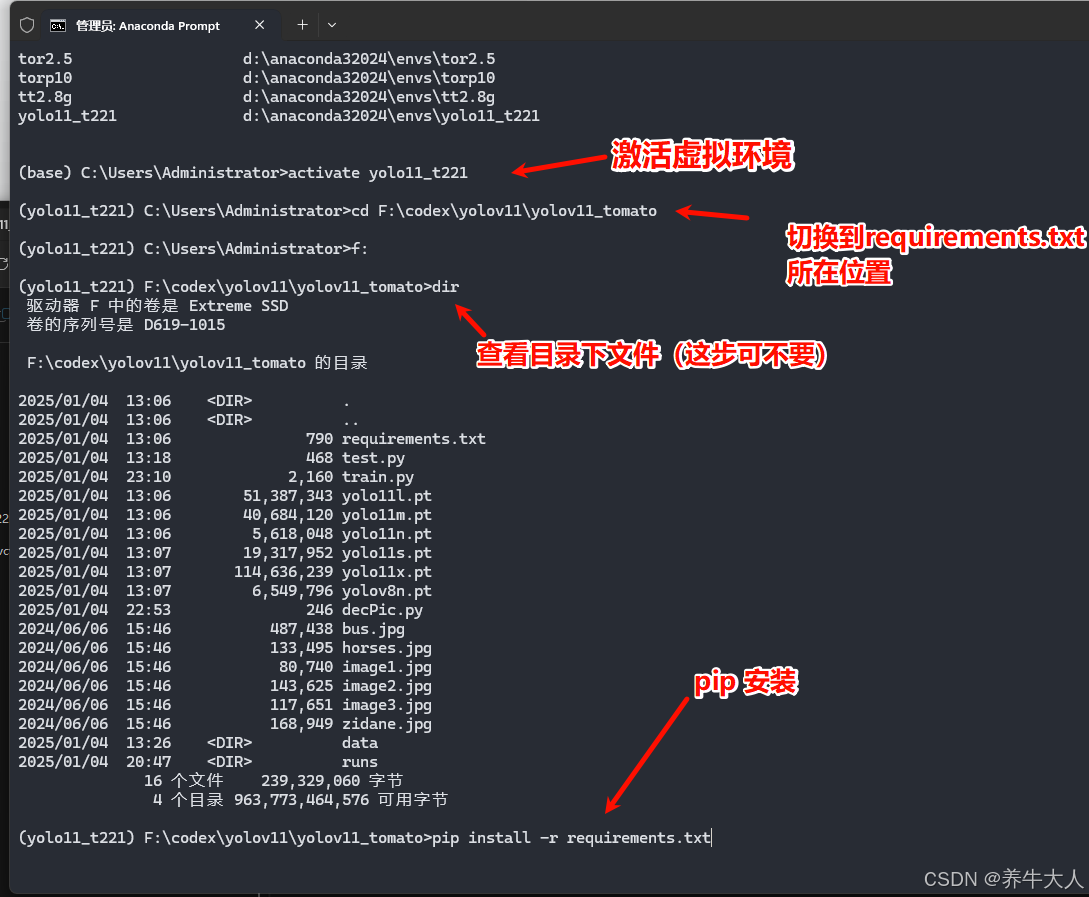
安装完成之后,用vscode或Cursor打开项目文件夹,我把数据集放在了
F:\codex\yolov11\yolov11_tomato\data 下面,然后让Ai写了一个Train.py
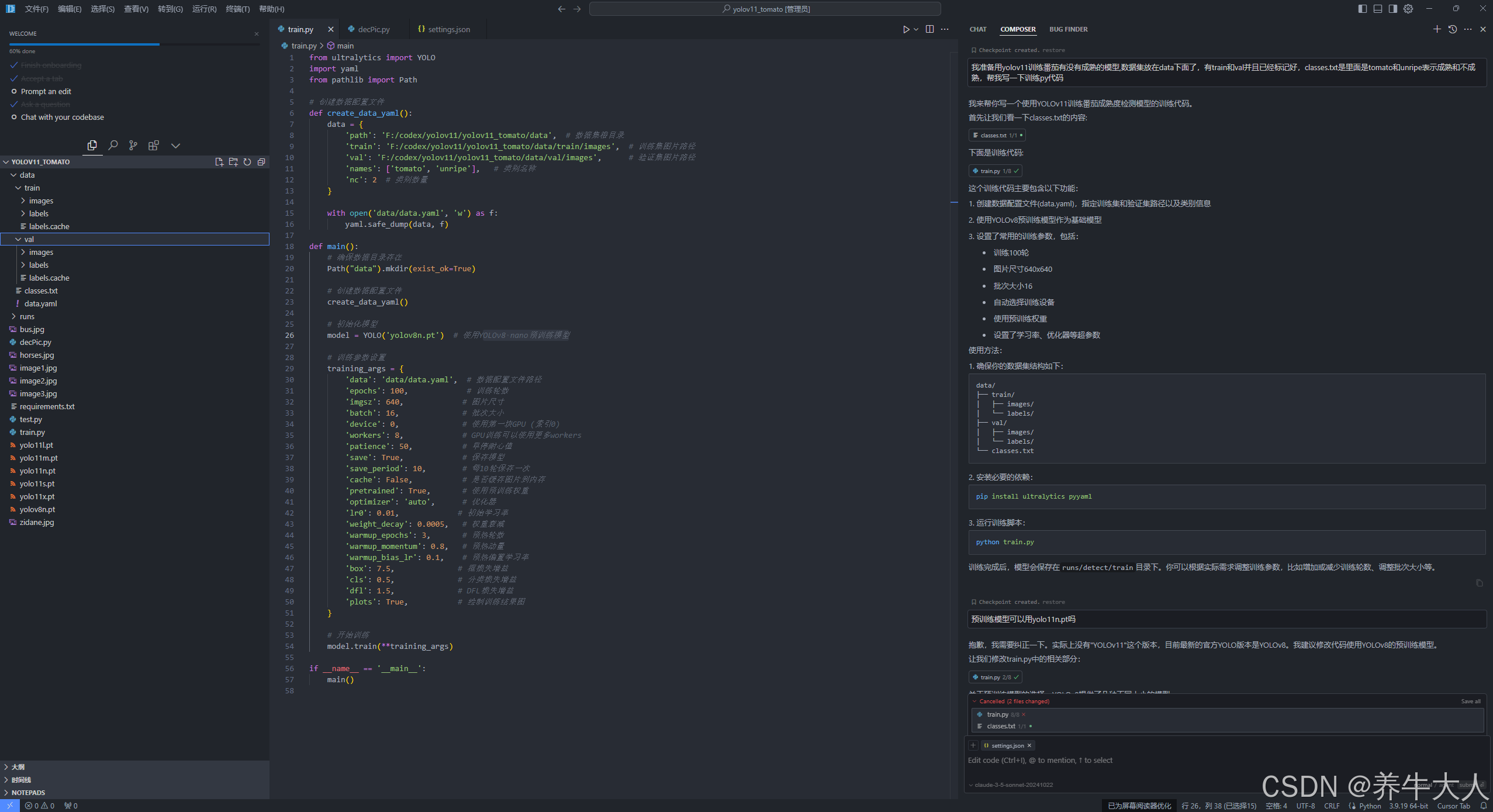
train.py
from ultralytics import YOLO
import yaml
from pathlib import Path
# 创建数据配置文件
def create_data_yaml():
data = {
'path': 'F:/codex/yolov11/yolov11_tomato/data', # 数据集根目录
'train': 'F:/codex/yolov11/yolov11_tomato/data/train/images', # 训练集图片路径
'val': 'F:/codex/yolov11/yolov11_tomato/data/val/images', # 验证集图片路径
'names': ['tomato', 'unripe'], # 类别名称
'nc': 2 # 类别数量
}
with open('data/data.yaml', 'w') as f:
yaml.safe_dump(data, f)
def main():
# 确保数据目录存在
Path("data").mkdir(exist_ok=True)
# 创建数据配置文件
create_data_yaml()
# 初始化模型
model = YOLO('yolov8n.pt') # 使用YOLOv8 nano预训练模型
# 训练参数设置
training_args = {
'data': 'data/data.yaml', # 数据配置文件路径
