




转载自: https://www.bilibili.com/video/BV1CWV6zKEBn/?spm_id_from=333.337.search-card.all.click&vd_source=23c41e5d4f31a4e78f60af9ecdd3fcb7
路线

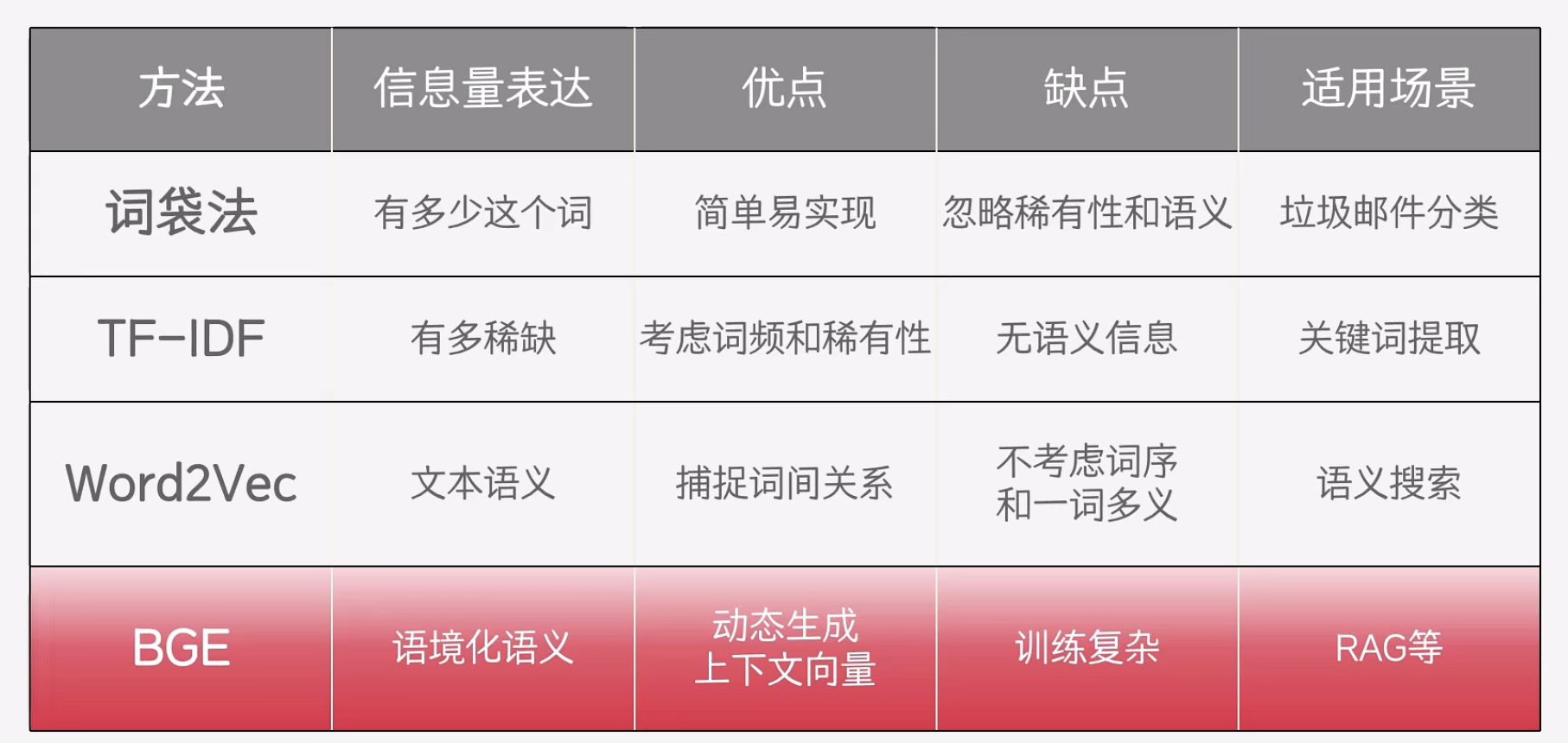
词袋法
- 对于存在的值用
1表示 - 对于不存在的值用
