




 本文深入讲解C++编程的多个核心概念,包括单独编译、存储持续性、作用域和链接性、定位new运算符、名称空间等。文章详细阐述了头文件的使用,函数和变量的链接性,静态和动态存储,以及C++11的新特性。通过实例演示了如何管理和使用内存,以及名称空间如何避免命名冲突。
本文深入讲解C++编程的多个核心概念,包括单独编译、存储持续性、作用域和链接性、定位new运算符、名称空间等。文章详细阐述了头文件的使用,函数和变量的链接性,静态和动态存储,以及C++11的新特性。通过实例演示了如何管理和使用内存,以及名称空间如何避免命名冲突。

本章内容包括:
• 单独编译。
• 存储持续性、作用域和链接性。
• 定位(placement)new运算符。
• 名称空间。
与其将结构声明加入到每一个文件中,不如将其放在头文件中,然后在每一个源代码文件中包含该头文件。这样,要修改结构声明时,只需在头文件中做一次改动即可。另外,也可以将函数原型放在头文件中。因此,可以将原来的程序分成三部分。
- 头文件:包含结构声明和使用这些结构的函数的原型。
- 源代码文件:包含与结构有关的函数的代码。
- 源代码文件:包含调用与结构相关的函数的代码。
请不要将函数定义或变量声明放到头文件中。这样做对于简单的情况可能是可行的,但通常会引来麻烦。例如,如果在头文件包含一个函数定义,然后在其他两个文件(属于同一个程序)中包含该头文件,则同一个程序中将包含同一个函数的两个定义,除非函数是内联的,否则这将出错。下面列出了头文件中常包含的内容。
- 函数原型。
- 使用#define或const定义的符号常量。
- 结构声明。
- 类声明。
- 模板声明。
- 内联函数。
将结构声明放在头文件中是可以的,因为它们不创建变量,而只是在源代码文件中声明结构变量时,告诉编译器如何创建该结构变量。同样,模板声明不是将被编译的代码,它们指示编译器如何生成与源代码中的函数调用相匹配的函数定义。被声明为const的数据和内联函数有特殊的链接属性(稍后将介绍),因此可以将其放在头文件中,而不会引起问题。
下图简要地说明了在UNIX系统中将该程序组合起来的步骤。注意,只需执行编译命令CC即可,其他步骤将自动完成。g++和gpp命令行编译器以及Borland C++命令行编译器(bcc32.exe)的行为类似。Apple Xcode、Embarcadero C++ Builderr和Microsoft Visual C++基本上执行同样的步骤,但启动这个过程的方式不同——使用能够创建项目并将其与源代码文件关联起来的菜单。注意,只需将源代码文件加入到项目中,而不用加入头文件。这是因为#include指令管理头文件。另外,不要使用#include来包含源代码文件,这样做将导致多重声明。

/* coordin.h -- 结构模板和函数原型*/
#ifndef COORDIN_H_
#define COORDIN_H_
struct polar {
double distance; // distance from origin
double angle; // direction from origin
};
struct rect {
double x; // horizontal distance from origin
double y; // vertical distance from origin
};
// prototypes
polar rect_to_polar(rect xypos);
void show_polar(polar dapos);
#endif
基于预处理器编译指令#ifndef(即if not defined)的。上面的代码片段意味着仅当以前没有使用预处理器编译指令#define定义名称COORDIN_H_时,才处理#ifndef和#endif之间的语句。大多数标准C和C++头文件都使用这种防护(guarding)方案。否则,可能在一个文件中定义同一个结构两次,这将导致编译错误。
/* file1.cpp */
#include <iostream>
#include <cmath>
#include "coordin.h"
// convert rectangular to polar coordinates
polar rect_to_polar(rect xypos) {
using namespace std;
polar answer;
answer.distance = sqrt(xypos.x * xypos.x + xypos.y * xypos.y);
answer.angle = atan2(xypos.y, xypos.x);
return answer; // returns a polar structure
}
// show polar coordinates, converting angle to degrees
void show_polar(polar dapos) {
using namespace std;
const double Rad_to_deg = 57.29577951;
cout << "distance = " << dapos.distance;
cout << ", angle = " << dapos.angle * Rad_to_deg;
cout << " degrees\n";
}
/* file2.cpp -- 三个文件的程序示例 */
#include <iostream>
#include "coordin.h" // structure templates, function prototypes
using namespace std;
int main() {
rect rplace;
polar pplace;
cout << "Enter the x and y values: ";
while (cin >> rplace.x >> rplace.y) { // 连续用cin
pplace = rect_to_polar(rplace);
show_polar(pplace);
cout << "Next two numbers (q to quit): ";
}
cout << "Bye!\n";
return 0;
}
Enter the x and y values: |120 80
distance = 144.222, angle = 33.6901 degrees
Next two numbers (q to quit): |120 50
distance = 130, angle = 22.6199 degrees
Next two numbers (q to quit): q
Bye!
顺便说一句,虽然我们讨论的是根据文件进行单独编译,但为保持通用性,C++标准使用了术语翻译单元(translation unit),而不是文件;文件并不是计算机组织信息时的唯一方式。出于简化的目的,本书使用术语文件,你可将其解释为翻译单元。
存储持续性、作用域和链接性:
➊存储持续性:
C++使用三种(在C++11中是四种)不同的方案来存储数据,这些方案的区别就在于数据保留在内存中的时间。
- 自动存储持续性:在函数定义中声明的变量(包括函数参数)的存储持续性为自动的。它们在程序开始执行其所属的函数或代码块时被创建,在执行完函数或代码块时,它们使用的内存被释放。C++有2种存储持续性为自动的变量。
- 静态存储持续性:在函数定义外定义的变量和使用关键字static定义的变量的存储持续性都为静态。它们在程序整个运行过程中都存在。C++有3种存储持续性为静态的变量。
- 线程存储持续性(C++11):当前,多核处理器很常见,这些CPU可同时处理多个执行任务。这让程序能够将计算放在可并行处理的不同线程中。如果变量是使用关键字thread_local声明的,则其生命周期与所属的线程一样长。本书不探讨并行编程。
- 动态存储持续性:用new运算符分配的内存将一直存在,直到使用delete运算符将其释放或程序结束为止。这种内存的存储持续性为动态,有时被称为自由存储(free store)或堆(heap)。
作用域(scope)描述了名称在文件(翻译单元)的多大范围内可见。例如,函数中定义的变量可在该函数中使用,但不能在其他函数中使用;而在文件中的函数定义之前定义的变量则可在所有函数中使用。链接性(linkage)描述了名称如何在不同单元间共享。链接性为外部的名称可在文件间共享,链接性为内部的名称只能由一个文件中的函数共享。自动变量的名称没有链接性,因为它们不能共享。
C++变量的作用域有多种。作用域为局部的(也叫块作用域)变量只在定义它的代码块中可用。代码块是由花括号括起的一系列语句。例如函数体就是代码块,但可以在函数体中嵌入其他代码块。作用域为全局(也叫文件作用域)的变量在定义位置到文件结尾之间都可用。自动变量的作用域为局部,静态变量的作用域是全局还是局部取决于它是如何被定义的。在函数原型作用域(function prototype scope)中使用的名称只在包含参数列表的括号内可用(这就是为什么这些名称是什么以及是否出现都不重要的原因)。在类中声明的成员的作用域为整个类。在名称空间中声明的变量的作用域为整个名称空间(由于名称空间已经引入到C++语言中,因此全局作用域是名称空间作用域的特例)。
C++函数的作用域可以是整个类或整个名称空间(包括全局的),但不能是局部的(因为不能在代码块内定义函数,如果函数的作用域为局部,则只对它自己是可见的,因此不能被其他函数调用。这样的函数将无法运行)。
➌自动储存持续性:
在默认情况下,在函数中声明的函数参数和变量的存储持续性为自动,作用域为局部,没有链接性。也就是说,如果在main( )中声明了一个名为texas的变量,并在函数oil( )中也声明了一个名为texas变量,则创建了两个独立的变量——只有在定义它们的函数中才能使用它们。对oil( )中的texas执行的任何操作都不会影响main( )中的texas,反之亦然。另外,当程序开始执行这些变量所属的代码块时,将为其分配内存;当函数结束时,这些变量都将消失(注意,执行到代码块时,将为变量分配内存,但其作用域的起点为其声明位置)。
如果在代码块中定义了变量,则该变量的存在时间和作用域将被限制在该代码块内。例如,假设在main( )的开头定义了一个名为teledeli的变量,然后在main( )中开始一个新的代码块,并其中定义了一个新的变量websight,则teledeli在内部代码块和外部代码块中都是可见的,而websight就只在内部代码块中可见,它的作用域是从定义它的位置到该代码块的结尾:
int main()
{ //“{” teledeli分配到此块
int teledeli = 5; /* teledeli作用域起点 */
{ //“{” websight分配到此块
cout << "Hello\n";
int websight = -2; /* websight作用域起点 */
cout << websight << ' ' << teledeli << endl;
} //“}” websight作用域->结束,占用的内存自动释放
cout << teledeli << endl;
...