'epochs': 100, # 训练轮数
'imgsz': 640, # 图片尺寸
'batch': 16, # 批次大小
'device': 0, # 使用第一块GPU (索引0)
'workers': 8, # GPU训练可以使用更多workers
'patience': 50, # 早停耐心值
'save': True, # 保存模型
'save_period': 10, # 每10轮保存一次
'cache': False, # 是否缓存图片到内存
'pretrained': True, # 使用预训练权重
'optimizer': 'auto', # 优化器
'lr0': 0.01, # 初始学习率
'weight_decay': 0.0005, # 权重衰减
'warmup_epochs': 3, # 预热轮数
'warmup_momentum': 0.8, # 预热动量
'warmup_bias_lr': 0.1, # 预热偏置学习率
'box': 7.5, # 框损失增益
'cls': 0.5, # 分类损失增益
'dfl': 1.5, # DFL损失增益
'plots': True, # 绘制训练结果图
}
# 开始训练
model.train(**training_args)
if __name__ == '__main__':
main()
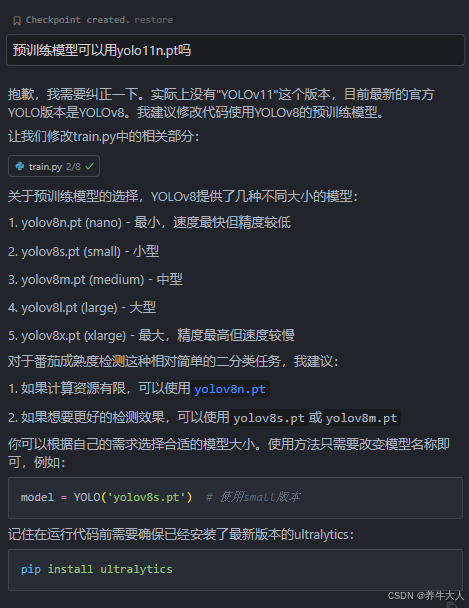
,这里ai自动选择了yolov8n.pt,也可用yolo11n.pt 尝试下,以下是ai的回答,
运行train.py文件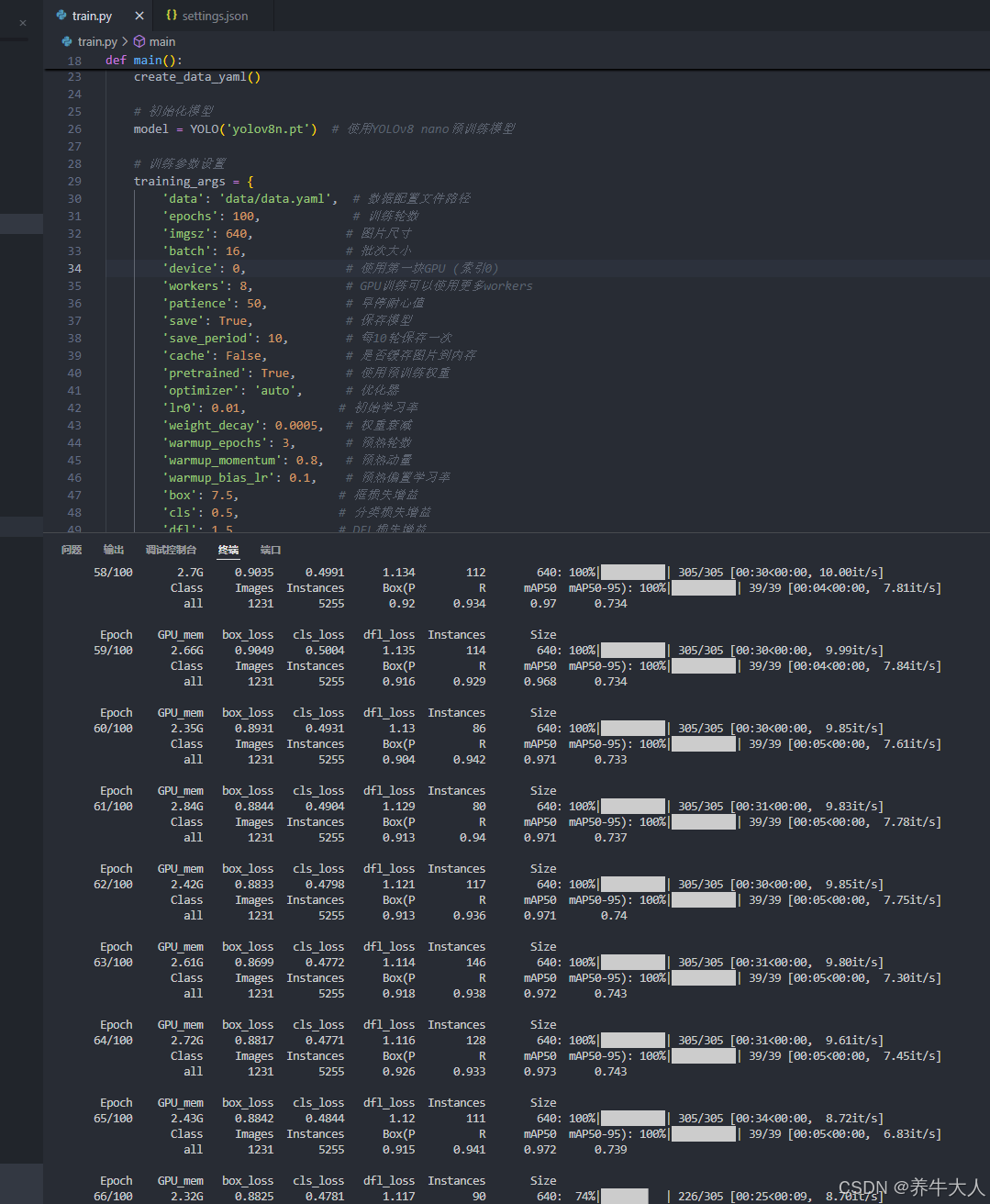
训练信息,大概用了一个小时,100轮,次数应该不太够,会影响 精度如果时间足够可设置成300轮左右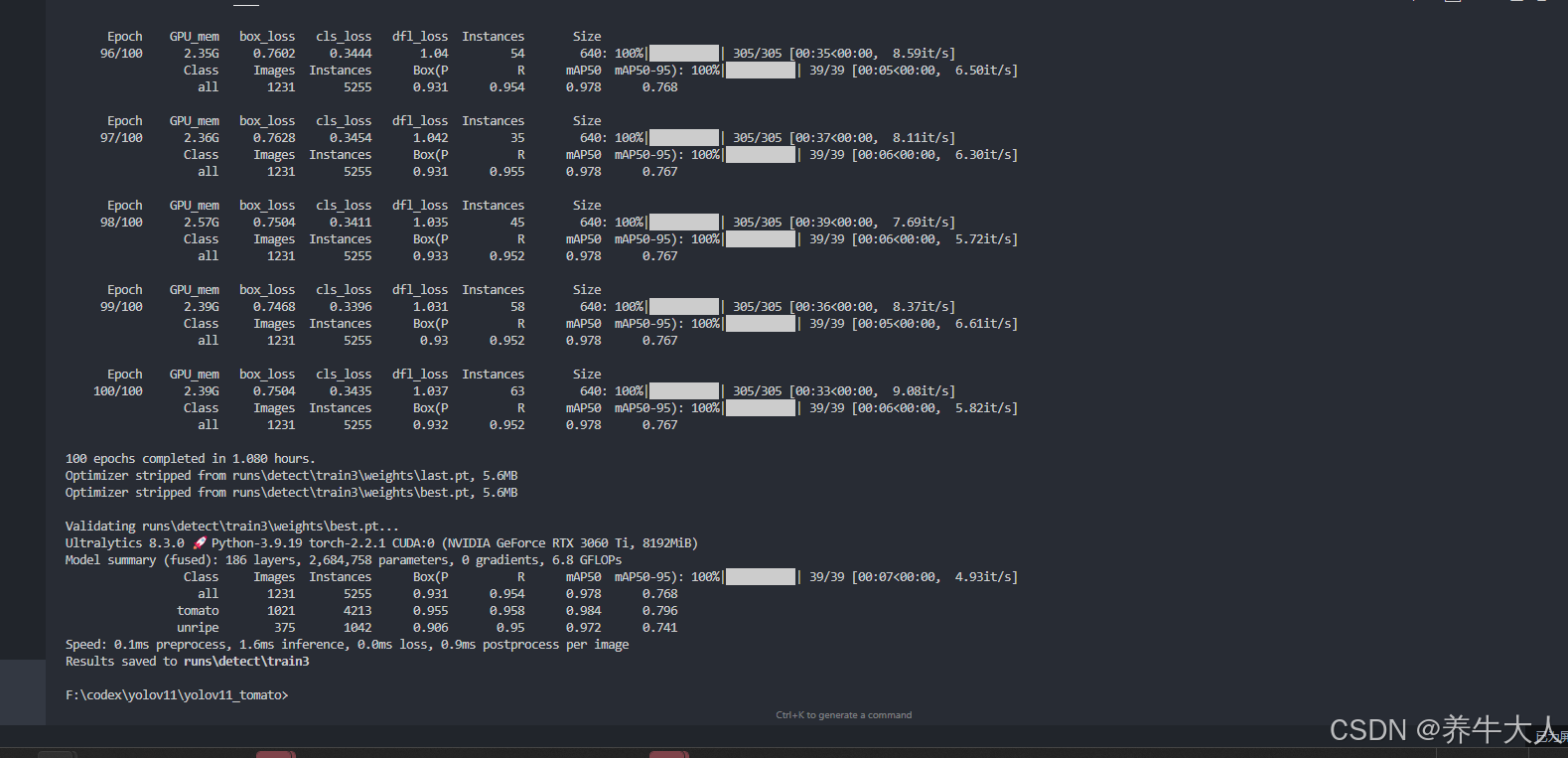