0表示
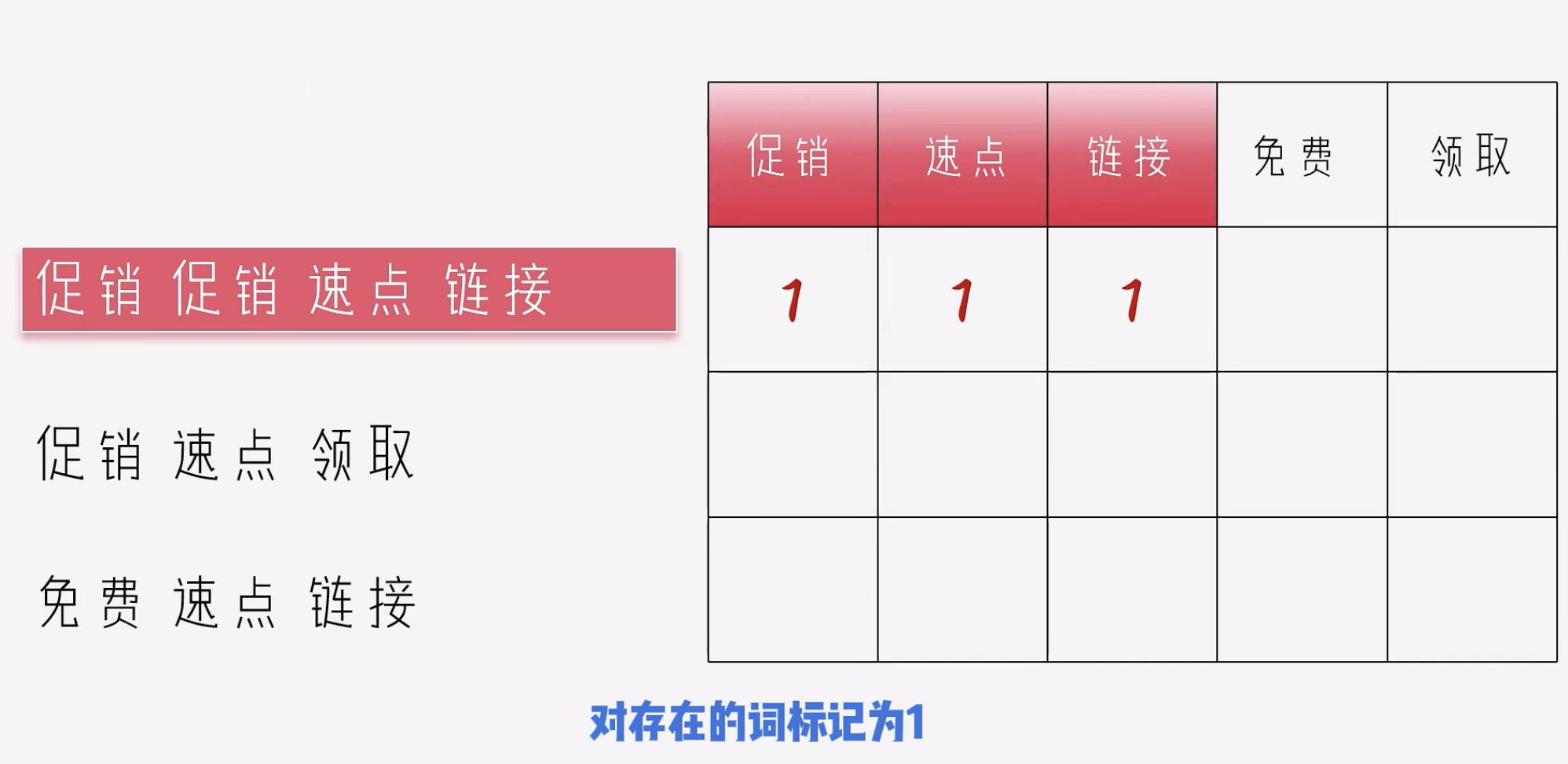
词袋表示的结果:

词袋法种类
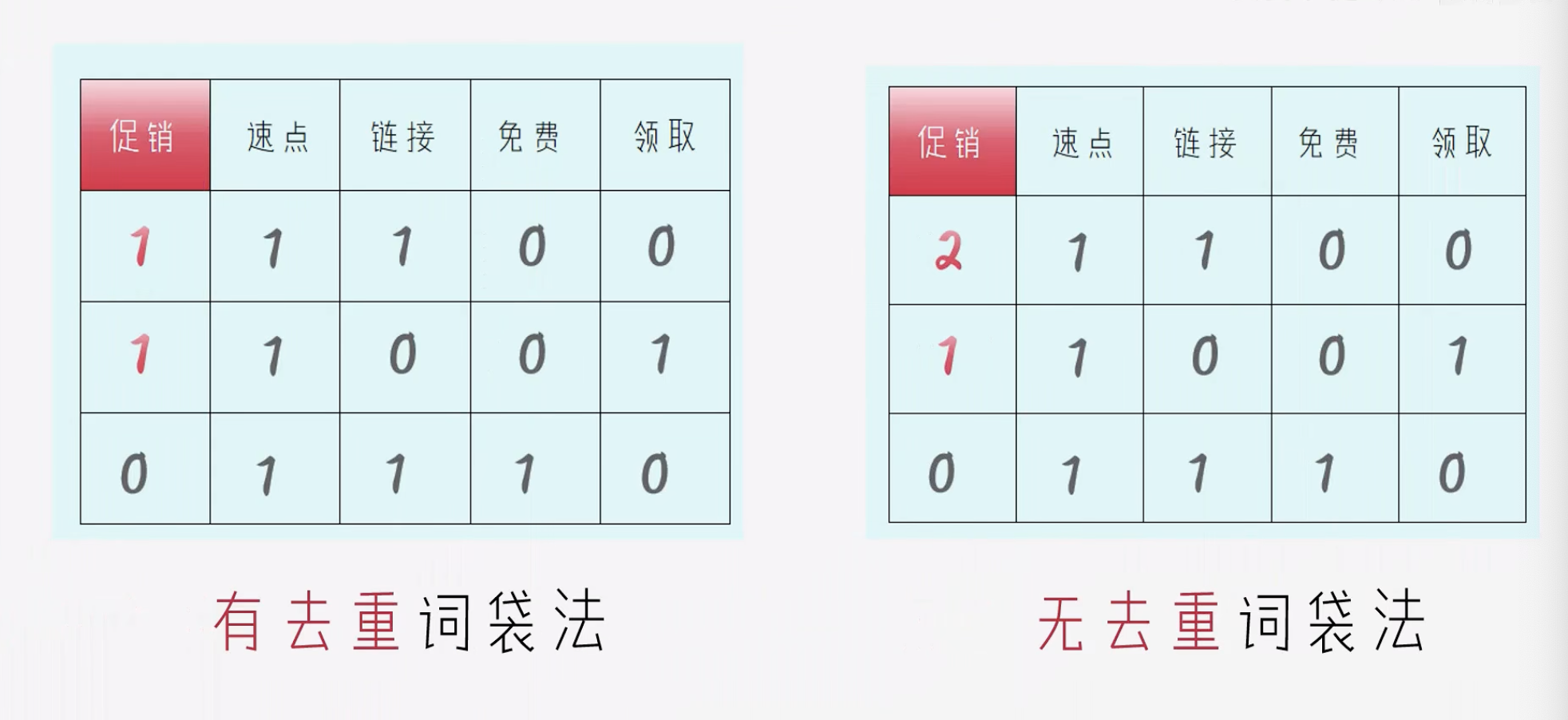
- 有去重词袋法: 表示有没有 特定的词
- 可以用于 垃圾邮件筛选
- 无去重词袋法: 表示有多少 特定的词
TF-IDF
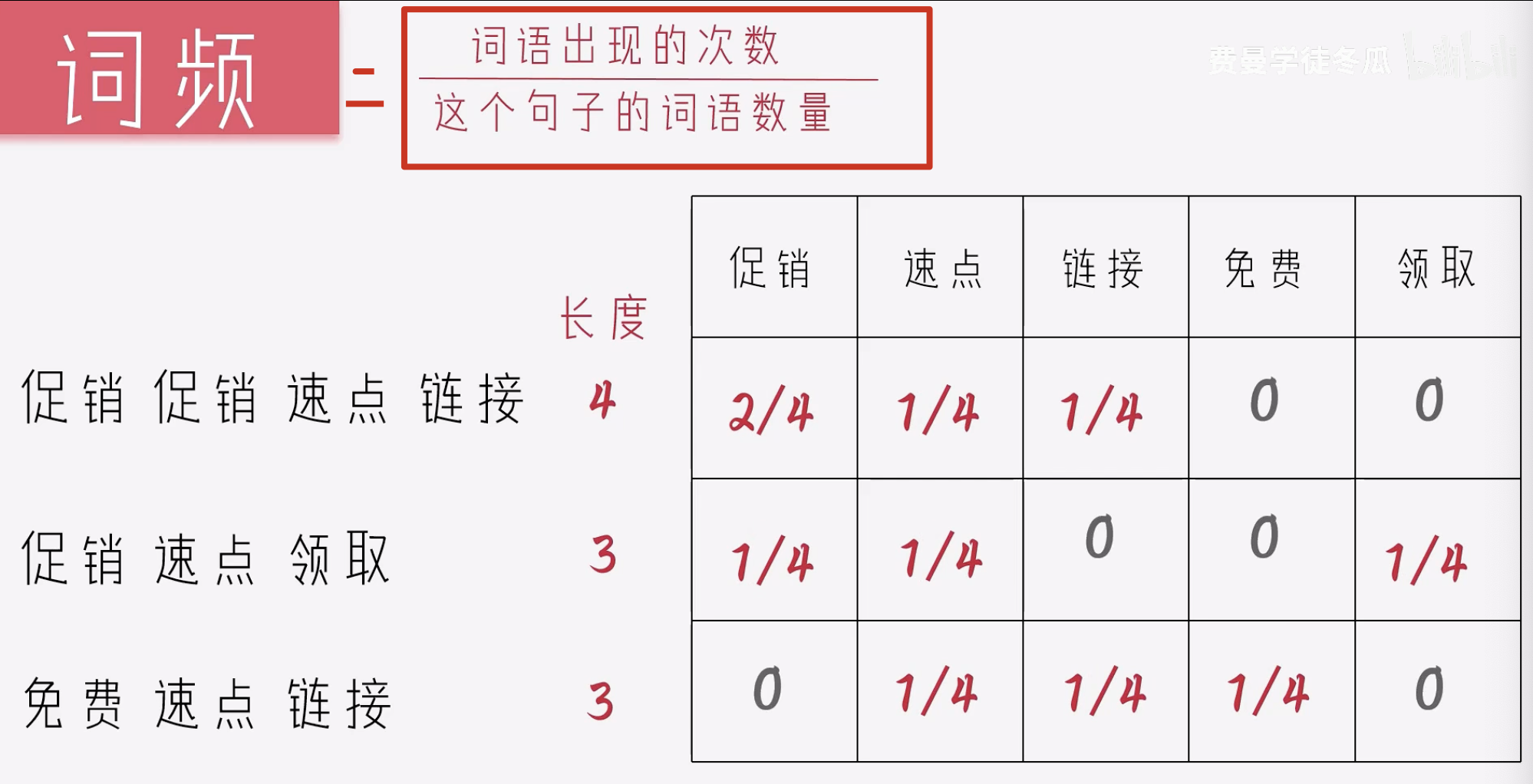