} //“}” teledeli作用域->结束,占用的内存自动释放
#include <iostream>
using namespace std;
void oil(int x);
int main() {
int texas = 31;
int year = 2011;
cout << "In main(), texas = " << texas << ", &texas = ";
cout << &texas << endl;
cout << "In main(), year = " << year << ", &year = ";
cout << &year << endl;
oil(texas);
cout << "In main(), texas = " << texas << ", &texas = ";
cout << &texas << endl;
cout << "In main(), year = " << year << ", &year = ";
cout << &year << endl;
return 0;
}
void oil(int x) {
int texas = 5;
cout << "In oil(), texas = " << texas << ", &texas = ";
cout << &texas << endl;
cout << "In oil(), x = " << x << ", &x = ";
cout << &x << endl;
{ // start a block
int texas = 113;
cout << "In block, texas = " << texas;
cout << ", &texas = " << &texas << endl;
cout << "In block, x = " << x << ", &x = ";
cout << &x << endl;
} // end a block
cout << "Post-block texas = " << texas;
cout << ", &texas = " << &texas << endl;
}
In main(), texas = 31, &texas = 0043FD88
In main(), year = 2011, &year = 0043FD7C
In oil(), texas = 5, &texas = 0043FC94
In oil(), x = 31, &x = 0043FCA8
In block, texas = 113, &texas = 0043FC88
In block, x = 31, &x = 0043FCA8
Post-block texas = 5, &texas = 0043FC94
In main(), texas = 31, &texas = 0043FD88
In main(), year = 2011, &year = 0043FD7C
在程序清单中,属于三个作用域的3个texas同名变量的地址各不相同,而程序使用当前可见的那个变量,因此将113赋给oil( )中的内部代码块中的texas,对其他同名变量没有影响。
在C++11中,关键字auto用于自动类型推断,这在前面章介绍过。但在C语言和以前的C++版本中,auto的含义截然不同,它用于显式地指出变量为自动存储:
int froob(int n) {
auto float ford; // ford是自动存储的
...
}
由于只能将关键字auto用于默认为自动的变量,因此程序员几乎不使用它。它的主要用途是指出当前变量为局部自动变量。
在C++11中,以上用法不再合法!制定标准的人不愿引入新关键字,因为这样做可能导致将该关键字用于其他目的的代码非法。考虑到auto的老用法很少使用,因此赋予其新含义比引入新关键字是更好的选择。
➀自动变量的初始化:
可以使用任何在声明时其值为已知的表达式来初始化自动变量,下面的示例初始化变量x、y和z:
int w; // w未初始化,默认为0
int x = 5; // x初始化为数字字面量
int big = INT_MAX -1; // big初始化为一个常量表达式
int y = 2 * x; // 初始化使用前面的x变量值
cin >> w;
int z = 3 * w; // 给w赋新值
➁自动变量和栈:
了解典型的C++编译器如何实现自动变量有助于更深入地了解自动变量。由于自动变量的数目随函数的开始和结束而增减,因此程序必须在运行时对自动变量进行管理。常用的方法是留出一段内存,并将其视为栈,以管理变量的增减。之所以被称为栈,是由于新数据被象征性地放在原有数据的上面(也就是说,在相邻的内存单元中,而不是在同一个内存单元中),当程序使用完后,将其从栈中删除。栈的默认长度取决于实现,但编译器通常提供改变栈长度的选项。程序使用两个指针来跟踪栈,一个指针指向栈底——栈的开始位置,另一个指针指向堆顶——下一个可用内存单元。当函数被调用时,其自动变量将被加入到栈中,栈顶指针指向变量后面的下一个可用的内存单元。函数结束时,栈顶指针被重置为函数被调用前的值,从而释放新变量使用的内存。
栈是LIFO(后进先出)的,即最后加入到栈中的变量首先被弹出。这种设计简化了参数传递。函数调用将其参数的值放在栈顶,然后重新设置栈顶指针。被调用的函数根据其形参描述来确定每个参数的地址。例如,下图表明,函数fib()被调用时,传递一个2字节的int和一个4字节的long。这些值被加入到栈中。当fib()开始执行时,它将名称real和tell同这两个值关联起来。当fib()结束时,栈顶指针重新指向以前的位置。新值没有被删除,但不再被标记,它们所占据的空间将被下一个将值加入到栈中的函数调用所使用(下图做了简化,因为函数调用可能传递其他信息,如返回地址)。

➂寄存器变量:
关键字register最初是由C语言引入的,它建议编译器使用CPU寄存器来存储自动变量:
register int count_fast; // 在【C中】是请求一个寄存器变量,旨在提高访问变量的速度。
在C++11之前,这个关键字在C++中的用法始终未变,只是随着硬件和编译器变得越来越复杂,这种提示表明变量用得很多,编译器可对其做特殊处理。在C++11中,这种提示作用也失去了,关键字register只是显式地指出变量是自动的。鉴于关键字register只能用于原本就是自动的变量,使用它的唯一原因是,指出程序员想使用一个自动变量,这个变量的名称可能与外部变量相同。这与auto以前的用途完全相同。然而,保留关键字register的重要原因是,避免使用了该关键字的现有代码非法。
➍静态持续变量:
首先,“静态”这个词不是指用static修饰的,它只是说明具有外部链接性。和C语言一样,C++也为静态存储持续性变量提供了3种链接性:外部链接性(可在其他文件中访问)、内部链接性(只能在当前文件中访问)和无链接性(只能在当前函数或代码块中访问)。注意:这3种链接性都在整个程序执行期间存在,与自动变量相比,它们的寿命更长。由于静态变量的数目在程序运行期间是不变的,因此程序不需要使用特殊的装置(如栈)来管理它们。编译器将分配固定的内存块来存储所有的静态变量,这些变量在整个程序执行期间一直存在。另外,如果没有显式地初始化静态变量,编译器将把它设置为0。在默认情况下,静态数组和结构将每个元素或成员的所有位都设置为0。
下面介绍如何创建这3种静态持续变量,然后介绍它们的特点。要想创建链接性为外部的静态持续变量,必须在代码块的外面声明它;要创建链接性为内部的静态持续变量,必须在代码块的外面声明它,并使用static限定符;要创建没有链接性的静态持续变量,必须在代码块内声明它,并使用static限定符。下面的代码片段说明这3种变量:
...
int global = 1000; // 静态存储,外部链接
static int one_file = 50; // 静态存储,内部链接
int main() {
...
}
void funct1(int n) {
static int count = 0; // 静态存储,无链接
int llama = 0; // 自动存储,无链接
...
}
void funct2(int q) {
...
}
正如前面指出的,所有静态持续变量(上述示例中的global、one_file和count)在整个程序执行期间都存在。在funct1( )中声明的变量count的作用域为局部,没有链接性,这意味着只能在funct1( )函数中使用它,就像自动变量llama一样。然而,与llama不同的是,即使在funct1( )函数没有被执行时,count也留在内存中。global和one_file的作用域都为整个文件,即在从声明位置到文件结尾的范围内都可以被使用。具体地说,可以在main( )、funct1( )和funct2( )中使用它们。由于one_file的链接性为内部,因此只能在包含上述代码的文件中使用它;由于global的链接性为外部,因此可以在程序的其他文件中使用它。
所有的静态持续变量都有下述初始化特征:未被初始化的静态变量的所有位都被设置为0。这种变量被称为零初始化的(zero-initialized)。
下表总结了引入名称空间之前使用的存储特性:

静态变量的初始化:
除默认的零初始化外,还可对静态变量进行常量表达式初始化和动态初始化。您可能猜到了,零初始化意味着将变量设置为零。对于标量类型,零将被强制转换为合适的类型。例如,在C++代码中,空指针用0表示,但内部可能采用非零表示,因此指针变量将被初始化相应的内部表示。结构成员被零初始化,且填充位都被设置为零。
零初始化和常量表达式初始化被统称为静态初始化,这意味着在编译器处理文件(翻译单元)时初始化变量。动态初始化意味着变量将在编译后初始化。
那么初始化形式由什么因素决定呢?首先,所有静态变量都被零初始化,而不管程序员是否显式地初始化了它。接下来,如果使用常量表达式初始化了变量,且编译器仅根据文件内容(包括被包含的头文件)就可计算表达式,编译器将执行常量表达式初始化。必要时,编译器将执行简单计算。如果没有足够的信息,变量将被动态初始化。请看下面的代码:
#include<cmath>
/* 以下都是静态变量 */
int x; // 初始化为0
int y = 5; // 初始化为数值字面量
long z = 13 * 13; // 初始化为常量表达式
const double pi = 4.0 *atan(1.0); // 动态初始化
首先,x、y、z和pi被零初始化。然后,编译器计算常量表达式,并将y和z分别初始化为5和169。但要初始化pi,必须调用函数atan(),这需要等到该函数被链接且程序执行时。常量表达式并非只能是使用字面常量的算术表达式,用sizeof()等都是可以的。
C++11新增了关键字constexpr,这增加了创建常量表达式的方式。但本书不会更详细地介绍C++11新增的这项新功能。
➎静态持续性、外部链接性:
链接性为外部的变量通常简称为外部变量,它们的存储持续性为静态,作用域为整个文件。外部变量是在函数外部定义的,因此对所有函数而言都是外部的。例如,可以在main( )前面或头文件中定义它们。可以在文件中位于外部变量定义后面的任何函数中使用它,因此外部变量也称全局变量(相对于局部的自动变量)。
一方面,在每个使用外部变量的文件中,都必须声明它;另一方面,C++有“单定义规则”(One Definition Rule,ODR),该规则指出,变量只能有一次定义。为满足这种需求,C++提供了两种变量声明。一种是定义声明(defining declaration)或简称为定义(definition),它给变量分配存储空间;另一种是引用声明(referencing declaration)或简称为声明(declaration),它不给变量分配存储空间,因为它引用已有的变量。
引用声明使用关键字extern,且不进行初始化;否则,声明为定义,导致分配存储空间:
double up; // 定义了up变量 up==0
extern int blem; // blem定义在了别的文件中
extern char gr = 'z'; // 只是个普通变量定义,因为被初始化了值
如果要在多个文件中使用外部变量,只需在一个文件中包含该变量的定义(单定义规则),但在使用该变量的其他所有文件中,都必须使用关键字extern声明它:
// file01.cpp
extern int cats = 20; // 普通定义(因为初始化了值)
int dogs = 20; // 普通定义
int fleas; // 普通定义
...
