




大数据仓库开发规范示例
一、前提概要
大数据平台开发规范示例 发布一段时间后,有小伙伴表示我汤姆就是个Sql Boy,可否来个 数据仓库开发规范示例?安排!
调侃归调侃,如果想做一名合格的Sql Boy,还真不容易…
一臻在此对过去和做数仓Ing的小伙伴们361°C鞠躬Respect以表敬意。

二、数仓分层原则及定义
2.1 数仓分层原则
数仓分层的目的是为了给业务提供高效的数据支撑,和层次清晰、功能明确的数据存储,为企业各角色提供稳定、准确、多元化的高可用数据,同时为数据提供更方便的管理和运维。
2.2 数仓分层定义
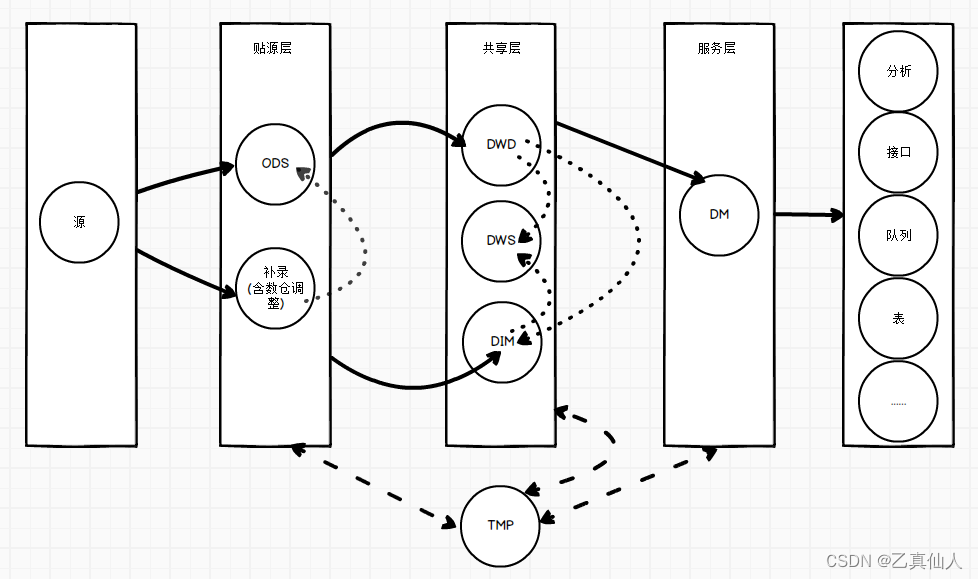
数仓主要包含ODS,DWD,DWS,DIM,DM几个标准化的分层,同时结合企业实际的情况,如补录的数据,在数据ETL过程中的临时处理数据等,根据用途汇总为贴源层、数据共享层、数据服务层。
- ODS(Operational Data Store): 贴源层数据,仅导入业务业务数据,不做任何数据的清洗转换和修改,保持与源库一致。具体情况根据项目场景设定。除了业务系统的数据,还包括补录数据处理,源系统数据快照处理等。
- DWD(Data Warehouse Detail): 数仓明细层数据,保留业务实体的原子粒度,并且通过数据清洗和一定程度的数据转换,保障数据质量。数据来源于ODS层,保留所有历史数据。业务实体、数据行、字段级的完整性,在该层实现。
- DWS(Data WareHouse Service): 数仓服务层,数仓的服务层,与之前所提到的数据服务层不同,DWS层为公共汇总层,指标均可在DWS层落地。该层使用DWD层数据,维度数据,对业务上有关联的实体做连接,形成统一粒度的,跨业务流程的,多业务实体的,轻度汇总数据。
- DIM(Dimension): 数据维度层,存储维度(含主数据)信息表或配置表,来源数据质量高的ODS数据(如主数据)和DWD层数据。
