






 本文深入探讨maxMF模型,一种改进的矩阵分解推荐算法。maxMF认为用户兴趣多元,不应仅由单一向量表示,而是通过多个向量捕捉不同兴趣点。文章详细解释了模型原理,包括如何计算用户与商品的相关分数,以及如何通过优化参数实现个性化推荐。
本文深入探讨maxMF模型,一种改进的矩阵分解推荐算法。maxMF认为用户兴趣多元,不应仅由单一向量表示,而是通过多个向量捕捉不同兴趣点。文章详细解释了模型原理,包括如何计算用户与商品的相关分数,以及如何通过优化参数实现个性化推荐。
1:经典的推荐会采用矩阵分解方式来学习用户、商品的潜在向量,并用用户与商品向量的相似度来召回商品。
2:什么是maxMF?
这里的maxMF区别去ALS是,它不像ALS只会有一个向量,他的前提假设是一个用户更加复杂,我们不能靠一个单纯的向量去表示用户,我们需要多个向量去表示用户,然后用一个向量去表示商品。这样我们用户与商品匹配得分就是取用户多个向量里那个最大得分作为匹配得分。而且这个模型是一个非线性的。
这里我们会想,既然用多个兴趣向量表示用户,为哈不直接来一个更大的向量去表示用户,这样表示的信息不就丰富了吗?其实这样想法也不是不对,而是实际中应用可能比较困难,主要困难点:
1:维度太大,占用内存就过多。
2:维度太大,训练难度加大,时间更久
3:维度太大,可能会过拟合,泛化能力不好
3:算法介绍
1:标准的线性的用户商品分解公式如下:
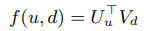
其中u是所有给定的用户,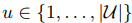 ,其中d是要被推荐的商品
,其中d是要被推荐的商品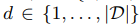 ,用户与商品匹配的分数计算如下:
,用户与商品匹配的分数计算如下: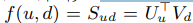 这个公式就是矩阵分解,比如S就是用户对商品d的打分,用户不可能每个商品都打分,我们需要通过矩阵U(这个矩阵就是用户与用户的隐藏m维特征组成的)与矩阵V(这个矩阵就是商品与商品的隐藏m维特征组成的)的想乘来预测S中没有打分的那些缺失项。
这个公式就是矩阵分解,比如S就是用户对商品d的打分,用户不可能每个商品都打分,我们需要通过矩阵U(这个矩阵就是用户与用户的隐藏m维特征组成的)与矩阵V(这个矩阵就是商品与商品的隐藏m维特征组成的)的想乘来预测S中没有打分的那些缺失项。
那么我们的方法呢?就是将用户向量变成T个,而不是一个了。一个用户拥有T个向量。但是商品还是一个向量。我们用户矩阵用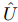 表示,这个的
表示,这个的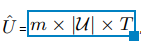 就是每个用户有m维,T个向量。其中用户具体的一个兴趣向量可以表示为:
就是每个用户有m维,T个向量。其中用户具体的一个兴趣向量可以表示为: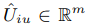 ,意思就是用户u的第i个兴趣向量是m维。
,意思就是用户u的第i个兴趣向量是m维。
2:基于我们提出用户拥有T个兴趣向量,那么用户与商品相关分数计算公式就变成:
这个公式可以看出,我们利用用户T个向量逐个与商品向量做点积,取得分最大的那个得分。
4:训练模型
这个模型优化核心思想还是引用了WSABIE算法,在我日记里有介绍。
1:通过最小化下面这个公式来获得最优参数:
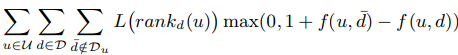
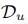 是正样本,就是用户有行为的点击,购买等行为的商品。我们这里的评分采用的是0 (无行为)1(有行为),而不是采用具体的数值。上面这个公式是要把这个函数最小化,比如d是正样本商品,
是正样本,就是用户有行为的点击,购买等行为的商品。我们这里的评分采用的是0 (无行为)1(有行为),而不是采用具体的数值。上面这个公式是要把这个函数最小化,比如d是正样本商品,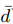 是负样本的商品,我们最小化上式就是期望正样本都排前面。其中 rankd(u)函数的具体公式如下:
是负样本的商品,我们最小化上式就是期望正样本都排前面。其中 rankd(u)函数的具体公式如下: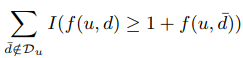 ,这个公式就是所有正确商品被排在前面的数量。这里也用到WSABIE算里的抽样进行优化
,这个公式就是所有正确商品被排在前面的数量。这里也用到WSABIE算里的抽样进行优化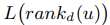 这个函数的,这个函数无非就是求排在正确样本前有多少个错误的样本,这里采用抽样,从N个商品里抽样,只到抽到
这个函数的,这个函数无非就是求排在正确样本前有多少个错误的样本,这里采用抽样,从N个商品里抽样,只到抽到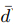 负样本商品。就停止了,换算成公式就是:在这里插入图片描述
负样本商品。就停止了,换算成公式就是:在这里插入图片描述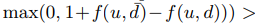