词频 & 关键词

上图中的出现的频率最高,但是它是一个常见词,不能作为关键词。
关键词: 应该是特别的,稀有的。
词频
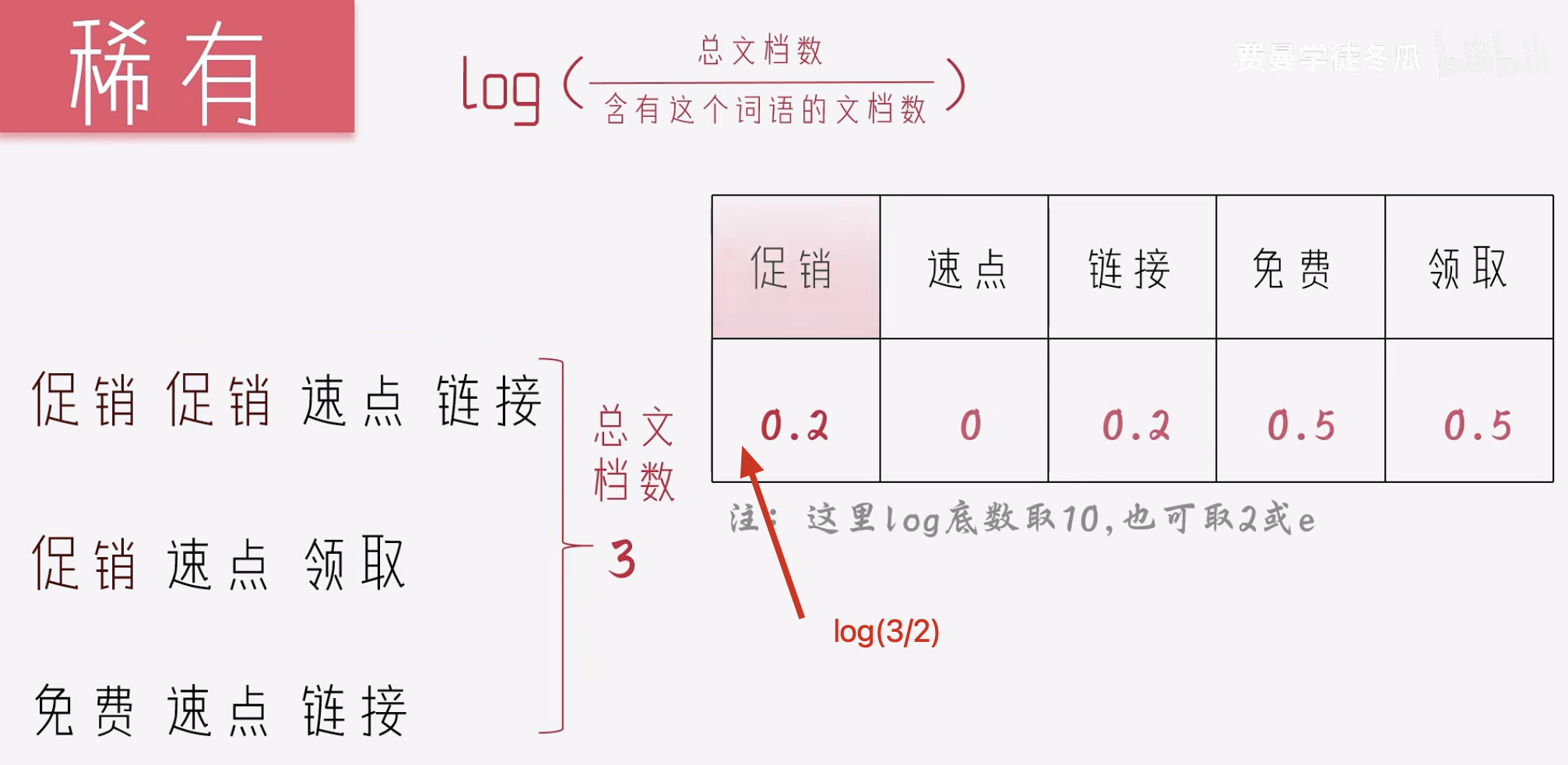
稀有
总文档数/含有这个词语的文档数
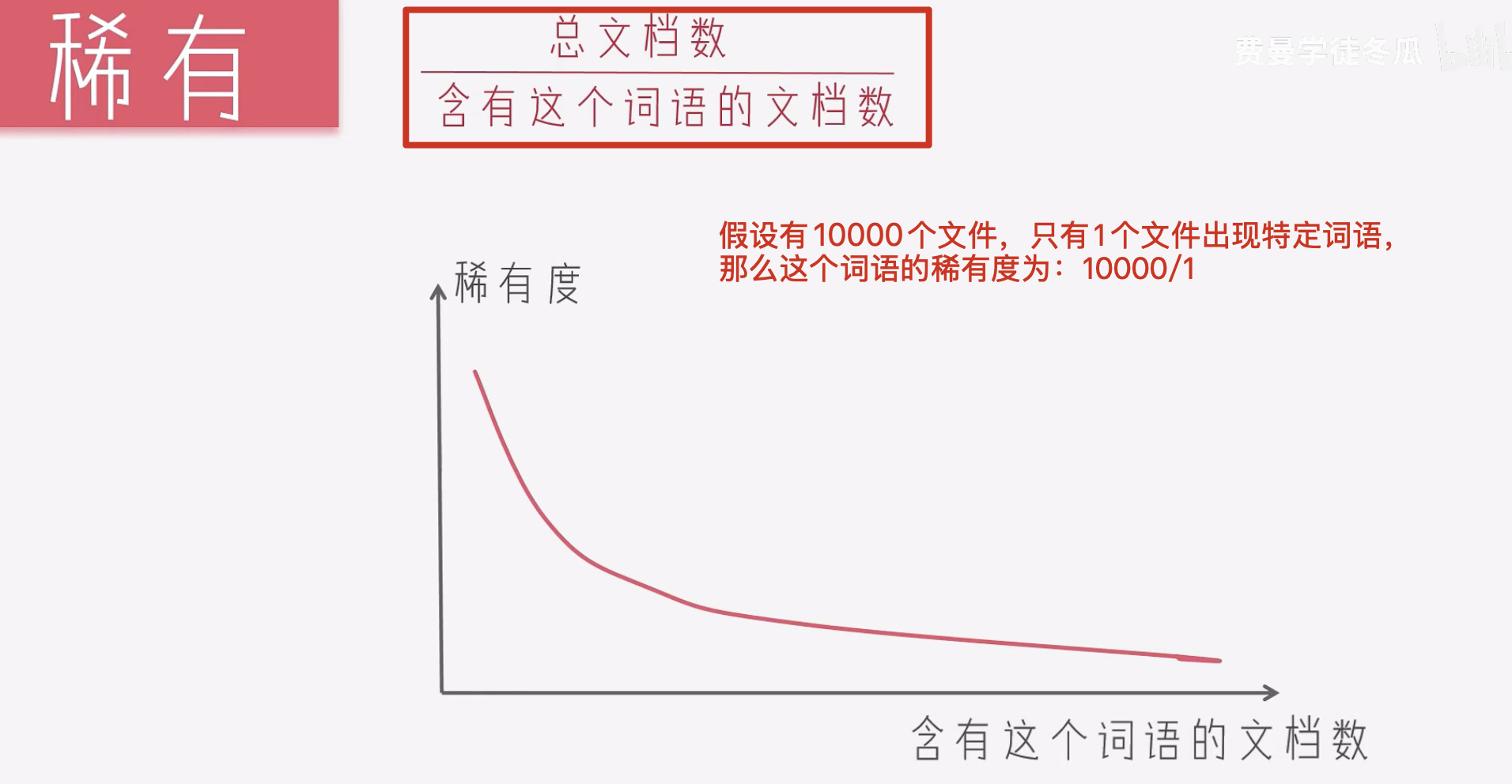
log(总文档数/含有这个词语的文档数)
为了让稀有度更加平缓,常见的做法是用log.