- DM(Data Market): 数据集市层,提供数据服务的分层,有明确的分析主题,基于具体的业务需求场景或者分析场景,数据仅包含维度和指标,没有复杂的逻辑处理。数据来源于DWD,DWS,DIM层,大多数为指标宽表,有较多的维度和指标。
- TMP:临时数据处理层,用于各层的数据加工处理过程中的临时数据处理,临时需求场景加工数据的处理。
三、数仓公共开发规范
3.1 分层调用规范
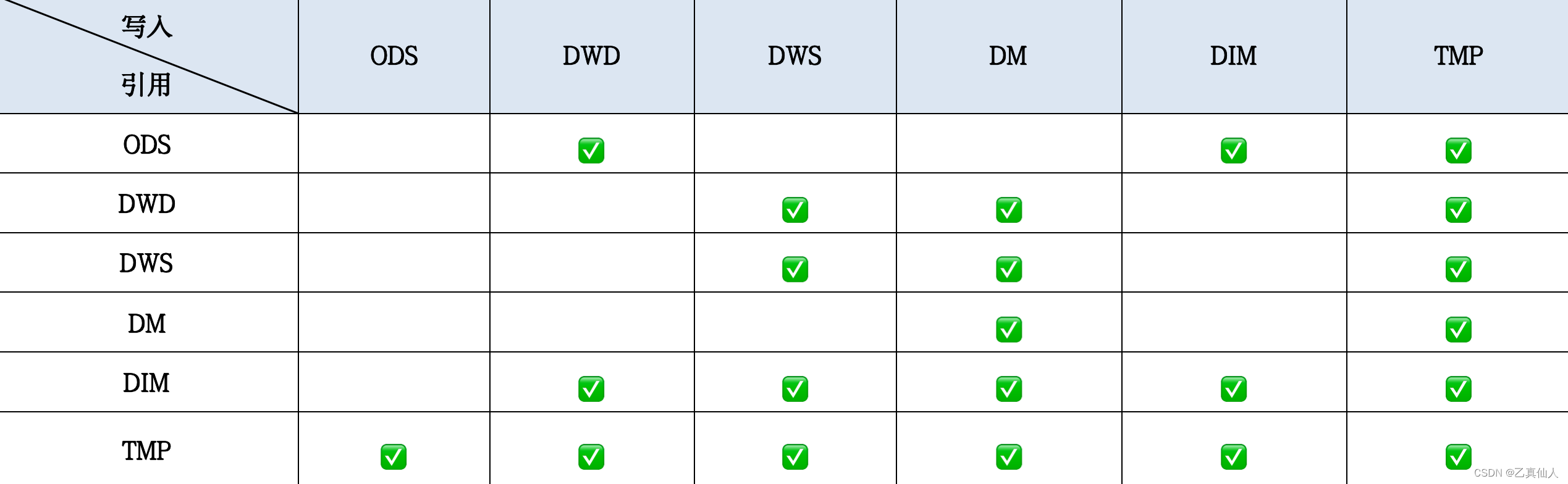
数据分层的标准流向(不含维度)为ODS->DWD->DWS->DM标准流向中,禁止出现反向依赖。
维度流向为DWD->DIM或者ODS->DIM,使用ODS直接到DIM的情况,必须保障足够高的数据质量。
DIM、DWS、DM可以往自身分层写入数据,如不同粒度的数据写入。
数据流向如下图所示:
3.2 数据类型规范
在保障数据不失真,且不会增加数据存储复杂度,不增加数据处理计算量的情况下,尽量减少数据类型的数量,兼容原始数据原有的类型。
数据类型依据具体的数据存储环境而定,比如使用Apache Doris的情况如下:
- ID类:BIGINT
- 标签枚举:INT
- 字符串:STRING
- 状态描述:STRING
- 日期:DATE yyyy-MM-dd
- 日期时间:DATETIME yyyy-MM-dd HH:mm:ss.SSSSSS
- 业务数额类默认使用 DECIMAL,精度根据实际情况做调整
3.3 数据冗余规范
宽表的冗余字段要确保以下原则:
- 冗余字段要使用高频,下游3个或以上使用。
- 冗余字段引入不应造成本身数据产生过多的延后。
- 冗余字段和已有字段的重复率不应过大,原则上不应超过 60%,如需要可以选择join或原表拓展。
3.4 NULL字段处理规范
- 数据类型为int的默认为-999
- 数据类型为bigint的默认为-999999
- 数据类型为decimal的默认为0
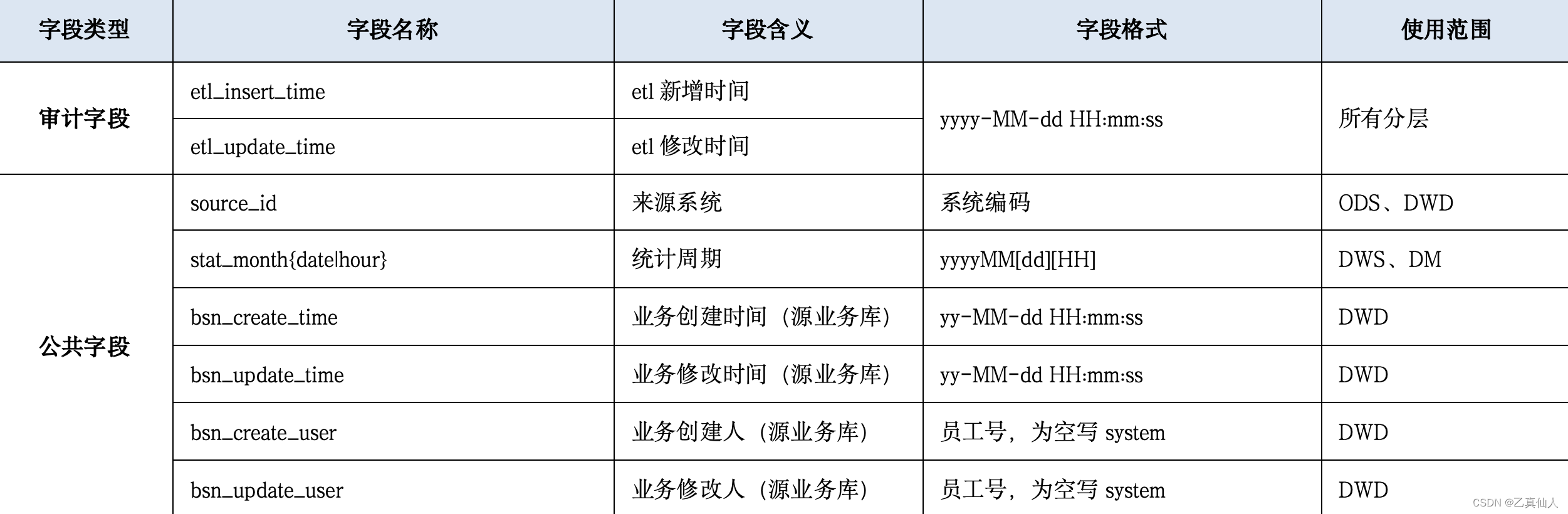