// file02.cpp -- 从file01.cpp中使用cats和dogs
extern int cats;
extern int dogs;
...
// file98.cpp -- 从file01.cpp中使用cats,dogs和fleas
extern int cats;
extern int dogs;
extern int fleas;
...
在这里,所有文件都使用了在file01.cpp中定义的变量cats和dogs,但file02.cpp没有重新声明变量fleas,因此无法访问它。在文件file01.cpp中,关键字extern并非必不可少的,因为即使省略它,效果也相同(参见下图)。

请注意,单定义规则并非意味着不能有多个变量的名称相同。例如,在不同函数中声明的同名自动变量是彼此独立的,它们都有自己的地址。另外,正如后面的示例将表明的,局部变量可能隐藏同名的全局变量。然而,虽然程序中可包含多个同名的变量,但每个变量都只有一个定义。
如果在函数中声明了一个与外部变量同名的变量,结果将如何呢?这种声明将被视为一个自动变量的定义,当程序执行自动变量所属的函数时,该变量将位于作用域内。下面程序清单在两个文件中使用了一个外部变量,还演示了自动变量将隐藏同名的全局变量。它还演示了如何使用关键字extern来重新声明以前定义过的外部变量,以及如何使用C++的作用域解析运算符来访问被隐藏的外部变量。
// support.cpp
#include <iostream>
double warming = 0.3;
void update(double dt);
void local();
using std::cout;
void update(double dt) { // 修改全局变量
warming += dt; // 使用全局变量:warming
cout << "Updating global warming to " << warming;
cout << " degrees.\n";
}
void local() { // 使用本地变量
double warming = 0.8; // 与全局变量同名的局部变量,因此与外部变量无关系
cout << "Local warming = " << warming << " degrees.\n";
// 访问全局变量,使用作用域解析运算符“::”!!!!!!
cout << "But global warming = " << ::warming;
cout << " degrees.\n";
}
// external.cpp
#include <iostream>
extern double warming;
extern void update(double dt);
extern void local();
using namespace std;
int main() {
extern double warming; // 可选的重声明
cout << "Global warming is " << warming << " degrees.\n";
update(0.1); // call function to change warming
cout << "Global warming is " << warming << " degrees.\n";
local(); // call function with local warming
cout << "Global warming is " << warming << " degrees.\n";
return 0;
}
Global warming is 0.3 degrees.
Updating global warming to 0.4 degrees.
Global warming is 0.4 degrees.
Local warming = 0.8 degrees.
But global warming = 0.4 degrees.
Global warming is 0.4 degrees.
程序的输出表明,main( )和update( )都可以访问外部变量warming。注意,update( )修改了warming,这种修改在随后使用该变量时显现出来了。对于函数也是一样用extern声明是从外部引用的函数,而对于引用外部函数extern关键字可省略,但加上去代码更清晰。
C++比C语言更进了一步——它提供了作用域解析运算符(::)。放在变量名前面时,该运算符表示使用变量的全局版本。因此,local( )将warming显示为0.8,但将::warming显示为0.4。后面介绍名称空间和类时,将再次介绍该运算符。从清晰和避免错误的角度说,相对于使用warming并依赖于作用域规则,在函数update()中使用::warming是更好的选择,也更安全。
既然可以选择使用全局变量或局部变量,那么到底应使用哪种呢?首先,全局变量很有吸引力——因为所有的函数能访问全局变量,因此不用传递参数。但易于访问的代价很大——程序不可靠。计算经验表明,程序越能避免对数据进行不必要的访问,就越能保持数据的完整性。通常情况下,应使用局部变量,应在需要知晓时才传递数据,而不应不加区分地使用全局变量来使数据可用。读者将会看到,OOP在数据隔离方面又向前迈进了一步。
然而,全局变量也有它们的用处。例如,可以让多个函数可以使用同一个数据块(如月份名数组或原子量数组)。外部存储尤其适于表示常量数据,因为这样可以使用关键字const来防止数据被修改。注:这只能放在.h头文件中,原因在“再谈const”部分有解释。
const char * const months[12] = { "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" };在上述示例中,第一个const防止字符串被修改,第二个const确保数组中每个指针始终指向它最初指向的字符串。
➏静态持续性、内部链接性:
将static限定符用于作用域为整个文件的变量时,该变量的链接性将为内部的。在多文件程序中,内部链接性和外部链接性之间的差别很有意义。链接性为内部的变量只能在其所属的文件中使用;但常规外部变量都具有外部链接性,即可以在其他文件中使用,如前面的示例所示。
如果要在其他文件中使用相同的名称来表示其他变量,该如何办呢?只需省略关键字extern即可吗?
// file1
int errors = 20; // 外部声明
...
----------------------------
// file2
int errors = 5; // 外部声明
void froobish() {
cout << errors; // 失败!!!!!!
...
}
以上做法将失败,因为它违反了单定义规则。file2中的定义试图创建一个外部变量,因此程序将包含errors的两个定义,这是错误。
但如果文件定义了一个静态外部变量,其名称与另一个文件中声明的常规外部变量相同,则在该文件中,静态变量将隐藏常规外部变量:
// file1
int errors = 20; // 外部声明
...
-------------------------------------------------
// file2
#include <iostream>
void froobish();
extern int errors;
int main() {
static int errors = 5;
std::cout << errors << endl; // 输出的是 file2 中的errors
froobish();
}
void froobish() {
std::cout << errors; // 输出的是 file1 中的errors
}
-------------------------------------------------
程序输出:
5
20
-------------------------------------------------
如果把static int errors = 5;这行移到main()函数外,则会隐藏全局变量,输出为:
5
5
file1与file2中也是有相同的变量名,但这没有违反单定义规则,因为关键字static指出标识符errors的链接性为内部,因此并非要提供外部定义。
可使用外部变量在多文件程序的不同部分之间共享数据;可使用链接性为内部的静态变量在同一个文件中的多个函数之间共享数据(名称空间提供了另外一种共享数据的方法)。另外,如果将作用域为整个文件的变量变为静态的,就不必担心其名称与其他文件中的作用域为整个文件的变量发生冲突。
// file1.cpp
#include <iostream>
extern int tom; // 引用外部变量
static int dick = 10; // 静态内部链接,隐藏了外部同名变量
int harry = 200; // 外部链接
void remote_access() {
using namespace std;
cout << "remote_access() reports the following addresses:\n";
cout << &tom << " = &tom, " << &dick << " = &dick, ";
cout << &harry << " = &harry\n";
}
// file2.cpp -- 和file1.cpp一起编译
#include <iostream>
int tom = 3; // 外部链接
int dick = 30; // 外部链接
static int harry = 300; // 静态内部链接,隐藏了外部同名变量
extern int harry; // 引用外部变量
extern void remote_access(); // 引用外部函数(extern关键字非必须)
int main() {
using namespace std;
cout << "main() reports the following addresses:\n";
cout << &tom << " = &tom, " << &dick << " = &dick, ";
cout << &harry << " = &harry\n";
remote_access();
return 0;
}
main() reports the following addresses:
00E0C000 = &tom, 00E0C004 = &dick, 00E0C008 = &harry
remote_access() reports the following addresses:
00E0C000 = &tom, 00E0C014 = &dick, 00E0C010 = &harry
从运行结果:在两个文件中打印出的两个tom变量的地址将相同,而两个dick和harry变量的地址不同。可知,在同一文件中static隐藏外部同名变量,并且extern声明的外部变量对于两个文件确实是全局的。
➐静态存储持续性、无链接性:
至此,介绍了链接性分别为内部和外部、作用域为整个文件的变量。接下来介绍静态持续家族中的第三个成员——无链接性的局部变量。这种变量是这样创建的,将static限定符用于在代码块中定义的变量。在代码块中使用static时,将导致局部变量的存储持续性为静态的。这意味着虽然该变量只在该代码块中可用,但它在该代码块不处于活动状态时仍然存在。因此在两次函数调用之间,静态局部变量的值将保持不变。(静态变量适用于再生——可以用它们将瑞士银行的秘密账号传递到下一个要去的地方)。另外,如果初始化了静态局部变量,则程序只在启动时进行一次初始化。以后再调用函数时,将不会像自动变量那样再次被初始化。
#include <iostream>
const int ArSize = 10;
void strcount(const char* str);
int main() {
using namespace std;
char input[ArSize];
char next;
cout << "Enter a line:\n";
cin.get(input, ArSize);
while (cin) {
cin.get(next);
while (next != '\n') // string didn't fit!