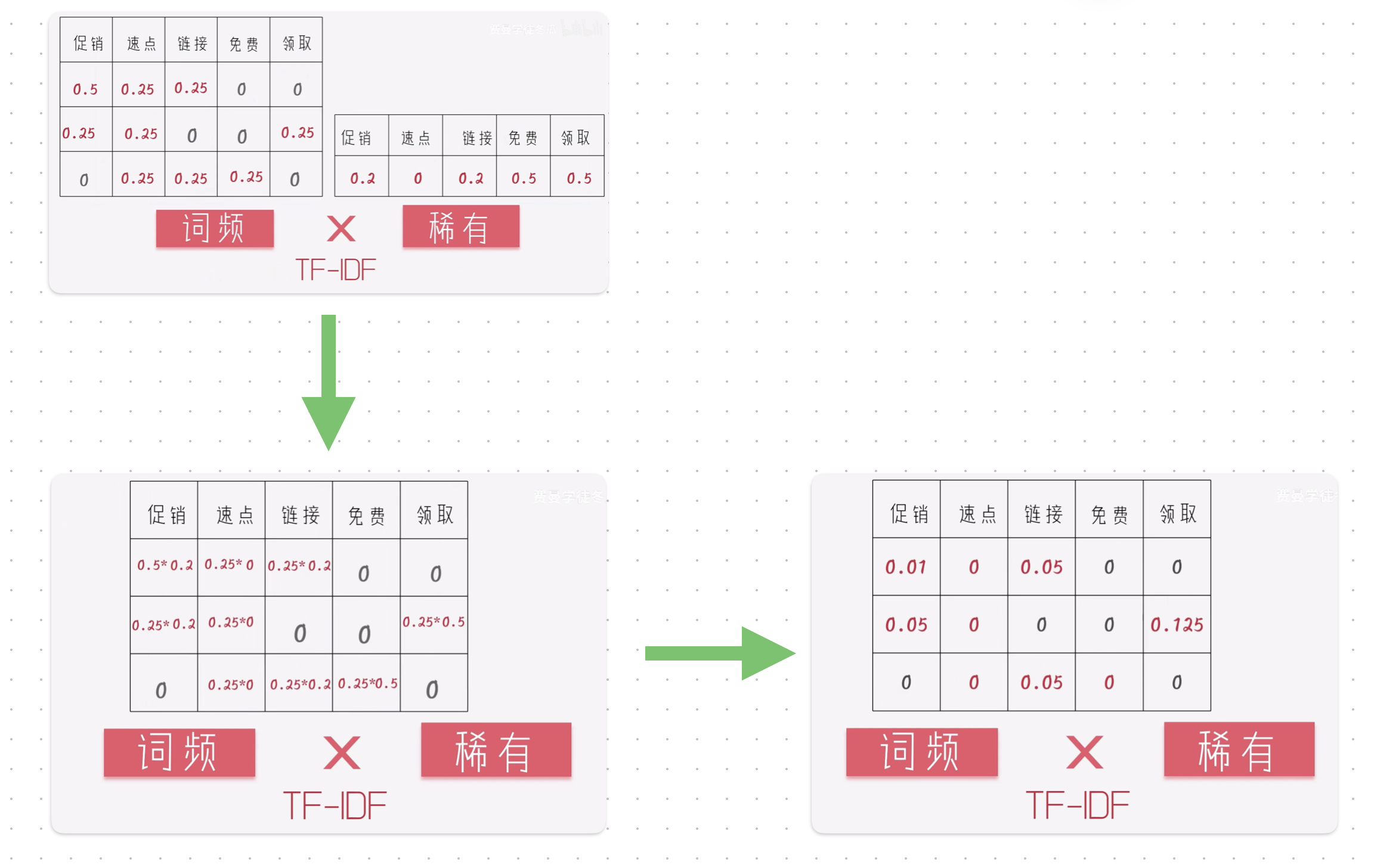
TF-IDF(词频*稀有性)
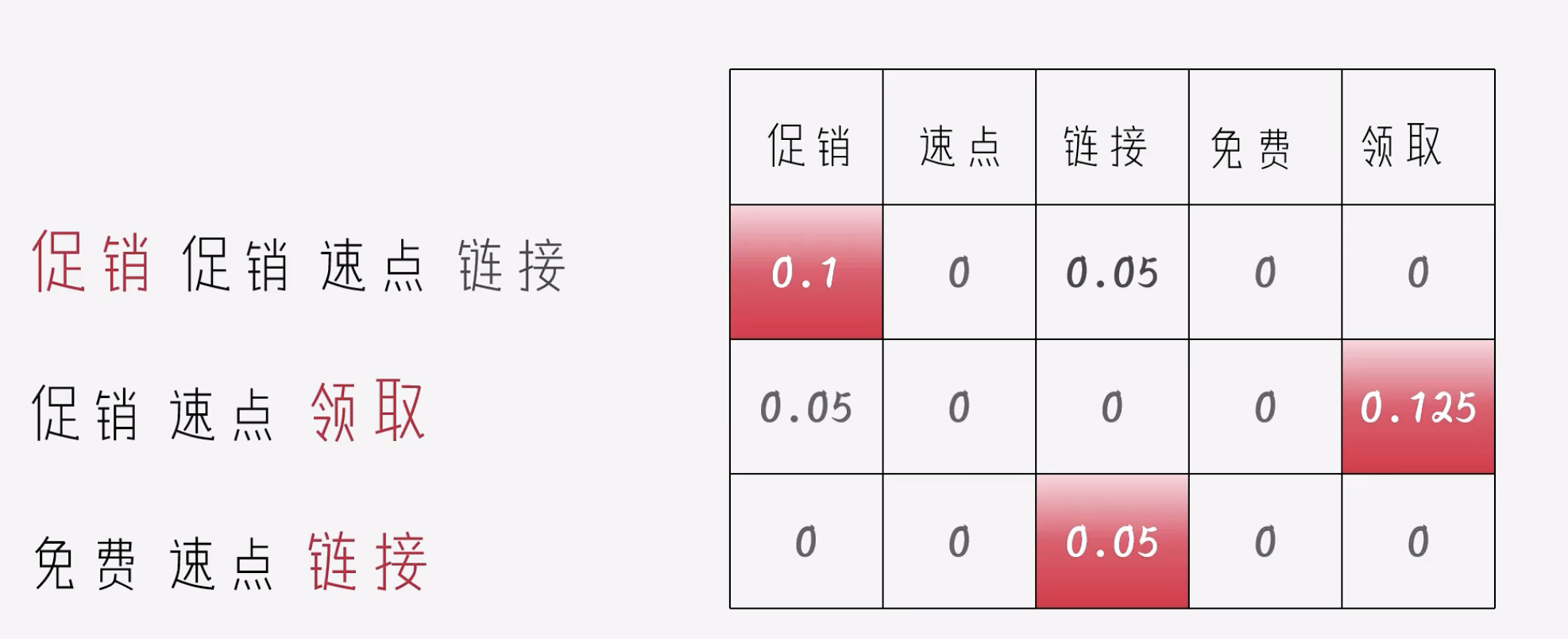
关键词
word2vec
随着上述算法的演进,文本的向量从有没有 -> 有多少 -> 有多稀缺,NLP的处理效果也越来越好,但是他们都有一个共同的问题,没有捕捉到词语的语意。
影评情绪分类
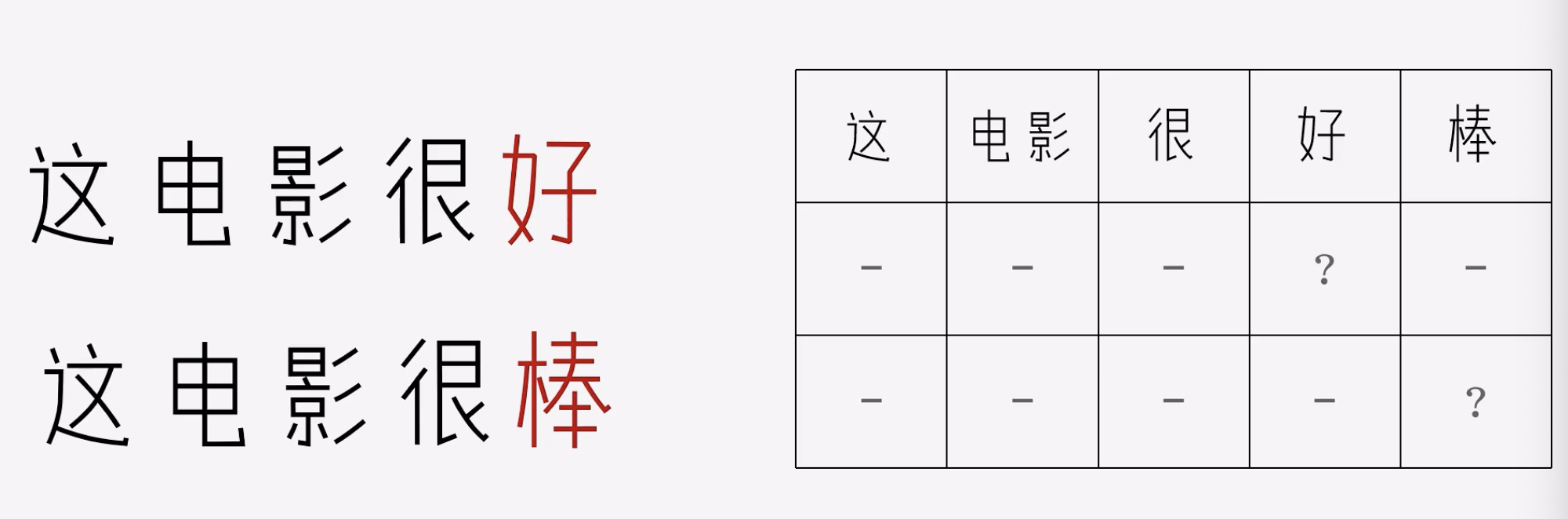
