




 本文通过Python演示如何统计《Hamlet》中主角Hamlet的出场频次,排除标点符号和大小写干扰,利用字典和列表进行数据处理和排序,最终展示排名前十的结果。
本文通过Python演示如何统计《Hamlet》中主角Hamlet的出场频次,排除标点符号和大小写干扰,利用字典和列表进行数据处理和排序,最终展示排名前十的结果。
实务中,我们经常需要统计某个词汇或事物出现的频度,如何才能实现呢?
事物与频度一一相对(映射),又要一分高下(排序),是字典和列表的拿手好戏。考虑到语言语法等差别,我们分别以常见的英文和中文为例。需要注意的是,目标文本应符合 UTF-8 编码标准,否则会报错。
《Hamlet》是莎翁所有戏剧中篇幅最长的一部,也是其最负盛名的剧本。全文 3200 余词,让我们看看主角 Hamlet 的出场频次,并向莎翁致敬!
考虑到英文的书写规则,首先需除外标点符号、特殊符号和大小写的干扰。
txt=txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': #"\"单独使用为转义符
txt=txt.replace(ch,' ')
return txt其次将得到的字符串切片,遍历计数,创建字典及键值对列表,然后根据值排序。
words=txt.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)然后将排序前十位输出:
for i in range(10):
word,count=items[i]
print('{0:<10}{1:>5}'.format(word,count)) #不显示次数则直接print(word)结果如下:
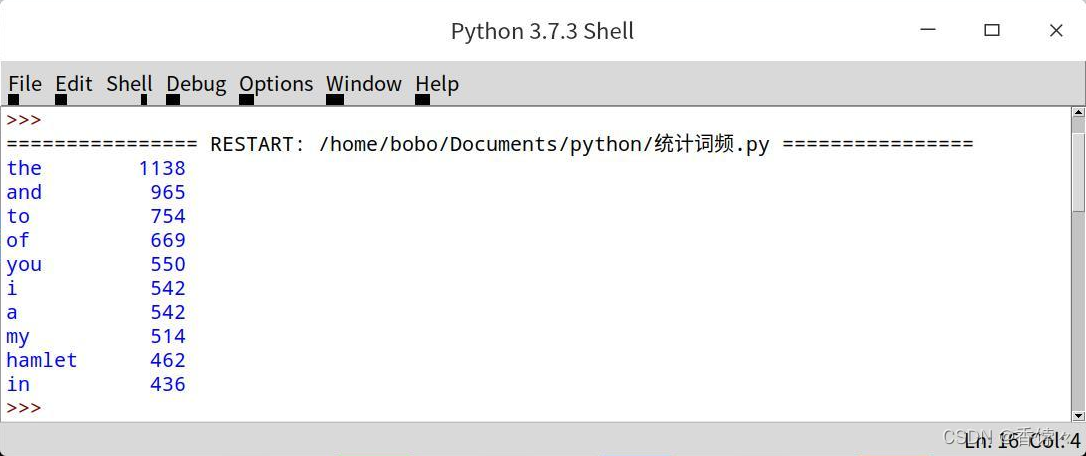
可见,王子骑着白马,闪亮登场的次数屈居第九,是不是很惊喜☺
完整代码:
#词频统计
def getTxt():
txt=open('hamlet.txt','r',encoding='utf-8').read() #注意文件路径
txt=txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt=txt.replace(ch,' ')
return txt
Txt=getTxt()
words=Txt.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print('{0:<10}{1:>5}'.format(word,count))参数 key=lambda x:x[1] 的含义,请参见:


















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