3.5 公共字段规范
所有数仓分层中的字段,均为小写,且不可出现中文。
物理表中的公共字段信息如下:
3.6 数据表处理规范
- 增量表:
依据具体的时间和其他标签粒度,做对应的分区或多层分区;处理过程中,源表必须包含可增量的属性字段,确保数据的完整性。 - 全量表:
每次写入的数据都是最新的;
每次写入的数据都是完整的全量数据。 - 拉链表:
记录一个事物从开始,一直到当前状态的所有变化的信息;
拉链表每次上报的都是历史记录的最终状态,是记录在当前时刻的历史总量;
当前记录存的是当前时间之前的所有历史记录的最后变化量(总量)。
3.7 事实表划分规范
在维度建模中,按粒度划分,数据表分为维度表和事实表,事实表包含三种:事务型事实表,周期快照型事实表,累计快照型事实表。
- 事务型事实表:
事务事实表记录事务层面的事实,保存最为原子的数据,其数据在事务发生后发生,粒度为每一行数据。 - 周期快照型事实表:
有规律的,可预见的时间间隔的业务累计数据,比如按天、周、月等做业务的统计度量。 - 累计快照型事实表:
在整个业务的生命周期中,表述业务多个阶段的开始和结束过程,通常有多个时间字段,并且时间不可预测,随着阶段周期的变化,记录也会随着变化而发生修改。
四、数仓各层开发规范
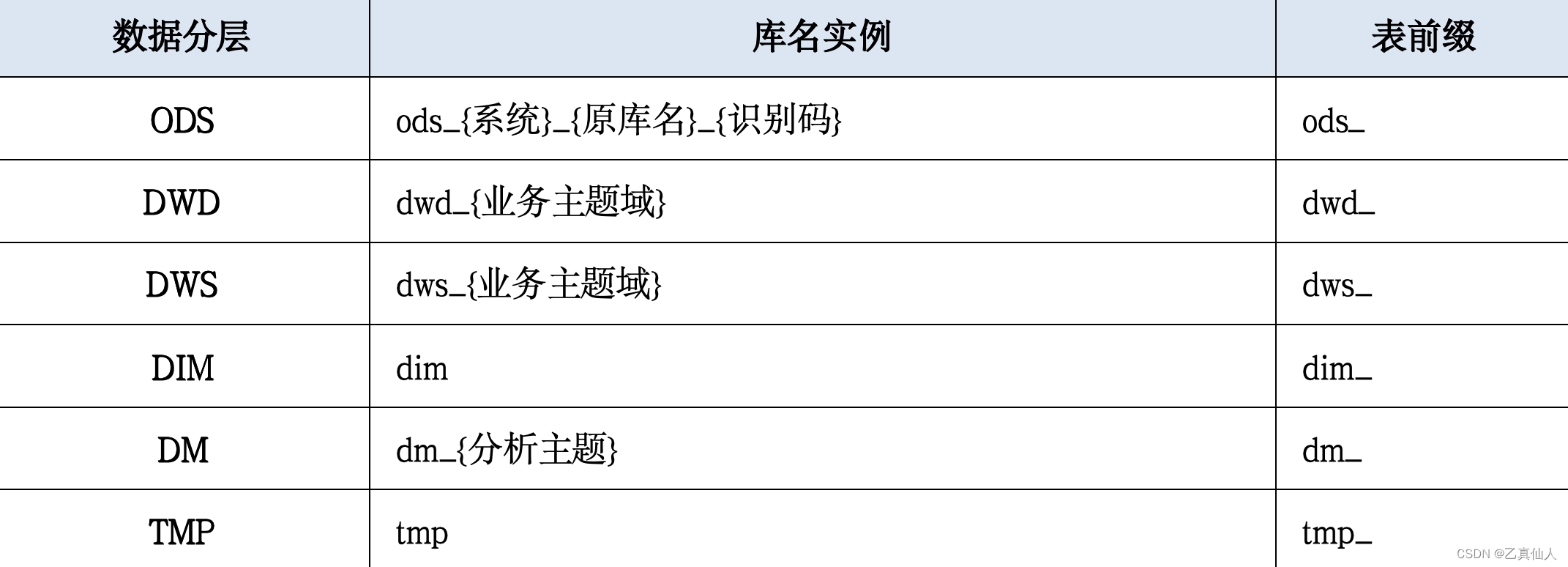
4.1 分层实例
数仓分册实例如下表所示:
4.2 表的属性词条相关规范
表的属性中会存在以下的属性词条,需要通过业务元数据去描述,不直接通过表名,避免表名太长的问题:
- 是否宽表
- 时效: 实时和非实时
- 更新方式:增量,全量
以下属性需要通过表名去区分:
- 统计周期:y表示年,m表示月,w表示周,d表示天,h表示小时,mi表示分钟
- 维度类型:缓慢变化维(scd),非缓慢变化维。
4.3 ODS层设计规范
- 命名规则
- ODS层表命名规则:ods_[类别]_[表内容]。