cin.get(next); // dispose of remainder
strcount(input);
cout << "Enter next line (empty line to quit):\n";
cin.get(input, ArSize);
}
cout << "Bye\n";
return 0;
}
void strcount(const char* str) {
using namespace std;
static int total = 0; // static local variable
int count = 0; // automatic local variable
cout << "\"" << str << "\" contains ";
while (*str++) // go to end of string
count++;
total += count;
cout << count << " characters\n";
cout << total << " characters total\n";
}
Enter a line:
|nice pants
"nice pant" contains 9 characters
9 characters total
Enter next line (empty line to quit):
|thanks
"thanks" contains 6 characters
15 characters total
Enter next line (empty line to quit):
|parting is such sweet sorrow
"parting i" contains 9 characters
24 characters total
Enter next line (empty line to quit):
|ok
"ok" contains 2 characters
26 characters total
Enter next line (empty line to quit):
Bye
通过断点调试发现函数strcount()中static int total = 0;这行代码从开始到结束都是直接跳过的,即在程序载入时它就被初始化了,并且static变量只会被初始化一次(默认初始化为0),即不可能存在第二次的初始化。对于之后的对它的赋值等操作就和一般的变量一样了。
由于数组长度为10,因此程序从每行读取的字符数都不超过9个。另外还需要注意的是,每次函数被调用时,自动变量count都被重置为0。然而,静态变量total只在程序运行时被设置为0,以后在两次函数调用之间,其值将保持不变,因此能够记录读取的字符总数。
➑说明符和限定符:
➀存储说明符:
- auto(在C++11中不再是说明符)
- register
- static
- extern
- thread_local(C++11新增的)
- mutable
其中的大部分已经介绍过了,在同一个声明中不能使用多个说明符,但thread_local除外,它可与static或extern结合使用。前面讲过,在C++11之前,可以在声明中使用关键字auto指出变量为自动变量;但在C++11中,auto用于自动类型推断。关键字register用于在声明中指示寄存器存储,而在C++11中,它只是显式地指出变量是自动的。关键字static被用在作用域为整个文件的声明中时,表示内部链接性;被用于局部声明中,表示局部变量的存储持续性为静态的。关键字extern表明是引用声明,即声明引用在其他地方定义的变量。关键字thread_local指出变量的持续性与其所属线程的持续性相同。thread_local变量之于线程,犹如常规静态变量之于整个程序。关键字mutable的含义将根据const来解释,因此先来介绍cv-限定符,然后再解释它。
➁cv-限定符:
- const
- volatile
cv表示const和volatile。最常用的cv-限定符是const,而读者已经知道其用途。它表明,内存被初始化后,程序便不能再对它进行修改。稍后再回过头来介绍它。
关键字volatile表明,即使程序代码没有对内存单元进行修改,其值也可能发生变化。听起来似乎很神秘,实际上并非如此。例如,可以将一个指针指向某个硬件位置,其中包含了来自串行端口的时间或信息。在这种情况下,硬件(而不是程序)可能修改其中的内容。或者两个程序可能互相影响,共享数据。该关键字的作用是为了改善编译器的优化能力。例如,假设编译器发现,程序在几条语句中两次使用了某个变量的值,则编译器可能不是让程序查找这个值两次,而是将这个值缓存到寄存器中。这种优化假设变量的值在这两次使用之间不会变化。如果不将变量声明为volatile,则编译器将进行这种优化;将变量声明为volatile,相当于告诉编译器,不要进行这种优化。
mutable:
可以用mutable来指出,即使结构(或类)变量为const,其某个成员也可以被修改。例如,请看下面的代码:
struct data {
char name[30];
mutable int accesses;
...
};
const data veep = {"Claybourne Clodde", 0, ...};
strcpy(veep.name, "Joye Joux"); // 不允许
veep.accesses ++; // 允许
veep的const限定符禁止程序修改veep的成员,但access成员的mutable说明符使得access不受这种限制。
本书不使用volatile或mutable,但将进一步介绍const。
再谈const:
在C++(但不是在C语言)中,const限定符对默认存储类型稍有影响。在默认情况下全局变量的链接性为外部的,但const全局变量的链接性为内部的。也就是说,在C++看来,全局const定义(如下述代码段所示)就像使用了static说明符一样。
const int finger = 10;
类似于:static const int finger = 10;
int main() {
...
C++修改了常量类型的规则,让程序员更轻松。例如,假设将一组常量放在头文件中,并在同一个程序的多个文件中使用该头文件。那么,预处理器将头文件的内容包含到每个源文件中后,所有的源文件都将包含类似下面这样的定义:
const int fingers = 10;
const char * warning = "Wak!";
如果全局const声明的链接性像常规变量那样是外部的,则根据单定义规则,这将出错。也就是说,只能有一个文件可以包含前面的声明,而其他文件必须使用extern关键字来提供引用声明。
extern const int fingers;
extern const char * warning;
// file1.cpp
const int x = 10;
-----------------
// file2.cpp
extern const int x; // 运行报错:unresolved external symbol "int const x"
/* 这正说明file1中的const int x=10;
是内部链接性,只有在file1内可访问。*/
int main() {
cout << x;
}
-------------------
-------------------
// dolly.h
const int x = 10; // 放在头文件
// filey.cpp
#include "dolly.h"// 通过包含头文件,解决了上述问题
extern const int x;
int main() {
cout << x; // 输出:10
}
内部链接性还意味着,每个文件都有自己的一组常量,而不是所有文件共享一组常量。每个定义都是其所属文件私有的,这就是能够将常量定义放在头文件中的原因。这样,只要在两个源代码文件中包括同一个头文件,则它们将获得同一组常量。
如果出于某种原因,程序员希望某个常量的链接性为外部的,则可以使用extern关键字来覆盖const默认的内部链接性:
extern const status = 50;
在这种情况下,必须在所有使用该常量的文件中使用extern关键字来声明它。这与常规外部变量不同,定义常规外部变量时,不必使用extern关键字,但在使用该变量的其他文件中必须使用extern。然而,请记住,鉴于单个const在多个文件之间共享,因此只有一个文件可对其进行初始化。
➒函数的链接性:
和变量一样,函数也有链接性,虽然可选择的范围比变量小。和C语言一样,C++不允许在一个函数中定义另外一个函数,因此所有函数的存储持续性都自动为静态的,即在整个程序执行期间都一直存在。在默认情况下,函数的链接性为外部的,即可以在文件间共享。实际上,可以在函数原型中使用关键字extern来指出函数是在另一个文件中定义的,不过这是可选的(要让程序在另一个文件中查找函数,该文件必须作为程序的组成部分被编译,或者是由链接程序搜索的库文件)。还可以使用关键字static将函数的链接性设置为内部的,使之只能在一个文件中使用。必须同时在原型和函数定义中使用该关键字:
static int private(double x); // 函数原型
int main() {
...
}
static int private(double x) { // 函数定义
...