 比如
比如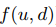 是1,如果
是1,如果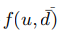 是0的话,上面式子都不能大于0,除非
是0的话,上面式子都不能大于0,除非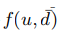 =1,就表示预测错了。这样情况下才会大于0.,这个时候我们就可以把这样情况下才会大于0.,这个时候我们就可以把
=1,就表示预测错了。这样情况下才会大于0.,这个时候我们就可以把这样情况下才会大于0.,这个时候我们就可以把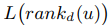 近似为
近似为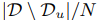 ,其中N是抽样次数,
,其中N是抽样次数,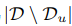 是所有负样本的集合大小。
是所有负样本的集合大小。
优化模型:
对于给定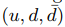 我们主要目标是让表示用户兴趣的向量满足:
我们主要目标是让表示用户兴趣的向量满足:
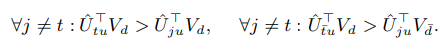 其中Vd是感兴趣商品
其中Vd是感兴趣商品 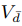 是不感兴趣商品。这里的意思是,用户T个向量里,与Vd最相关的向量点积永远大于其他几个向量与Vd的点积。用户向量中除了最相关的向量外,其他每个向量与相关商品的点积都大于他们与非相关商品的点积。梯度更新公式如下:
是不感兴趣商品。这里的意思是,用户T个向量里,与Vd最相关的向量点积永远大于其他几个向量与Vd的点积。用户向量中除了最相关的向量外,其他每个向量与相关商品的点积都大于他们与非相关商品的点积。梯度更新公式如下: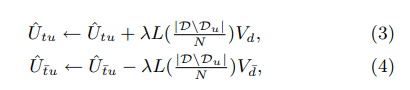
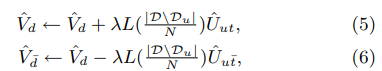 在做这个之前,我们也要增加正则约束,如下:
在做这个之前,我们也要增加正则约束,如下: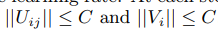 这里的函数采用的是
这里的函数采用的是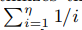 整个算法伪代码如下:
整个算法伪代码如下:
 5:并行运算
5:并行运算
并行计算,这里采用的是交替的优化方法,就是先固定一个参数V,训练U ,不过这里的方式我们分两个步骤走,首先训练V,但是这个时候U我们是不知道的。我们可以给U随机初始化。如果这样随机初始化,我们的V不太可能被训练的非常好,因为U是随机初始化的,除非我们迭代次数够多,知道U也收敛了,这样才能训练比较好的V,不过这里我们不采取这样的方式,我们把U做如下分解,也就是我们U采用V去表示,我们知道用户对商品有点击,加购等行为。那么用商品的embedding去表示用户。用户U可以近似表达成如下公式: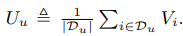 ,这个公式里,是采用用户有行为商品向量的一个平均加权。
,这个公式里,是采用用户有行为商品向量的一个平均加权。
这样我们计算用户相似度的公式就可以改写成这样的: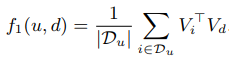 这个可以看成了都是利用商品向量去训练了。
这个可以看成了都是利用商品向量去训练了。
当我们V被训练到一定程度收敛后,我们就可以把V固定下来,比如把V赋予给V* ,然后我们再去训练用户U。公式如下: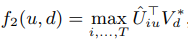 那么这里的并行概念是什么呢?
那么这里的并行概念是什么呢?
通过上面,我们把用户的每个参数解耦了,这样我们就可以单独去训练每个用户了。每个map阶段,我们用用户作为key,三元组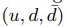 作为value,在reduce阶段,就可以单独训练每个用户,而不需要通过单台机器去访问整个模型。等训练好U,我们reduce就可以把U发出去,把整个模型保存在磁盘上,方便下次迭代。也可以方便下次我们基于U固定下来,再重新训练下V。具体算法步骤如下:
作为value,在reduce阶段,就可以单独训练每个用户,而不需要通过单台机器去访问整个模型。等训练好U,我们reduce就可以把U发出去,把整个模型保存在磁盘上,方便下次迭代。也可以方便下次我们基于U固定下来,再重新训练下V。具体算法步骤如下:
算法:
第一步,先训练出V,不过训练过程需要基于算法1里面的方法。
第二步:固定V,然后训练U,下面for训练里是并行处理的,每次迭代,只更新3-4公式,也就是用户U的参数,不更新V的参数。
李春生:负责搜索推荐,工程与算法,对搜索推荐有兴趣的,大家一起交流,相互学习!

















 3667
3667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