- 类别分为业务表(business简称bsn),快照表(snapshot简称snap)和补录表(amended简称amd)。
- 示例:ods_doris_load.ods_snap_stream_load,其中ods_doris_load是库名,doris是系统,load 是导入库,snap表示是快照表,stream_load是stream_load导入方式表名。
- 处理内容
- 源系统数据的采集和同步,保持和源系统数据的一致性。
处理过程分为实时和离线,实时接入的数据需要有对应的数据写入状态(新增、修改、删除),实时数据写入时间。 - 快照表处理:
对于源表数据量少于100万的,可按天/周/月不同的周期间隔,做全量快照表
对于源表数据量大于1000万的,需要根据业务主键做拉链表
对于源表数据量大于100万小于1000万的,根据具体业务的需求,做全量快照 - 补录表处理:主要针对业务系统中没有的数据,需要导入或者补录平台录入的,用以修复数据或者完善指标规则的,如财务手工账,订单时效的基线等。补录数据需要有以下约束:固定的模板,数据适用范围和有效期,补录数据的更新机制,补录数据更新后的数据处理机制,补录表需在表中增加字段(表述补录类别和用途)。
4.4 DWD层设计规范
- 命名规则
- DWD层表命名规则:dwd_[实体名]
- 示例:dwd_doris.dwd_doris_load,其中dwd_doris是库名,doris表示AP域,doris_load表示导入凭证
- 处理内容
- 数据的完整性,包括实体的完整性(分段的业务表),数据行的完整性(不同阶段的业务周期的汇集),字段的完整性(关键业务字段)。
- 数据清洗,对于脏数据按规则进行清洗,保障原子粒度的数据质量。
- 维度关联映射。
4.5 DWS层设计规范
- 命名规则
- DWS层表命名规则:dws_[主题内容]_[统计周期]
- 示例:dws_doris.dws_load_d,其中dws_doris是库名,load是导入全流程相关的主题内容,最后的d表示按天统计