好和棒都是同一个意思,但是上述的词向量是彼此孤立的,捕捉不到他们其实是一个意思。
如何捕捉到好和棒是意思相同的词呢?
google的做法是: 如果好和棒周围经常有相同的词出现,那么他们就是类似的。这个就是Word2Vec
Word2Vec(google)
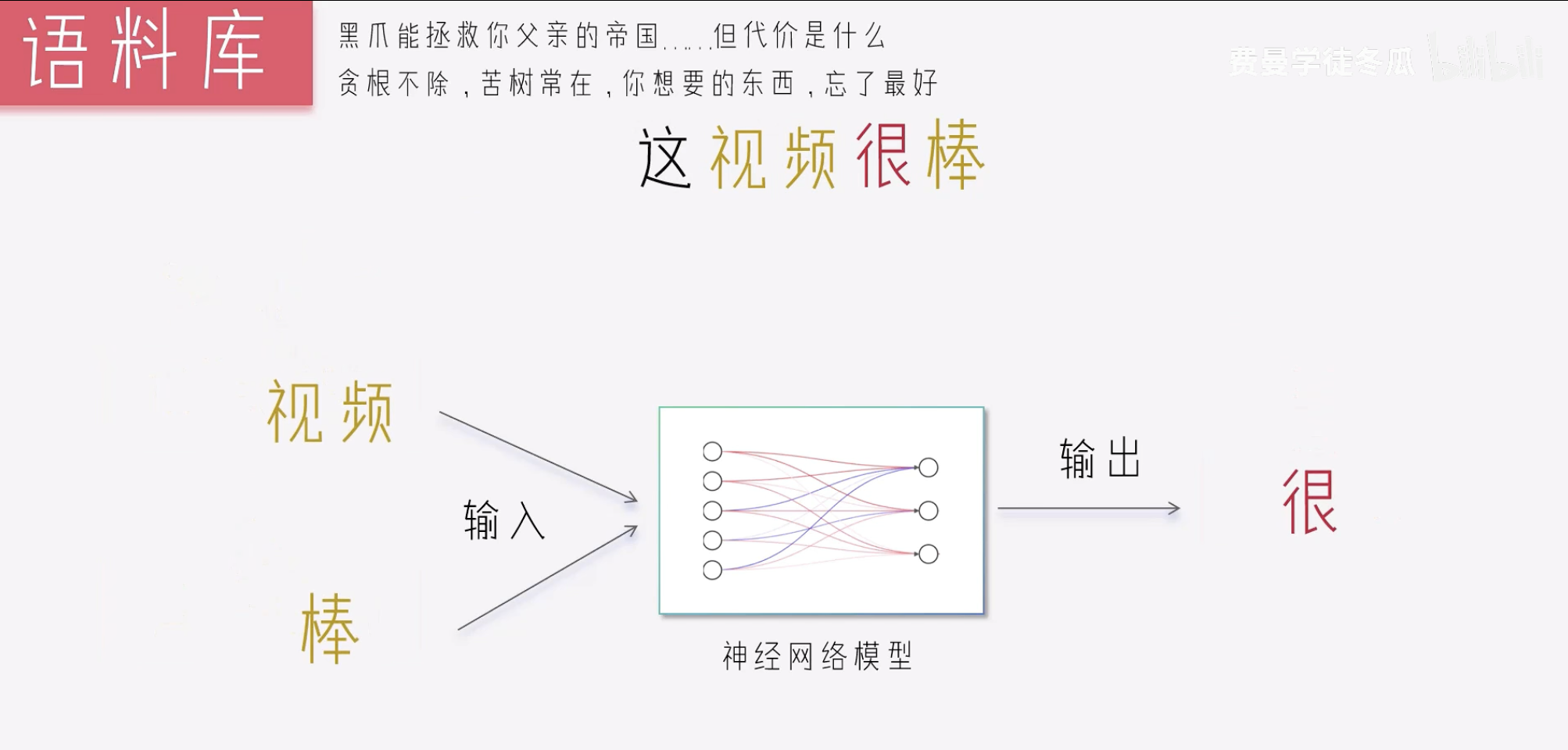
模型训练
训练过程
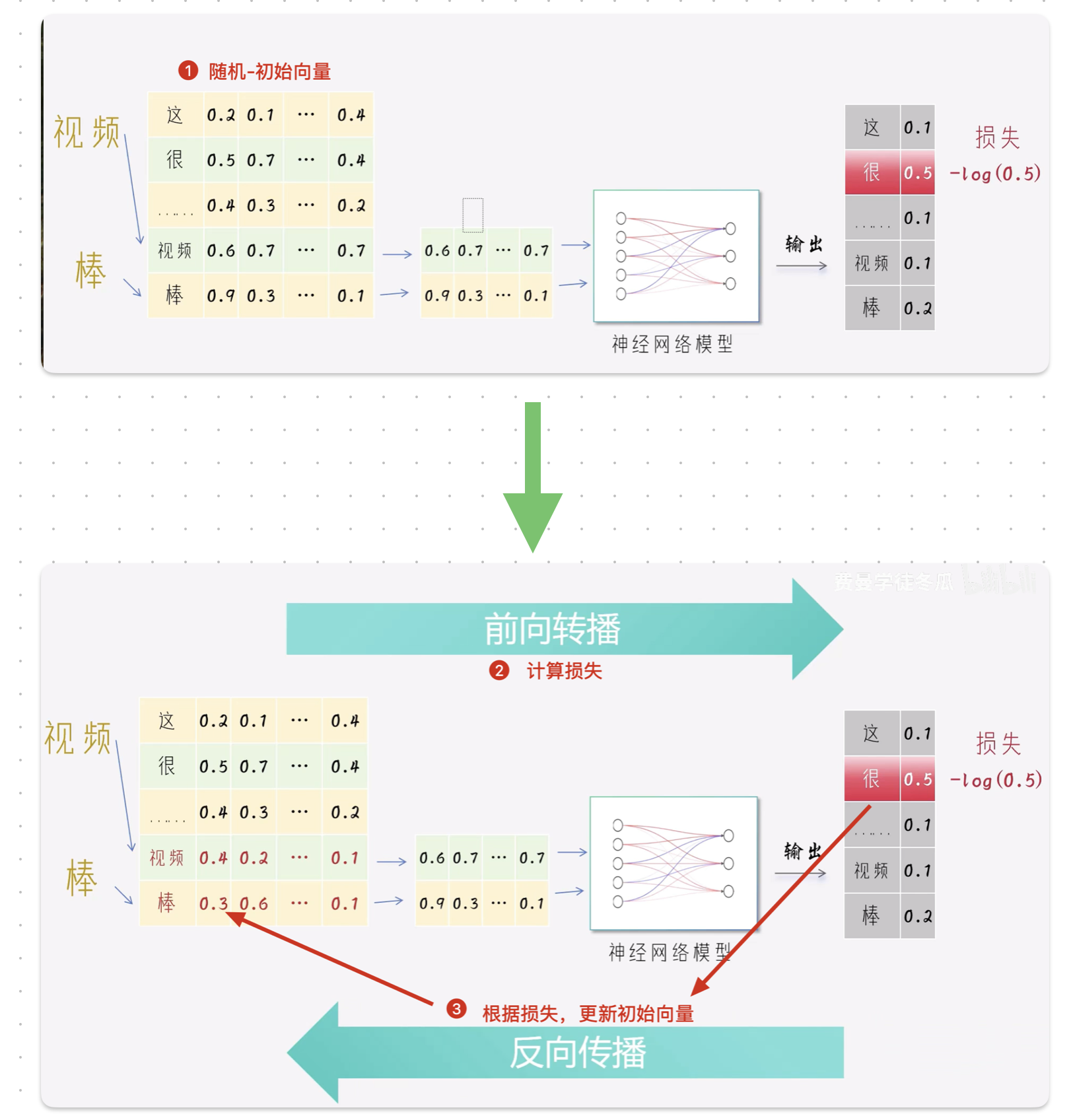