}
这意味着该函数只在这个文件中可见,还意味着可以在其他文件中定义同名的的函数。和变量一样,在定义静态函数的文件中,静态函数将覆盖外部定义,因此即使在外部定义了同名的函数,该文件仍将使用静态函数。
单定义规则也适用于非内联函数,因此对于每个非内联函数,程序只能包含一个定义。对于链接性为外部的函数来说,这意味着在多文件程序中,只能有一个文件(该文件可能是库文件,而不是您提供的)包含该函数的定义,但使用该函数的每个文件都应包含其函数原型。
内联函数不受这项规则的约束,这允许程序员能够将内联函数的定义放在头文件中。这样,包含了头文件的每个文件都有内联函数的定义。然而,C++要求同一个函数的所有内联定义都必须相同。
假设在程序的某个文件中调用一个函数,C++将到哪里去寻找该函数的定义呢?如果该文件中的函数原型指出该函数是静态的,则编译器将只在该文件中查找函数定义;否则,编译器(包括链接程序)将在所有的程序文件中查找。如果找到两个定义,编译器将发出错误消息,因为每个外部函数只能有一个定义。如果在程序文件中没有找到,编译器将在库中搜索。这意味着如果定义了一个与库函数同名的函数,编译器将使用程序员定义的版本,而不是库函数(然而,C++保留了标准库函数的名称,即程序员不应使用它们)。有些编译器-链接程序要求显式地指出要搜索哪些库。
➓语言链接性:
另一种形式的链接性——称为语言链接性(language linking)也对函数有影响。首先介绍一些背景知识。链接程序要求每个不同的函数都有不同的符号名。在C语言中,一个名称只对应一个函数,因此这很容易实现。为满足内部需要,C语言编译器可能将spiff这样的函数名翻译为_spiff。这种方法被称为C语言链接性(C language linkage)。但在C++中,同一个名称可能对应多个函数,必须将这些函数翻译为不同的符号名称。因此,C++编译器执行名称矫正或名称修饰(参见第8章),为重载函数生成不同的符号名称。例如,可能将spiff(int)转换为_spoff_i,而将spiff(double, double)转换为_spiff_d_d。这种方法被称为C++语言链接(C++ language linkage)。
链接程序寻找与C++函数调用匹配的函数时,使用的方法与C语言不同。但如果要在C++程序中使用C库中预编译的函数,将出现什么情况呢?例如,假设有下面的代码:
spiff(22); // 想从C库调用此函数
它在C库文件中的符号名称为_spiff,但对于我们假设的链接程序来说,C++查询约定是查找符号名称_spiff_i。为解决这种问题,可以用函数原型来指出要使用的约定:
extern "C" void spiff(int); // 使用C规则查找函数名
extern void spoff(int); // 使用C++规则查找函数名
extern "C++" void spaff(int); // 使用C++规则查找函数名
第1个原型使用C语言链接性;而后面的2个使用C++语言链接性。第2个原型是通过默认方式指出这一点的,而第3个显式地指出了这一点。
C和C++链接性是C++标准指定的说明符,但实现可提供其他语言链接性说明符。
⓫存储方案和动态分配:
前面介绍C++用来为变量(包括数组和结构)分配内存的5种方案(线程内存除外),它们不适用于使用C++运算符new(或C函数malloc( ))分配的内存,这种内存被称为动态内存。第4章介绍过,动态内存由运算符new和delete控制,而不是由作用域和链接性规则控制。因此,可以在一个函数中分配动态内存,而在另一个函数中将其释放。与自动内存不同,动态内存不是LIFO,其分配和释放顺序要取决于new和delete在何时以何种方式被使用。通常,编译器使用三块独立的内存:一块用于静态变量(可能再细分),一块用于自动变量,另外一块用于动态存储。
虽然存储方案概念不适用于动态内存,但适用于用来跟踪动态内存的自动和静态指针变量。例如,假设在一个函数中包含下面的语句:
float * p_fees = new float[20];
由new分配的80个字节(假设float为4个字节)的内存将一直保留在内存中,直到使用delete运算符将其释放。但当包含该声明的语句块执行完毕时,p_fees指针将消失。如果希望另一个函数能够使用这80个字节中的内容,则必须将其地址传递或返回给该函数。另一方面,如果将p_fees的链接性声明为外部的,则文件中位于该声明后面的所有函数都可以使用它。另外,通过在另一个文件中使用下述声明,便可在其中使用该指针:
extern float * p_fees;
// file1.cpp
int x;
// file2.cpp
#include<iostream>
extern int x;
void print2() {
x = 4;
std::cout << x << std::endl;
}
// file.cpp
#include<iostream>
extern int x; //如果给x赋值,则:Error LNK2005 "int x" (? x@@3HA) already defined in file1.obj
extern void print2();
int main() {
x = 5;
std::cout << x << std::endl;
print2();
std::cout << x << std::endl;
return 0;
}
######输出######
5
4
4
上例也证明了extern只能用于引用外部变量不能extern x = 5;这样在声明时初始化它,否则“Error already defined”。还可以看到file1.cpp中定义的int x;确实是全局的,file2.cpp和file3.cpp都可以引用它,修改它也是修改原来file1.cpp中的全局int x;
①使用new运算符初始化:
如果要初始化动态分配的变量,该如何办呢?在C++98中,有时候可以这样做,C++11增加了其他可能性。下面先来看看C++98提供的可能性。
如果要为内置的标量类型(如int或double)分配存储空间并初始化,可在类型名后面加上初始值,并将其用括号括起:
int *pi = new int(6); // *pi set to 6
double *pd = new double(99.99); // *pd set to 99.99
然而,要初始化常规结构或数组,需要使用大括号{}的列表初始化,这要求编译器支持C++11。C++11允许您这样做:
struct where {double x, double y, double z};
where * one = new where{2.5, 5.3, 7.2}; // C++11
int * ar = new int[4]{2, 4, 6, 8}; // C++11
// 对于complier versoion < C++11
where * _one = new where; // 为结构分配空间,之后单独给成员赋值
int * _ar = new int[4]; // 为数组分配空间,之后再给元素单独赋值
在C++11中,还可将列表初始化用于单值变量:
int *pin = new int{6}; // *pin set to 6
double *pdo = new double{99.99}; // *pdo set to 99.99
②new失败时:
new可能找不到请求的内存量。在最初的10年中,C++在这种情况下让new返回空指针,但现在将引发异常std::bad_alloc。
③new: 运算符、函数和替换函数
运算符new和new[]分别调用如下函数:
void * operator new(std::size_t); // 使用函数new(SIZE)
void * operator new[](std::size_t); // 使用函数new[](SIZE)
这些函数被称为分配函数(alloction function),它们位于全局名称空间中。同样,也有由delete和delete[]调用的释放函数(deallocation function):
void operator delete(void *);
void operator delete[](void *);
std::size_t是一个typedef,对应于合适的整型。对于下面这样的基本语句,会有个自动转换:
int * pi = new int; // new:运算符
被转换为:
int * pi = new(sizeof(int)); // new():函数
----------------------------
int *pa = new int[40];
被转换为:
int *pa = new(40 * sizeof(int));
正如您知道的,使用运算符new的语句也可包含初始值,因此,使用new运算符时,可能不仅仅是调用new()函数。
对于delete同样有自动转换:
delete pi; // delete:运算符
被转换为:
delete(pi); // delete()函数
有趣的是,C++将这些函数称为可替换的(replaceable)。这意味着如果您有足够的知识和意愿,可为new和delete提供替换函数,并根据需要对其进行定制。例如,可定义作用域为类的替换函数,并对其进行定制,以满足该类的内存分配需求。在代码中,仍将使用new运算符,但它将调用您定义的new()函数。
④定位new运算符:
通常,new负责在堆(heap)中找到一个足以能够满足要求的内存块。new运算符还有另一种变体,被称为定位(placement)new运算符,它让您能够指定要使用的位置。程序员可能使用这种特性来设置其内存管理规程、处理需要通过特定地址进行访问的硬件或在特定位置创建对象。
C语言中int setvbuf(FILE * stream, char * buf, int type, unsigned size);函数与定位new运算符有类似之处。
要使用定位new特性,首先需要包含头文件new,它提供了这种版本的new运算符的原型;然后将new运算符用于提供了所需地址的参数。除需要指定参数外,句法与常规new运算符相同。具体地说,使用定位new运算符时,变量后面可以有方括号,也可以没有。下面的代码段演示了new运算符的4种用法:
#include <new>
struct chaff {
char dross[20];
int slag;
};
char buffer1[50];
char buffer2[500];
int main() {
chaff *p1, *p2;
int *p3, *p4;
p1 = new chaff; // 把结构放进堆中
p3 = new int[20]; // 把int数组放进堆中
// 两种形式的new替换
p2 = new (buffer1) chaff; // 把结构放进buffer1
p4 = new (buffer2) int[20]; // 把int数组放进buffer2
...