- 处理内容
- 不同实体间的关联和逻辑转换。
- 维度退化。
- 不同粒度的指标度量表,以及轻度汇总。
- 不同类型的事实表。
- 粒度较细的宽表。
4.6 DIM设计规范
- 命名规则
- DIM表命名规则:dim_[主题域][维度类型][维度],维度统一库名,对于有主题域来源,通过表名识别主题域。
- 示例:dim.dim_doris_scd_load,其中dim表示维度的库名,doris 表示AP域,scd 表示缓慢变化维,load表示导入维度
- 处理内容
- 维度的一致性和准确性。
- 数据行中,为空维度的兼容。
- 缓慢变化维。
4.7 DM层设计规范
- 命名规则
- DM层表命名规则:dm_[项目/分析域][主题内容][统计周期]。
- 示例:dm_doris.dm_doris_load_d,其中dm_doris是库名,doris是表示AP项目,load 表示导入相关的分析,最后的d表示按天统计
- 处理内容
- 基于不同分析主题的宽表,基于应用场景的维度和指标的提取。
- 指标粒度的一致性。
- 数据的高度汇总。
- 保障维度完整性(所有的维度,包含为空的兼容都可在维表中关联)。
4.8 TMP层设计规范
- 命名规则
- TMP层表命名规则:
ETL作业:tmp_[分层库名_分层表名][流水]
临时使用的表:tmp[用户][表内容][有效期]
- 处理内容
- ETL作业中的临时表,可在ETL中临时创建和删除,必须满足模型管理员清理TMP层数据策略的要求。
- 临时使用的表,必须有确定的生命周期,不确定有效期的,可设置较长的有效期,模型管理- 员根据有效期和用户,不定时沟通确认该临时表的清理计划。
五、总结

规范示例仅作为参考,实际开发中需要根据业务要求和场景进行调整适配。



















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











