






我的Flink版本为1.13.6
<flink.version>1.13.6</flink.version>FlinkSql读取本地文件系统的csv和json文件需要以下两个依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>然后我们在工程中建立一个示例文件data.csv,内容如下:
1,Inori,100
2,Kazumi,80
3,Sakura,70
4,Maki,60
5,Rin,50
6,Kyouko,40
7,Mio,30
8,Yukari,20
9,Aya,10随后建立一个scala类 CSVFileSystem
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object CSVFileSystem {
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val see: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tabEnv: StreamTableEnvironment = StreamTableEnvironment.create(see)
tabEnv.executeSql(
"""
|CREATE TABLE person(
|id INT,
|name STRING,
|age INT
|) WITH (
|'connector' = 'filesystem',
|'path' = 'file:///F:\Third\flinksql\data\data.csv',
|'format' = 'csv',
|'csv.field-delimiter' = ',',
|'csv.ignore-parse-errors' = 'true'
|)
|""".stripMargin)
tabEnv.sqlQuery("SELECT * FROM person").execute().print()
}
}
其中一些参数解释如下:
'connector' = 'filesystem'
指定表的连接器类型为filesystem。这意味着这个表将与本地文件系统交互,用于读写数据。
'path' = 'file:///F:\Third\flinksql\data\data.csv'
指定文件的本地路径
'format' = 'csv'
指定了文件的格式为CSV(逗号分隔值)。这意味着表中的数据将以CSV格式存储或读取。
'csv.field-delimiter' = ','
指定了CSV文件中字段的分隔符为逗号(,)
'csv.ignore-parse-errors' = 'true'
指定在解析CSV文件时,如果遇到解析错误,应该忽略这些错误而不是抛出异常。
最终的结果如下:
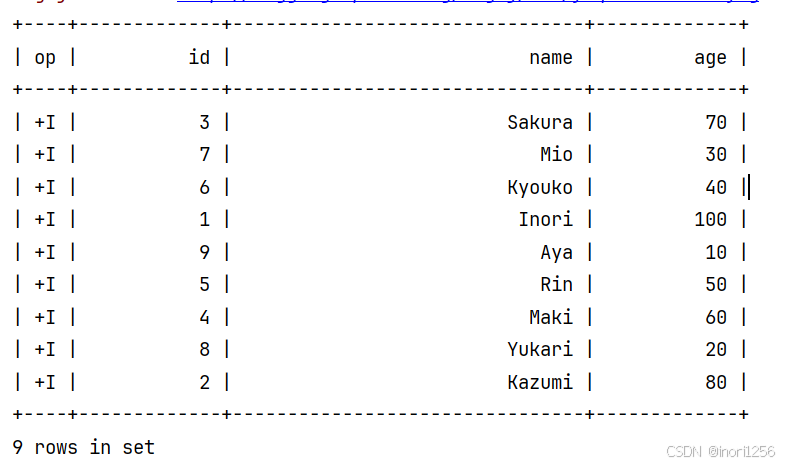
可以发现FlinkSQL建立的表自动多出了一列op,op是操作(operate)的意思+I代表这行数据是insert进入的。
再建立一个json数据文件data.log,注意不能是json格式的文件,因为这样的话会默认一个文件仅代表一个json对象而出现解析异常:
{"id":1,"name":"henry1","age":22,"gender":"男"}
{"id":2,"name":"henry2","age":18,"gender":"女"}
{"id":3,"name":"henry3","age":27,"gender":"男"}
{"id":4,"name":"henry4","age":19,"gender":"男"}
{"id":5,"name":"henry5","age":25,"gender":"女"}
{"id":6,"name":"henry6","age":21,"gender":"男"}
{"id":7,"name":"henry7","age":23,"gender":"女"}
{"id":8,"name":"henry8","age":20,"gender":"男"}
{"id":9,"name":"henry9","age":24,"gender":"女"}
{"id":10,"name":"henry10","age":26,"gender":"男"}建立一个scala类JSONFileSystem,内容如下
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object JSONFileSystem {
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val see: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tabEnv: StreamTableEnvironment = StreamTableEnvironment.create(see)
tabEnv.executeSql(
"""
|CREATE TABLE person(
|id INT,
|name STRING,
|age INT,
|gender STRING
|) WITH (
|'connector' = 'filesystem',
|'path' = 'file:///F:\Third\flinksql\data\data.log',
|'format' = 'json',
|'json.ignore-parse-errors' = 'true'
|)
|"""
.stripMargin)
tabEnv.sqlQuery("SELECT * FROM person").execute().print()
}
}
json解析无需指定分隔符,其余配置项与csv基本一致
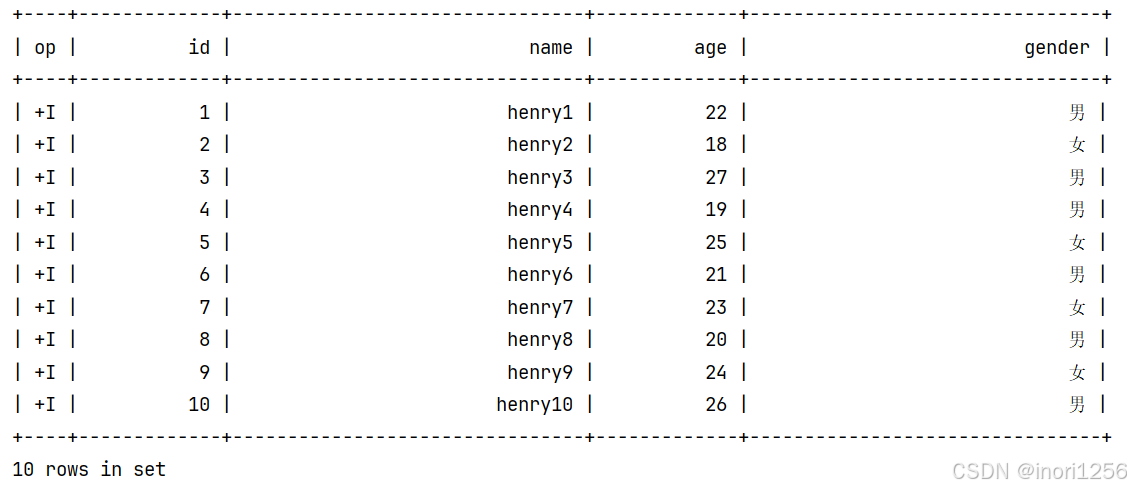
可以看到最终结果如下:

















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









