







 本文介绍了协同过滤(Collaborative Filtering, CF)的基本原理及应用。协同过滤是一种利用集体智慧进行个性化推荐的方法,通过分析用户行为数据找出品味相似的用户或物品,并据此提供推荐。文章详细阐述了收集用户偏好、相似度计算、推荐算法等关键步骤。
本文介绍了协同过滤(Collaborative Filtering, CF)的基本原理及应用。协同过滤是一种利用集体智慧进行个性化推荐的方法,通过分析用户行为数据找出品味相似的用户或物品,并据此提供推荐。文章详细阐述了收集用户偏好、相似度计算、推荐算法等关键步骤。
1.协同过滤
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐, 而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。当然其中有一个核心的问题:
- 如何确定一个用户是不是和你有相似的品位?
- 如何将邻居们的喜好组织成一个排序的目录?
2.协同过滤的核心
首先,要实现协同过滤,需要一下几个步骤:
- 收集用户偏好
- 找到相似的用户或物品
- 计算推荐
(1)收集用户偏好
分为显式与隐式两种,显式:用户填写评分,投票,转发等等,通过用户显式的行为获取到的数据。隐式:用户浏览网站,购买,关注等等。显示与隐式的区别在于用户时候直接评分。
(2)找到相似的用户与物品
当已经对用户行为进行分析得到用户喜好后,我们可以根据用户喜好计算相似用户和物品,然后基于相似用户或者物品进行推荐,这就是最典型的 CF 的两个分支:基于用户的 CF 和基于物品的 CF。这两种方法都需要计算相似度。
1)相似度计算
关于相似度的计算,现有的几种基本方法都是基于向量(Vector)的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐的场景中,在用户 - 物品偏好的二维矩阵中,我们可以将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对某个物品的偏好作为一个向量来计算物品 之间的相似度。通常有以下几种最基本的计算方法:
- 欧几里得距离(Euclidean Distance):
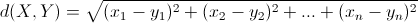
其意义就是两个元素在欧氏空间中的集合距离,因为其直观易懂且可解释性强,被广泛用于标识两个标量元素的相异度。例如,计算X={2,1,102}和Y={1,3,2}的相似度(相异度)。将上面两个示例数据代入公式,可得两者的欧氏距离为:
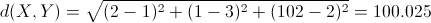
- 曼哈顿距离:
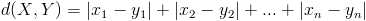
- 闵可夫斯基距离:
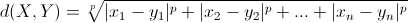
欧氏距离和曼哈顿距离可以看做是闵可夫斯基距离在p=2和p=1下的特例。另外这三种距离都可以加权,这个很容易理解,不再赘述。
下面要说一下标量的规格化问题。上面这样计算相异度的方式有一点问题,就是取值范围大的属性对距离的影响高于取值范围小的属性。 例如上述例子中第三个属性的取值跨度远大于前两个,这样不利于真实反映真实的相异度,为了解决这个问题,一般要对属性值进行规格化。所谓规格化就是将各个 属性值按比例映射到相同的取值区间,这样是为了平衡各个属性对距离的影响。通常将各个属性均映射到[0,1]区间,映射公式为: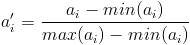
其中max(ai)和min(ai)表示所有元素项中第i个属性的最大值和最小值。例如,将示例中的元素规格化到[0,1]区间后,就变成了X’={1,0,1},Y’={0,1,0},重新计算欧氏距离约为1.732。
- 皮尔逊相关系数(Pearson Correlation Coefficient)
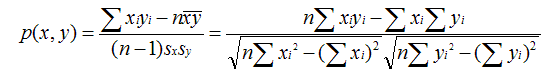
2)相似邻居计算
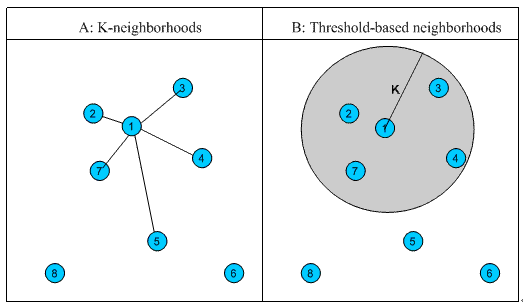
- 固定数量的邻居:K-neighborhoods 或者 Fix-size neighborhoods
- 基于相似度门槛的邻居:Threshold-based neighborhoods
与计算固定数量的邻居的原则不同,基于相似度门槛的邻居计算是对邻居的远近进行最大值的限制,落在以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,这种方法计算得到的邻居个数不确定,但相似度不会出现较大的误差。如图 1 中的 B,从点 1 出发,计算相似度在 K 内的邻居,得到点 2,点 3,点 4 和点 7,这种方法计算出的邻居的相似度程度比前一种优,尤其是对孤立点的处理。
(3)计算推荐
基于协同过滤的推荐算法可以分为基于用户的 CF 和基于物品的 CF
- 基于用户的 CF
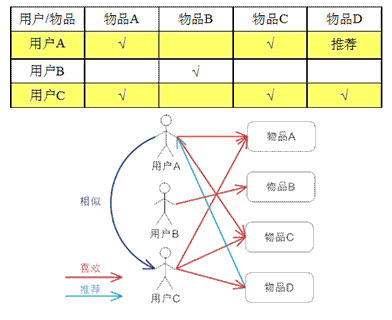
- 基于物品的 CF
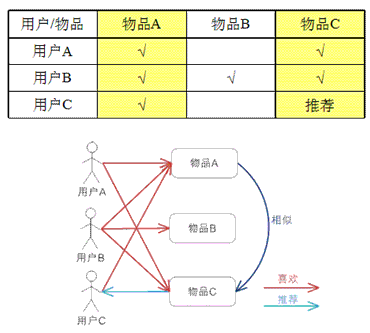
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算 的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的 物品,计算得到一个排序的物品列表作为推荐。图 3 给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
(4)应用场合
- User CF
- Item CF
非社交网络的网站中,内容内在的联系是很重要的推荐,此时使用Item CF能有更好的效果

















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