}
出于简化的目的,这个示例使用两个静态数组来为定位new运算符提供内存空间。因此,上述代码从buffer1中分配空间给结构chaff,从buffer2中分配空间给一个包含20个元素的int数组。
熟悉定位new运算符后,来看一个示例程序。程序清单使用常规new运算符和定位new运算符创建动态分配的数组。该程序说明了常规new运算符和定位new运算符之间的一些重要差别,在查看该程序的输出后,将对此进行讨论。
#include <iostream>
#include <new> // for placement new
const int BUF = 512;
const int N = 5;
char buffer[BUF]; // 内存块
int main() {
using namespace std;
double* pd1, * pd2;
int i;
cout << "Calling new and placement new:\n";
pd1 = new double[N]; // use heap
pd2 = new (buffer) double[N]; // use buffer array
for (i = 0; i < N; i++)
pd2[i] = pd1[i] = 1000 + 20.0 * i;
cout << "Memory addresses:\n" << " heap: " << pd1
<< " static: " << (void*)buffer << endl;
cout << "Memory contents:\n";
for (i = 0; i < N; i++) {
cout << pd1[i] << " at " << &pd1[i] << "; ";
cout << pd2[i] << " at " << &pd2[i] << endl;
}
/* ---------------------------------------------------------- */
cout << "\nCalling new and placement new a second time:\n";
double* pd3, * pd4;
pd3 = new double[N]; // find new address
pd4 = new (buffer) double[N]; // 覆盖旧数据!
for (i = 0; i < N; i++)
pd4[i] = pd3[i] = 1000 + 40.0 * i;
cout << "Memory contents:\n";
for (i = 0; i < N; i++) {
cout << pd3[i] << " at " << &pd3[i] << "; ";
cout << pd4[i] << " at " << &pd4[i] << endl;
}
/* ---------------------------------------------------------- */
cout << "\nCalling new and placement new a third time:\n";
delete[] pd1;
pd1 = new double[N];
pd2 = new (buffer + N * sizeof(double)) double[N];
for (i = 0; i < N; i++)
pd2[i] = pd1[i] = 1000 + 60.0 * i;
cout << "Memory contents:\n";
for (i = 0; i < N; i++) {
cout << pd1[i] << " at " << &pd1[i] << "; ";
cout << pd2[i] << " at " << &pd2[i] << endl;
}
delete[] pd1;
delete[] pd3;// pd2、pd4是定位new,不delete,否则出错。它自有常规生命周期!
return 0;
}
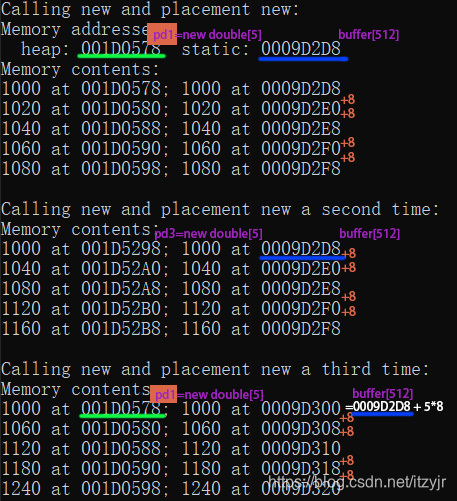
关于程序清单,首先要指出的一点是,定位new运算符确实将数组p2放在了数组buffer中,p2和buffer的地址都是0009D2D8。然而,它们的类型不同,p1是double指针,而buffer是char指针(顺便说一句,这也是程序使用(void *)对buffer进行强制转换的原因,如果不这样做,cout将显示一个字符串)同时,常规new将数组p1放在很远的地方,其地址为001D0578,位于动态管理的堆中。
为什么总有new(buffer + N*sizeof(double))的地址=buffer的地址+N*sizeof(double),因为new()括号里面buffer是个指针,而N*sizeof(double)是个数字常量,所以相当于buffer指针指向右移了N*sizeof(double)个单位,所以new(buffer)地址同buffer,new(buffer+M)地址同buffer+M,还有一点就是这时候new(buffer+M)相当于在新地址buffer+M新起一个sizeof(buffer)+M的内存空间。所以&pd2[0]!=buffer,而是&pd2[0] == buffer + M。
需要指出的第二点是,第二个常规new运算符查找一个新的内存块,其起始地址为001D5298;但第二个定位new运算符分配与以前相同的内存块:起始地址为0009D2D8的内存块。定位new运算符使用传递给它的地址,它不跟踪哪些内存单元已被使用,也不查找未使用的内存块。这将一些内存管理的负担交给了程序员。例如,在第三次调用定位new运算符时,提供了一个从数组buffer开头算起的偏移量,因此将分配新的内存:
pd2 = new (buffer + N * sizeof(double)) double[N]; // 偏移40个字节
第三点差别是,是否使用delete来释放内存。对于常规new运算符,下面的语句释放起始地址为001D0578的内存块,因此接下来再次调用new运算符时,该内存块是可用的:
delete[] pd1;
然而,程序清单中的程序没有使用delete来释放使用定位new运算符分配的内存。事实上,在这个例子中不能这样做。buffer指定的内存是静态内存,而delete只能用于这样的指针:指向常规new运算符分配的堆内存。也就是说,数组buffer位于delete的管辖区域之外,下面的语句将引发运行阶段错误:
delete[] pd2; // 不会工作
另一方面,如果buffer是使用常规new运算符创建的,便可以使用常规delete运算符来释放整个内存块。
定位new运算符的另一种用法是,将其与初始化结合使用,从而将信息放在特定的硬件地址处。
您可能想知道定位new运算符的工作原理。基本上,它只是返回传递给它的地址,并将其强制转换为void *,以便能够赋给任何指针类型。但这说的是默认定位new函数,C++允许程序员重载定位new函数。
⑤定位new的其他形式:
就像常规new调用一个接收一个参数的new()函数一样,标准定位new调用一个接收两个参数的new()函数:
int * pi = new int; // invokes new(sizeof(int))
int * p2 = new(buffer) int; // invokes new(sizeof(int), buffer)
int * p3 = new(buffer) int[40]; // invokes new(40*sizeof(int), buffer) <-将40个int大小空间放入buffer中
定位new函数不可替换,但可重载。它至少需要接收两个参数,其中第一个总是std::size_t,指定了请求的字节数。这样的重载函数都被称为定义new,即使额外的参数没有指定位置。
名称空间:
在C++中,名称可以是变量、函数、结构、枚举、类以及类和结构的成员。当随着项目的增大,名称相互冲突的可能性也将增加。使用多个厂商的类库时,可能导致名称冲突。例如,两个库可能都定义了名为List、Tree和Node的类,但定义的方式不兼容。用户可能希望使用一个库的List类,而使用另一个库的Tree类。这种冲突被称为名称空间问题。
C++标准提供了名称空间工具,以便更好地控制名称的作用域。经过了一段时间后,编译器才支持名称空间,但现在这种支持很普遍。
❶C++名称空间简介:
介绍C++中新增的名称空间特性之前,先复习一下C++中已有的名称空间属性,并介绍一些术语,让读者熟悉名称空间的概念。
第一个需要知道的术语是声明区域(declaration region)。声明区域是可以在其中进行声明的区域。例如,可以在函数外面声明全局变量,对于这种变量,其声明区域为其声明所在的文件。对于在函数中声明的变量,其声明区域为其声明所在的代码块。
第二个需要知道的术语是潜在作用域(potential scope)。变量的潜在作用域从声明点开始,到其声明区域的结尾。因此潜在作用域比声明区域小,这是由于变量必须定义后才能使用。
然而,变量并非在其潜在作用域内的任何位置都是可见的。例如,它可能被另一个在嵌套声明区域中声明的同名变量隐藏。例如,在函数中声明的局部变量(对于这种变量,声明区域为整个函数)将隐藏在同一个文件中声明的全局变量(对于这种变量,声明区域为整个文件)。变量对程序而言可见的范围被称为作用域(scope),前面正是以这种方式使用该术语的。下面两图分别对术语声明区域、潜在作用域和作用域进行了说明。
C++关于全局变量和局部变量的规则定义了一种名称空间层次。每个声明区域都可以声明名称,这些名称独立于在其他声明区域中声明的名称。在一个函数中声明的局部变量不会与在另一个函数中声明的局部变量发生冲突。


❷名称空间namespace特性:
C++新增了这样一种功能,即通过定义一种新的声明区域来创建命名的名称空间,这样做的目的之一是提供一个声明名称的区域。一个名称空间中的名称不会与另外一个名称空间的相同名称发生冲突,同时允许程序的其他部分使用该名称空间中声明的东西。例如,下面的代码使用新的关键字namespace创建了两个名称空间:Jack和Jill。
namespace Jack {
double pail; // 变量声明
void fetch(); // 函数原型
int pal; // 变量声明
struct Well {...}; // 结构声明
}
namespace Jill {
double bucket(double n) {...} // 函数定义
double fetch; // 变量声明
int pal; // 变量声明
struct Hill {...}; // 结构声明
}
名称空间可以是全局的,也可以位于另一个名称空间中,但不能位于代码块中。因此,在默认情况下,在名称空间中声明的名称的链接性为外部的(除非它引用了常量)。
除了用户定义的名称空间外,还存在另一个名称空间——全局名称空间(global namespace)。它对应于文件级声明区域,因此前面所说的全局变量现在被描述为位于全局名称空间中。
任何名称空间中的名称都不会与其他名称空间中的名称发生冲突。因此,Jack中的fetch可以与Jill中的fetch共存,Jill中的Hill可以与外部Hill共存。名称空间中的声明和定义规则同全局声明和定义规则相同。
名称空间是开放的(open),即可以把名称加入到已有的名称空间中。例如,下面这条语句将名称goose添加到Jill中已有的名称列表中:
namespace Jill {
char * goose(const char *);
}
同样,原来的Jack名称空间为fetch( )函数提供了原型。可以在该文件后面(或另外一个文件中)再次使用Jack名称空间来提供该函数的代码:
namespace Jack {
void fetch() {
...