上述的训练过程会不断的进行, 原本随机初始化的向量,也会不断的调整,并在一次次调整中逐渐稳定下来,这个过程叫做收敛。
词表矩阵/嵌入矩阵(Word Embedding)
收敛之后,我们丢掉神经网络参数,保留词语的向量矩阵,这个叫作词表矩阵(或嵌入矩阵)
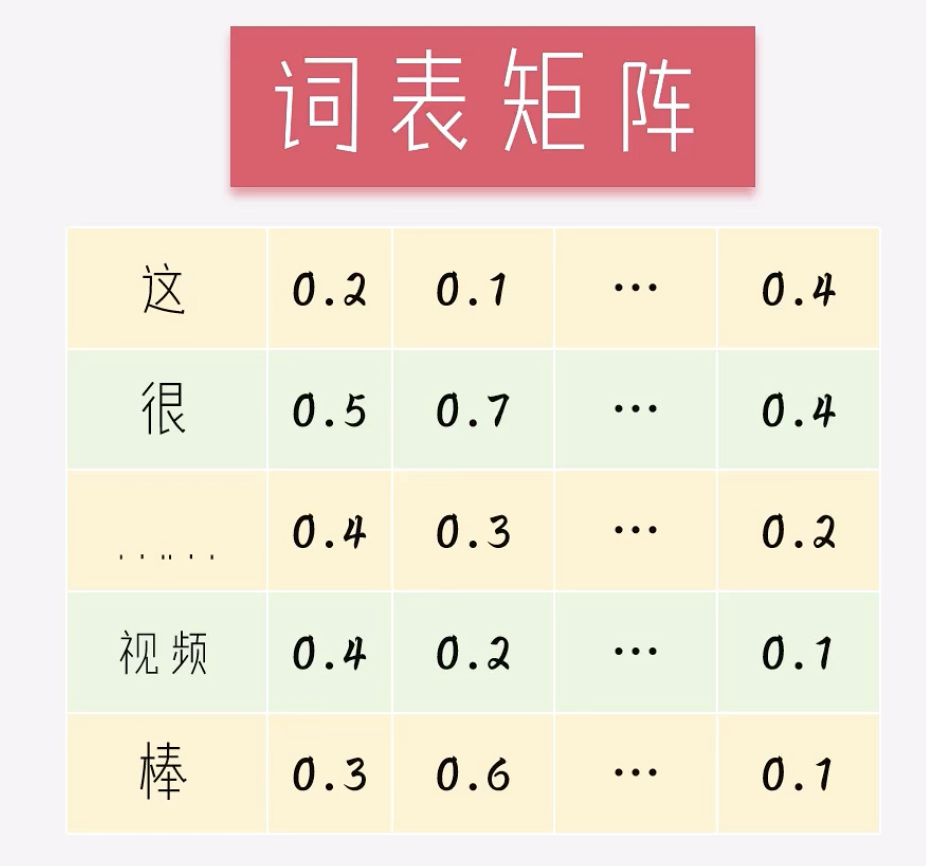
后续开展其它的NLP任务时,不再临时的计算词向量,拿着词语到词表中匹配,就可以得到词向量。
如果是词表中不存在的词怎么办,这种情况很少见,给一个默认值即可.