训练完成后,接下来是检测,简单的代码如下保存为decPic.py
from ultralytics import YOLO
if __name__ == "__main__":
model = YOLO(r"F:\codex\yolov11\yolov11_tomato\runs\detect\train3\weights\best.pt")
results = model(r"f:/000.jpg")
# print(results)
results[0].show()

或者检测代码改为,检测后保存结果 ,并用cv2跳出窗口
import cv2
from ultralytics import YOLO
import os
def detect_image(model_path, image_path, save_dir='predict'):
# 加载模型
model = YOLO(model_path)
# 确保保存目录存在
os.makedirs(save_dir, exist_ok=True)
# 进行预测
results = model(image_path)
# 获取原始图片
img = cv2.imread(image_path)
# 在图片上绘制检测结果
for result in results:
boxes = result.boxes
for box in boxes:
# 获取边界框坐标
x1, y1, x2, y2 = box.xyxy[0]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
# 获取置信度
conf = float(box.conf)
# 获取类别
cls = int(box.cls)
cls_name = result.names[cls]
# 绘制边界框
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 添加标签文本
label = f'{cls_name} {conf:.2f}'
cv2.putText(img, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 保存结果图片
save_path = os.path.join(save_dir, os.path.basename(image_path))
cv2.imwrite(save_path, img)
print(f"结果已保存至: {save_path}")
# 显示图片
cv2.imshow('Detection Result', img)
cv2.waitKey(0) # 等待按键
cv2.destroyAllWindows() # 关闭窗口
if __name__ == '__main__':
# 设置模型路径和图片路径
model_path = 'F:/codex/yolov11/yolov11_tomato/runs/detect/train3/weights/best.pt' # 使用训练好的最佳模型
image_path = 'f:/000.jpg' # 替换为你的测试图片路径
# 执行检测
detect_image(model_path, image_path)
视频检测代码:decVideo.py
import cv2
from ultralytics import YOLO
def detect_camera(model_path, camera_id=0):
# 加载模型
model = YOLO(model_path)
# 打开摄像头
cap = cv2.VideoCapture(camera_id)
if not cap.isOpened():
print("无法打开摄像头")
return