}
}
当然,需要有一种方法来访问给定名称空间中的名称。最简单的方法是,通过作用域解析运算符::,使用名称空间来限定该名称:
Jack::pail = 12.34; // 使用一个变量
Jill::Hill mole; // 创建一个类型为Hill的结构
Jack::fetch(); // 使用一个函数
未被装饰的名称(如pail)称为未限定的名称(unqualified name);包含名称空间的名称(如Jack::pail)称为限定的名称(qualified name)。
①using声明和using编译指令:
我们并不希望每次使用名称时都对它进行限定,因此C++提供了两种机制(using声明和using编译指令)来简化对名称空间中名称的使用。using声明使特定的标识符可用,using编译指令使整个名称空间可用。
using声明由被限定的名称和它前面的关键字using组成:
using Jill::fetch; // 使用声明
using声明将特定的名称添加到它所属的声明区域中。例如main( )中的using声明Jill::fetch将fetch添加到main( )定义的声明区域中。完成该声明后,便可以使用名称fetch代替Jill::fetch。下面的代码段说明了这几点:
#include<iostream>
namespace Jill {
double fetch;
}
double fetch;
int main() {
std::cout << &fetch << std::endl;
using Jill::fetch; // 将fetch放入【局部名称空间】main(){}块作用域
std::cin >> fetch; // 读取一个值到Jill::fetch
std::cin >> ::fetch; // 读取一个值到全局fetch
std::cout << fetch << "|" << ::fetch << std::endl;
std::cout << &fetch << "|" << &(::fetch);
}

由于using声明将名称添加到局部声明区域中,因此这个示例避免了将另一个局部变量也命名为fetch。另外,和其他局部变量一样,fetch也将覆盖同名的全局变量。
在函数的外面使用using声明时,将把名称添加到全局名称空间中:
void other();
namespace Jill {
double bucket(double n) {...};
double fetch;
struct Hill {...};
}
using Jill::fetch; // 将fetch放入【全局名称空间】在main(){}块外using
int main() {
cin >> fetch; //读取一个值到Jill::fetch
other();
...
}
void other() {// 如果函数第一行加上:double fetch = 100;则输出100
// 这时如果要输出Jill空间的值,就要显示指定:cout << Jill::fetch;
cout << fetch; // 显示Jill::fetch
...
}
如果上述代码首行添加double fetch;则运行报错:Error C2874 using-declaration causes a multiple declaration of 'fetch'
如果有如下代码,则输出:1,1,100
#include <iostream>
void output();
double fetch = 1;
namespace Jill {
double fetch;
}
int main() {
using Jill::fetch;// 如果此行放到main(){}外,
// 则报错:using-declaration causes a multiple declaration of 'fetch'
fetch = 100;
output();
return 0;
}
void output() {
std::cout << fetch << "," << ::fetch << "," << Jill::fetch;
}
using声明使一个名称可用,而using编译指令使所有的名称都可用。using编译指令由名称空间名和它前面的关键字using namespace组成,它使名称空间中的所有名称都可用,而不需要使用作用域解析运算符:
using namespace Jack; // 使所有的Jack下的名称可用
在全局声明区域中使用using编译指令,将使该名称空间的名称全局可用。这种情况已出现过多次:
#include<iostream> // 将名称都放入名称空间std
using namespace std; // 使所有名称全局可用
在函数中使用using编译指令,将使其中的名称在该函数中可用,下面是一个例子:
int main() {
using namespace Jack; // 使所有名称在main()可用
...
}
在本书前面中,经常将这种格式用于名称空间std。
有关using编译指令和using声明,需要记住的一点是,它们增加了名称冲突的可能性。也就是说,如果有名称空间jack和jill,并在代码中使用作用域解析运算符,则不会存在二义性:
Jack::pal = 3;
Jill::pal = 10;
变量Jack::pal和Jill::pal是不同的标识符,表示不同的内存单元。然而,如果使用using声明,情况将发生变化:
using Jack::pal;
using Jill:pal;
pal = 4; // 使用哪一个?这就有一个冲突了
事实上,编译器不允许您同时使用上述两个using声明,因为这将导致二义性。
②using编译指令和using声明之比较:
using std::cout; // using 声明
using namespace std; // using 编译指令,导入std里面的所有名称。
一般使用using 声明,它只会导入指定的名称,这样更安全,当与局部重名时会报错。
使用using编译指令,与局部变量重名时,则会覆盖命名空间中的同名成员,而不会报错。
使用using编译指令导入一个名称空间中所有的名称与使用多个using声明是不一样的,而更像是大量使用作用域解析运算符。使用using声明时,就好像声明了相应的名称一样。如果某个名称已经在函数中声明了,则不能用using声明导入相同的名称。然而,使用using编译指令时,将进行名称解析,就像在包含using声明和名称空间本身的最小声明区域中声明了名称一样。在下面的示例中,名称空间为全局的。如果使用using编译指令导入一个已经在函数中声明的名称,则局部名称将隐藏名称空间名,就像隐藏同名的全局变量一样。不过仍可以像下面的示例中那样使用作用域解析运算符:
namespace Jill {
double bucket(double n) {...};
double fetch;
struct Hill {...};
}
char fetch;
int main() {
using namespace Jill;
Hill Thrill;
double water = bucket(2);
double fetch;
cin >> fetch;
cin >> ::fetch;
cin >> Jill::fetch;
...
}
int foom() {
Hill top; // 错误
Jill::Hill crest; // 有效
}
在main( )中,名称Jill::fetch被放在局部名称空间中,但其作用域不是局部的,因此不会覆盖全局的fetch。然而,局部声明的fetch将隐藏Jill::fetch和全局fetch。然而,如果使用作用域解析运算符,则后两个fetch变量都是可用的。读者应将这个示例与前面使用using声明的示例进行比较。
需要指出的另一点是,虽然函数中的using编译指令将名称空间的名称视为在函数之外声明的,但它不会使得该文件中的其他函数能够使用这些名称。因此,在前一个例子中,foom( )函数不能使用未限定的标识符Hill。
如果有下面代码:
#include<iostream>
namespace Jill {
int fetch = 55;
}
int fetch;
int main() {
std::cout << fetch << " [" << &fetch << "]" << std::endl;
using namespace Jill;
int fetch;
std::cout << fetch << " [" << &fetch << "]" << std::endl;
std::cin >> fetch >> ::fetch;
std::cout << "local_fetch=" << fetch << " [" << &fetch << "]" << std::endl;
std::cout << "global_fetch=" << ::fetch << " [" << &(::fetch) << "]" << std::endl;
std::cout << Jill::fetch << " [" << &(Jill::fetch) << "]" << std::endl;
Jill::fetch = 66;
std::cout << Jill::fetch;
}
程序运行结果:

(注:全局变量默认初始化为0,局部变量不会,所以它的初始值是随机的)
注释main()内 int fetch;如下图,可以看到如下出错:
 “fetch不明确”,即fetch变量不知是main()外的还是Jill空间下的,起冲突。
“fetch不明确”,即fetch变量不知是main()外的还是Jill空间下的,起冲突。
注释main()外 int fetch;如下图,可以看到如下出错:
 “全局范围没有‘fetch’”,即找不到全局的fetch变量。
“全局范围没有‘fetch’”,即找不到全局的fetch变量。
下图是更直观的表示代码中变量的地址(相同地址方框颜色相同):

运行结果和上图说明:黄框是在对Jill::fetch访问。绿框是全局变量,main()第一行使用的就是它。随后虽然使用了局部命名空间,但被局部粉框定义的同名变量隐藏了全局及命名空间的fetch变量。可以随时用作用域“::”符访问全局变量。
假设名称空间和声明区域定义了相同的名称。如果试图使用using声明将名称空间的名称导入该声明区域,则这两个名称会发生冲突,从而出错。如果使用using编译指令将该名称空间的名称导入该声明区域,则局部版本将隐藏名称空间版本。
一般说来,使用using声明比使用using编译指令更安全,这是由于它只导入指定的名称。如果该名称与局部名称发生冲突,编译器将发出指示。using编译指令导入所有名称,包括可能并不需要的名称。如果与局部名称发生冲突,则局部名称将覆盖名称空间版本,而编译器并不会发出警告。另外,名称空间的开放性意味着名称空间的名称可能分散在多个地方,这使得难以准确知道添加了哪些名称。
下面是本书的大部分示例采用的方法:
#include<iostream>
int main() {
using namespace std;
首先,#include语句将头文件iostream放到名称空间std中。然后,using编译指令是该名称空间在main( )函数中可用。有些示例采取下述方式:
#include<iostream>
using namespace std;
int main() {
这将名称空间std中的所有内容导出到全局名称空间中。使用这种方法的主要原因是方便。它易于完成,同时如果系统不支持名称空间,可以将前两行替换为:
#include<iostream.h>
然而,名称空间的支持者希望有更多的选择,既可以使用解析运算符,也可以使用using声明。也就是说,不要这样做(using编译指令):
using namespace std; // 避免不分皂白的这样做
而应该这样做:
int x;
std::cin >> x;
std::cout << x << std::endl;
或者这样做:(using声明)
using std::cin;
using std::cout;
using std::endl;
int x;
cin >> x;
cout << x << endl;
还可以用嵌套式名称空间来创建一个包含常用using声明的名称空间。
③名称空间的其他特性:
Ⓐ可以将名称空间声明进行嵌套:
namespace elements {
namespace fire {
int flame;
...