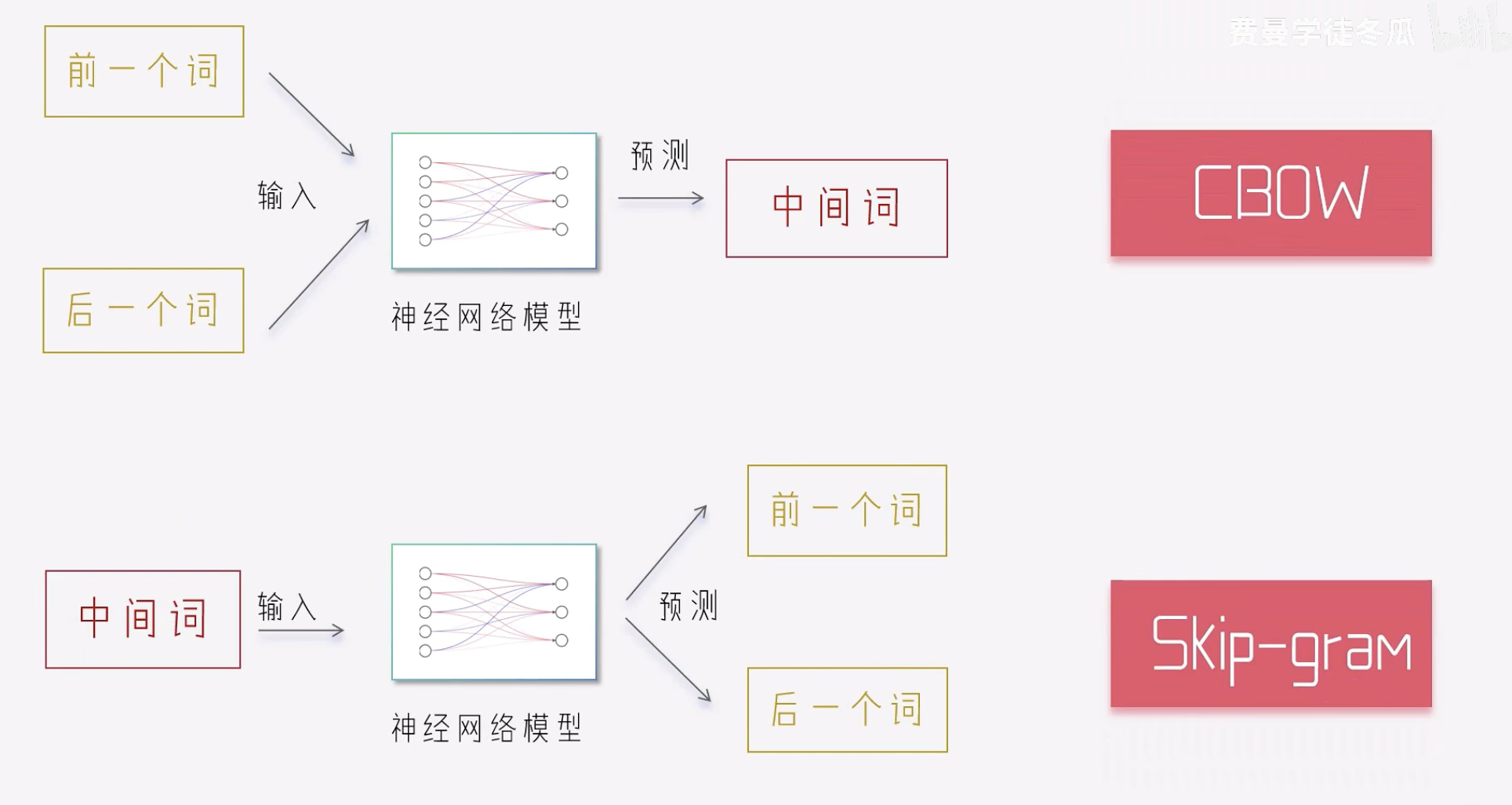
CBOW vs Skip-Gram
相似度
其实每一次预测,都是在问:猜猜我周围有谁,模型发现棒,好 经常出现在很 非常 等相同的词语旁边,就会意识到这两个词有相似的语意,这种相似性会体现在词表矩阵中。
我们可以用余弦相似度 计算向量的相关性.

Word2Vec的理念
想要了解一个人(词),看看他周围都有谁.
词表矩阵的缺陷
上述的方法均没有考虑词语的顺序。
比如:
我爱你和你爱我均有相同的词向量,在数学上二者是相等的。
而且没有考虑到一词多义的意思。
比如: Apple可以表示
苹果,也可以表示苹果手机.
接下来需要考虑的是:根据语境,动态计算词向量
Embedding模型
Transformer Attention机制: 可以让模型根据实际的上下文语境,捕捉到文本的语意.
目标
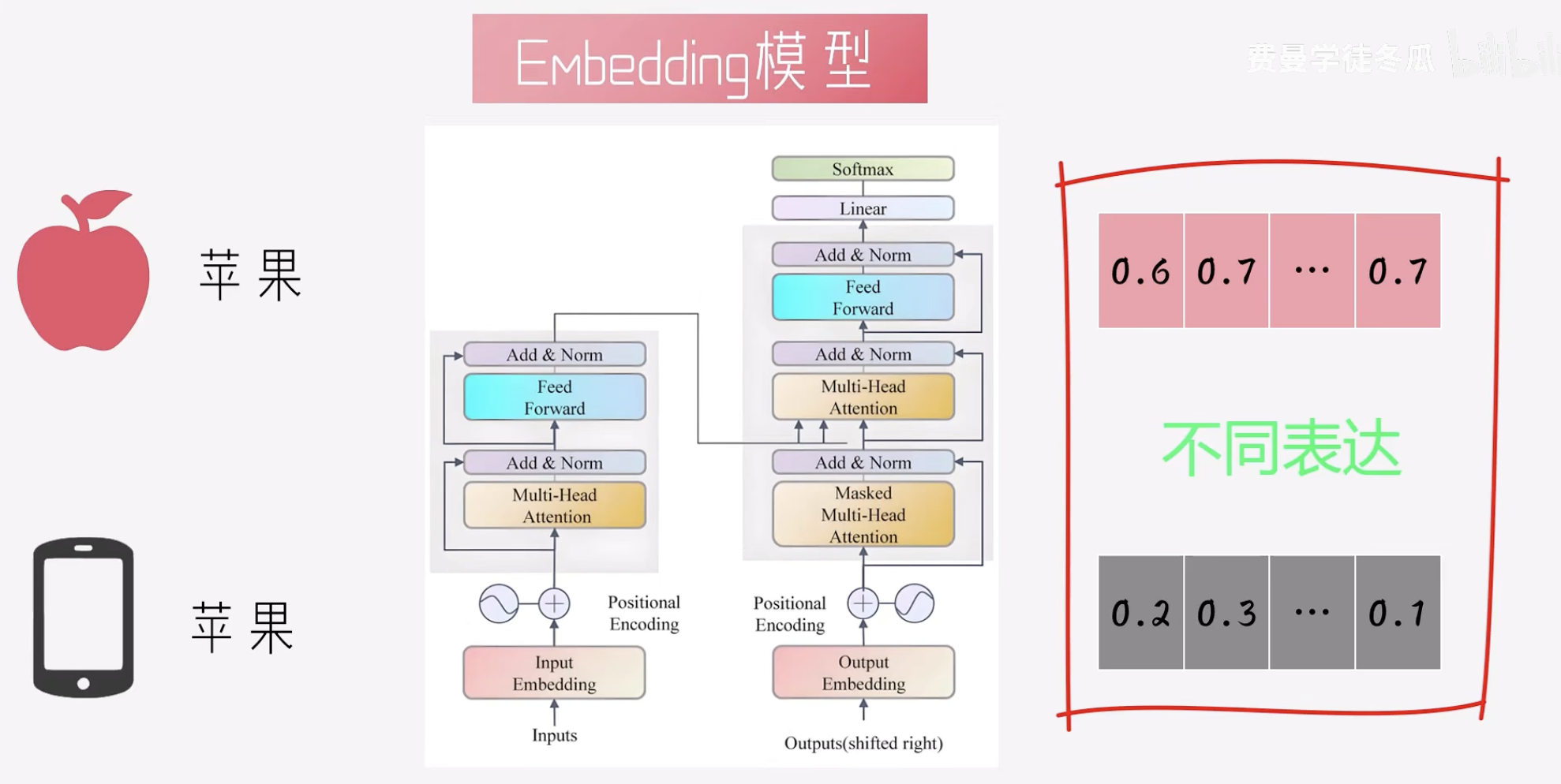
常见的有**BGE(BAAI General Embedding)**模型.
