




 本文介绍如何通过减少不必要的表关联和增加Where条件来优化SQL查询效率,包括使用临时表处理大数据量子查询的方法。
本文介绍如何通过减少不必要的表关联和增加Where条件来优化SQL查询效率,包括使用临时表处理大数据量子查询的方法。
减少不必要的表关联
有时候一个查询需要很多表关联,表一多了就容易让人犯晕,没必要join的也都给塞进来了,看看下面这个句子:
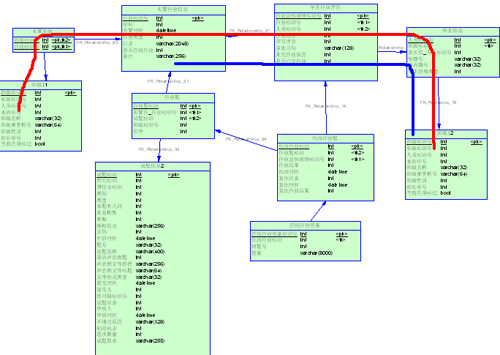
老师在布置作业的时候,会写入【布置班级】表和【学生作业评价】表,现在要检索每个班、每个学生在一段时间内做过的作业。我们的同事开始的join是走了红色的那条线,后来经过分析,显然蓝线就够了。
尽可能的限制条件
Where条件多了好啊,多了建索引的可能,也减少了结果集,尤其对于那种以查询结果做derived表的,更应该从中间就限制结果集。比如这个查询
2
3 t.person_id,
4
5 t.name,
6
7 t.class_id,
8
9 t.class_name,
10
11 t.grade_num,
12
13 t.cn,
14
15 t1.goodnum,
16
17 t2.infonum
18
19 from
20
21 (
22
23 select
24
25 bp.person_id,
26
27 bp.name,
28
29 bc.class_id,
30
31 bc.class_name,
32
33 bg.grade_num,
34
35 COUNT(distinct v.person_id) cn
36
37 from vir_extra_appraisal v,bas_person bp,bas_student b,bas_class bc,bas_grade bg
38
39 where v.bas_person_id= bp.person_id
40
41 and v.person_id= b.person_id
42
43 and b.class_id= bc.class_id
44
45 and bc.grade_id = bg.grade_id
46
47 and v.bas_person_id =12762
48
49 and v.appraisal_date >='2008-08-02 00:00:00'
50
51 and v.appraisal_date <='2008-09-03 23:59:59'
52
53 group by v.bas_person_id
54
55 )
56
57 t
58
59 left join
60
61 (
62
63 select
64
65 v1.bas_person_id,count(distinct v1.person_id)as goodnum
66
67 from vir_extra_appraisal v1
68
69 where v1.appraisal_type=8501001
70
71 and v1.appraisal_date >='2008-08-02 00:00:00'
72
73 and v1.appraisal_date <='2008-09-03 23:59:59'
74
75 group by v1.bas_person_id
76
77 )
78
79 t1 on (t1.bas_person_id= t.person_id )
80
81 left join
82
83 (
84
85 select
86
87 v2.bas_person_id,count(distinct v2.person_id)as infonum
88
89 from vir_extra_appraisal v2
90
91 where v2.appraisal_type=8501002
92
93 and v2.appraisal_date >='2008-08-02 00:00:00'
94
95 and v2.appraisal_date <='2008-09-03 23:59:59'
96
97 group by v2.bas_person_id
98
99 )
100
101 t2 on (t2.bas_person_id=t.person_id )
可以看到,derived表t是限制了v.bas_person_id =12762,最终的结果集是只查一个人的情况,derived表t、t1是针对所有人做的汇总,而在和derived表t 做join的时候,给过滤掉了,最终只保留了v.bas_person_id =12762的记录,这是何苦呢?直接在t1 和 t2里过滤掉多好,于是在t1 和t2里分别加上条件person_id=12762。
过大的子查询用临时表处理效果会好的多
-- /*以学生做题本为基础,加载某一天各班级的做题信息*/
2
3 select bs.problem_id,bs.class_id,bs.subject_id,bs.do_type,
4
5 sum(case bs.if_error when 1 then 0 else 1 end ) error_cnt,
6
7 count(* ) do_cnt,
8
9 date_format(bs.do_date,'%Y-%m-%d')
10
11 from bas_student_do_list bs
12
13 group by bs.problem_id,bs.class_id,bs.subject_id,bs.do_type,date_format(bs.do_date,'%Y-%m-%d');
14
15 create index idx_tmp on tmp_bas_class_do_list(class_id, problem_id);
16
17 update tmp_bas_class_do_list bs,
18
19 (select t3.problem_id,t3.do_type, t3.class_id,date_format(t3.do_date,'%Y-%m-%d') as do_date,group_concat(t1.name) as std_name
20
21 from bas_person t1, bas_student_do_list t3
22
23 where t1.person_id = t3.person_id
24
25 and t3.if_error = 0
26
27 group by t3.problem_id,t3.do_type, t3.class_id,date_format(t3.do_date,'%Y-%m-%d')) t2
28
29 set bs.error_students = t2.std_name
30
31 where bs.problem_id = t2.problem_id
32
33 and bs.class_id = t2.class_id
34
35 and count_date = t2.do_date
36
37 and bs.do_type = t2.do_type;
-- 临时表扶正
truncate table bas_class_do_list;
drop table bas_class_do_list;
rename table tmp_bas_class_do_list to bas_class_do_list;
大家可以看到,我是先把select的结果insert到临时表里,建立索引后,又用derived表t2更新临时表的数据,最后临时表替换成正式表。最初的时候,我是直接用select表和derived表t2做关联,直接insert到正式表里,这样写的select和t2做join的速度非常慢。改成这种写法后,速度由8分钟减少到40秒。
通过这个例子我们也可以看到,大批量插入前先删除索引,插入后再建立索引,效果要比直接插入好的多。

















&spm=1001.2101.3001.5002&articleId=81723872&d=1&t=3&u=83955abe4e1f4ae09d8d2432cb76a6c9)

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