}
float water;
}
这里,flame指的是element::fire::flame。同样,可以使用下面的using编译指令使内部的名称可用:
using namespace elements::fire;
Ⓑ另外,也可以在名称空间中使用using编译指令和using声明,如下所示:
namespace myth {
using Jill::fetch;
using namespace elements;
using std::cout;
using std::cin;
}
假设要访问Jill::fetch。由于Jill::fetch现在位于名称空间myth(在这里,它被叫做fetch)中,因此可以这样访问它:
std::cin >> myth::fetch;
当然,由于它也位于Jill名称空间中,因此仍然可以称作Jill::fetch:
Jill::fetch;
std:cout << Jill::fetch; // 显示读入到myth::fetch中的值
如果没有与之冲突的局部变量,则也可以这样做:
using namespace myth;
cin >> fetch; // 真正的std::cin和Jill::fetch
现在考虑将using编译指令用于myth名称空间的情况。using编译指令是可传递的。如果A op B且B op C,则A op C,则说操作op是可传递的。例如,>运算符是可传递的(也就是说,如果A>B且B>C,则A>C)。在这个情况下,下面的语句将导入名称空间myth和elements:
using namespace myth;
以上编译指令与下面两条编译指令等价<=>:
using namespace myth;
using namespace elements;
下面是个示例:
#include <iostream>
#include <string>
namespace nspA {
struct stA {
std::string name;
int age;
};
};
namespace nspB {
struct stB {
nspA::stA sta;
float weight;
};
};
int main() {
using nspB::stB;
stB stb;
stb.sta = { "akuan", 32 };
stb.weight = 65.9F;
// 此行可替换上面:stB stb = { { "akuan", 32 }, 65.9F };
std::cout << stb.sta.name << " " << stb.sta.age << " " << stb.weight;
return 0;
}
Ⓒ可以给名称空间创建别名。例如,假设有下面的名称空间:
namespace my_very_favorite_things {...};
则可以使用下面的语句让mvft成为my_very_favorite_things的别名:
namespace mvft = my_very_favorite_things;
可以使用这种技术来简化对嵌套名称空间的使用:
namespace MEF = myth::elements::fire;
using MEF::flame;
④未命名的名称空间:
可以通过省略名称空间的名称来创建未命名的名称空间:
namespace { // 未命名的名称空间
int ice;
int bandycoot;
}
这就像后面跟着using编译指令一样,也就是说,在该名称空间中声明的名称的潜在作用域为:从声明点到该声明区域末尾。从这个方面看,它们与全局变量相似。然而,由于这种名称空间没有名称,因此不能显式地使用using编译指令或using声明来使它在其他位置都可用。具体地说,不能在未命名名称空间所属文件之外的其他文件中,使用该名称空间中的名称。这提供了链接性为内部的静态变量的替代品。例如,假设有这样的代码:
static int counts; // 静态存储,内部链接
int other();
int main() {
...
}
int other() {
...
}
采用名称空间的方法如下:
namespace {
int counts; // 静态存储,内部链接
}
int other();
int main() {
...
}
int other() {
...
}
现在来看一个多文件示例,该示例说明了名称空间的一些特性。
// namesp.h -- create the pers and debts namespaces
#include <string>
namespace pers {
struct Person {
std::string fname;
std::string lname;
};
void getPerson(Person&);
void showPerson(const Person&);
}
namespace debts {
using namespace pers;
struct Debt {
Person name;
double amount;
};
void getDebt(Debt&);
void showDebt(const Debt&);
double sumDebts(const Debt ar[], int n);
}
// namesp.cpp -- namespaces
#include <iostream>
#include "namesp.h"
namespace pers {
using std::cout;
using std::cin;
void getPerson(Person& rp) {
cout << "Enter first name: ";
cin >> rp.fname;
cout << "Enter last name: ";
cin >> rp.lname;
}
void showPerson(const Person& rp) {
std::cout << rp.lname << ", " << rp.fname;
}
}
namespace debts {
void getDebt(Debt& rd) {
getPerson(rd.name);
std::cout << "Enter debt: ";
std::cin >> rd.amount;
}
void showDebt(const Debt& rd) {
showPerson(rd.name);
std::cout << ": $" << rd.amount << std::endl;
}
double sumDebts(const Debt ar[], int n) {
double total = 0;
for (int i = 0; i < n; i++)
total += ar[i].amount;
return total;
}
}
// usenmsp.cpp -- using namespaces
#include <iostream>
#include "namesp.h"
void other(void);
void another(void);
int main(void) {
using debts::Debt;
using debts::showDebt;
Debt golf = { {"Benny", "Goatsniff"}, 120.0 };
showDebt(golf);
other();
another();
return 0;
}
void other(void) {
using std::cout;
using std::endl;
using namespace debts;
Person dg = { "Doodles", "Glister" };
showPerson(dg);
cout << endl;
Debt zippy[3];
int i;
for (i = 0; i < 3; i++)
getDebt(zippy[i]);
for (i = 0; i < 3; i++)
showDebt(zippy[i]);
cout << "Total debt: $" << sumDebts(zippy, 3) << endl;
}
void another(void) {
using pers::Person;;
Person collector = { "Milo", "Rightshift" };
pers::showPerson(collector);
std::cout << std::endl;
}
Goatsniff, Benny: $120
Glister, Doodles
Enter first name: |Arabella
Enter last name: |Binx
Enter debt: |100
Enter first name: |Cleve
Enter last name: |Delaproux
Enter debt: |120
Enter first name: |Eddie
Enter last name: |Fiotox
Enter debt: |200
Binx, Arabella: $100
Delaproux, Cleve: $120
Fiotox, Eddie: $200
Total debt: $420
Rightshift, Milo
来看下C++源码中的一个命名空间std:
"yvals_core.h" internal header (core):

<iostream> standard header:

❸名称空间及其前途:
随着程序员逐渐熟悉名称空间,将出现统一的编程理念。下面是当前的一些指导原则。
- 使用在已命名的名称空间中声明的变量,而不是使用外部全局变量。
- 使用在已命名的名称空间中声明的变量,而不是使用静态全局变量。
- 如果开发了一个函数库或类库,将其放在一个名称空间中。事实上,C++当前提倡将标准函数库放在名称空间std中,这种做法扩展到了来自C语言中的函数。例如,头文件math.h是与C语言兼容的,没有使用名称空间,但C++头文件cmath应将各种数学库函数放在名称空间std中。实际上,并非所有的编译器都完成了这种过渡。
- 仅将编译指令using作为一种将旧代码转换为使用名称空间的权宜之计。
- 不要在头文件中使用using编译指令。首先,这样做掩盖了要让哪些名称可用;另外,包含头文件的顺序可能影响程序的行为。如果非要使用编译指令using,应将其放在所有预处理器编译指令#include之后。
- 导入名称时,首选使用作用域解析运算符或using声明的方法。
- 对于using声明,首选将其作用域设置为局部而不是全局。
别忘了,使用名称空间的主旨是简化大型编程项目的管理工作。对于只有一个文件的简单程序,使用using编译指令并非什么大逆不道的事。
正如前面指出的,头文件名的变化反映了这些变化。老式头文件(如<iostream.h>)没有使用名称空间,但新头文件<iostream>使用了“std”名称空间。


















 200
200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