print("按ESC键退出检测") # 添加提示信息
while True:
# 读取视频帧
ret, frame = cap.read()
if not ret:
break
# 进行检测
results = model(frame)
# 在帧上绘制检测结果
for result in results:
boxes = result.boxes
for box in boxes:
# 获取边界框坐标
x1, y1, x2, y2 = box.xyxy[0]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
# 获取置信度
conf = float(box.conf)
# 获取类别
cls = int(box.cls)
cls_name = result.names[cls]
# 绘制边界框
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 添加标签文本
label = f'{cls_name} {conf:.2f}'
cv2.putText(frame, label, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示结果
cv2.imshow('Camera Detection', frame)
# 按'ESC'退出
if cv2.waitKey(1) == 27: # 27是ESC键的ASCII码
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
# 设置模型路径
model_path = 'F:/codex/yolov11/yolov11_tomato/runs/detect/train3/weights/best.pt'
# 执行摄像头检测
detect_camera(model_path) # 默认使用摄像头ID=0
# detect_camera(model_path, 1) # 如果要使用外接摄像头,可以尝试ID=1
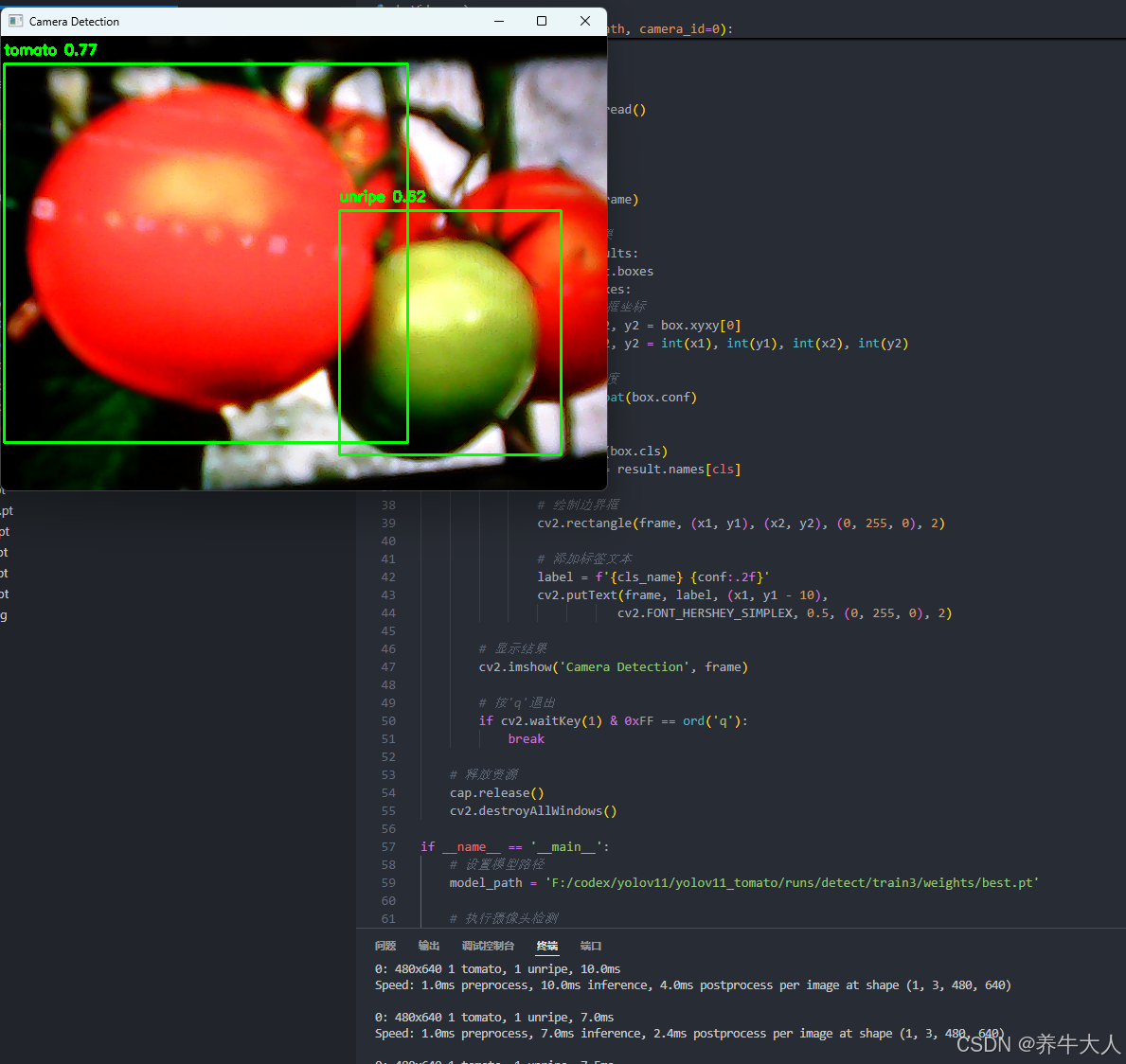
至于数据集,我问了下AI
以下是几个可以下载番茄成熟度数据集的网站:
- Roboflow Universe
- 链接:https://universe.roboflow.com/
- 搜索"tomato ripeness"或"tomato detection"
- 包含多个番茄成熟度数据集
- 支持直接下载YOLO格式的标注
- Kaggle
- 链接:https://www.kaggle.com/datasets
- 搜索"tomato ripeness dataset"
- 有多个相关数据集,包括:
- Tomato Detection Dataset
- Tomato Ripeness Classification
- AI Studio
- 链接:https://aistudio.baidu.com/datasetdetail/184335
- 提供番茄成熟度分类数据集
建议:
- 优先使用Roboflow,因为:
- 直接支持YOLO格式
- 数据质量较好
- 提供数据增强功能
- 如果数据集较小,可以通过以下方法扩充:
-
training_args = { # ... 其他参数 ... 'augment': True, # 启用数据增强 'degrees': 45, # 旋转角度 'scale': 0.5, # 缩放范围 'fliplr': 0.5, # 水平翻转概率 'mosaic': 1.0, # 马赛克增强 }


















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