训练BGE
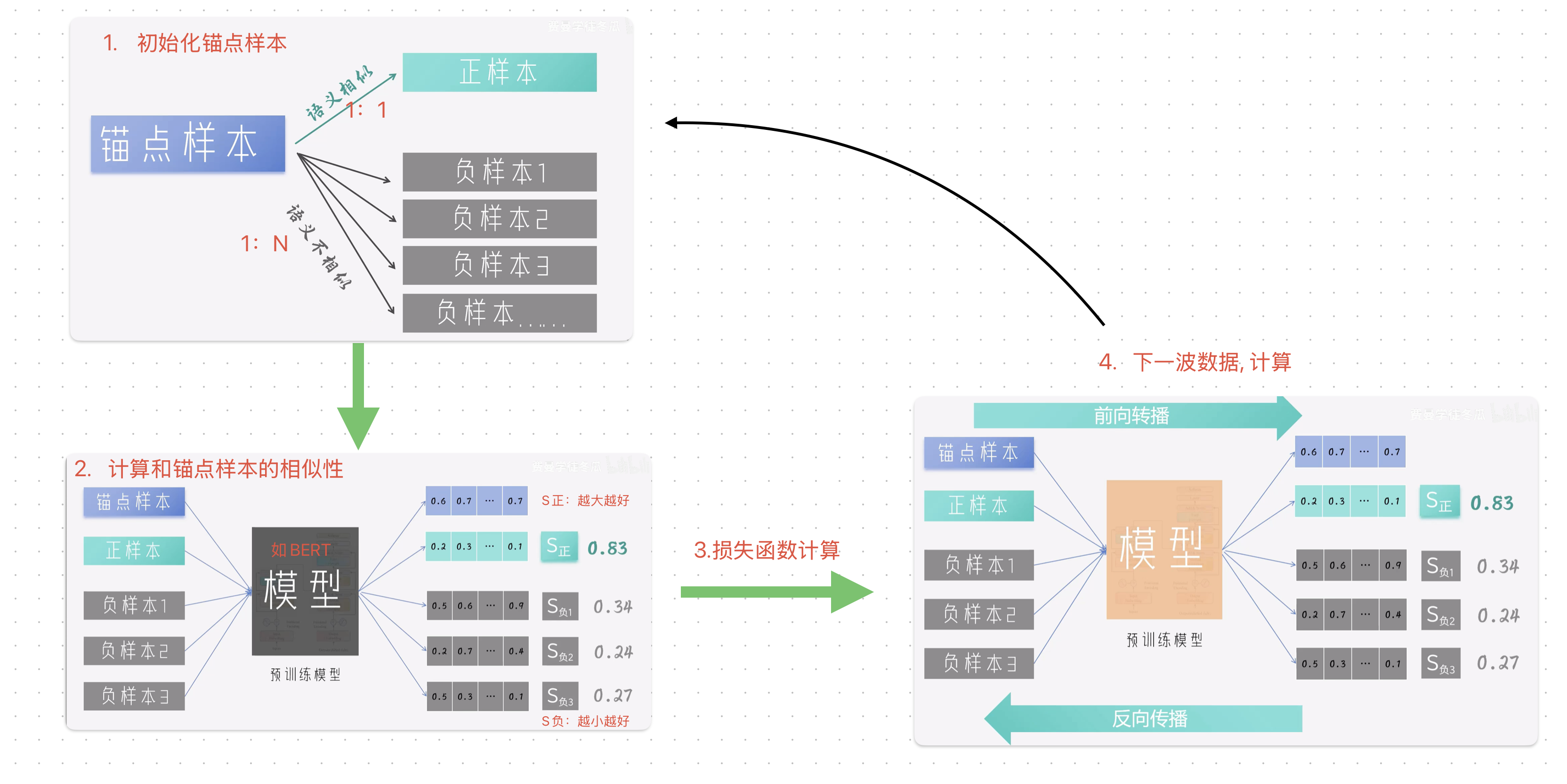
S正越大+S负越小,就说明模型的效果更好
损失函数

模型收敛
下次应用,不再是只匹配词表,而是将文本输入到调好的模型中,模型的attention机制会充分捕获上下文信息,根据语境动态计算词向量.
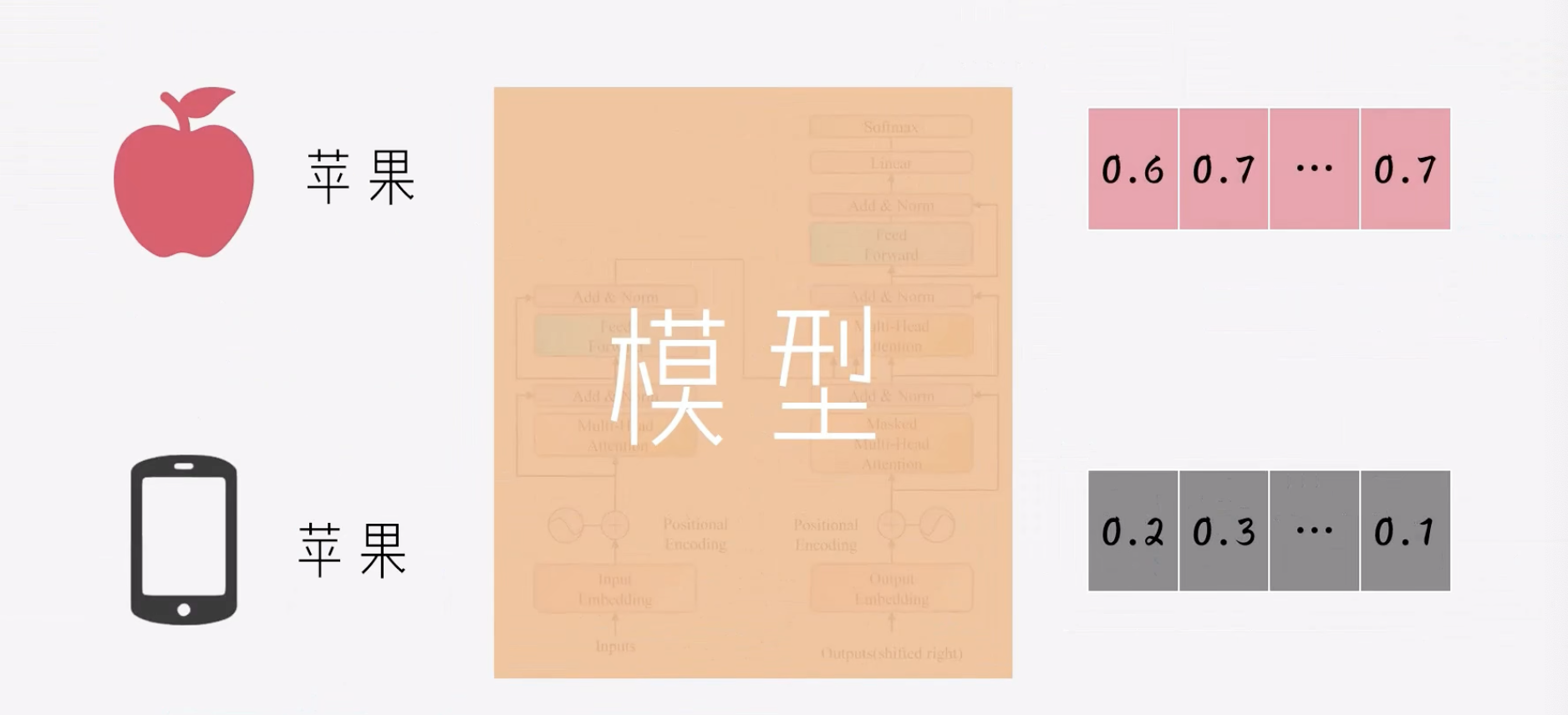
BEG样本

一句话,前方百计的用样本给模型制造难度,如果模型连这种大家来找茬的游戏都能搞定,那么生成的向量相比具有极高的语意区分度。
这种大家来找茬的方法,叫做对比学习
一句话总结BGE
- Transformer:
实现了语意的动态计算 - 对比学习 :`提升了语意的区分度
小节


















 9735
9735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









