




 本文主要探讨C语言的字符集,包括通用字符集如ASCII、UTF-8和GB2312,以及C标准字符集的详细内容。讨论了源文件字符集与执行字符集的区别,多字节字符在源文件和执行环境中的表示,以及C标准对多字节字符序列的规定。
本文主要探讨C语言的字符集,包括通用字符集如ASCII、UTF-8和GB2312,以及C标准字符集的详细内容。讨论了源文件字符集与执行字符集的区别,多字节字符在源文件和执行环境中的表示,以及C标准对多字节字符序列的规定。
系列文章目录
前言
蓝色问号代表个人理解 绿色代表来源 红色问号代表尚有疑问
为什么要读标准?因为全面、权威,所有答案都在标准里面!
哪些人适合浏览本系列文章?不清楚C语言程序的组成,以及每个组成部分的详细内容
持续更新,码字不易,求点赞收藏
1、字符集
- 一是写入源文件的字符集,即当前编辑器页面使用的字符集?
- 二是执行环境中解释的字符集,执行字符集成员的值由实现定义,即执行时将写入源文件的字符集转换成执行时使用的字符集?
- 本节要求之外的任何其他字符都是特定于语言环境的
?
#include<bits/stdc++.h>
using namespace std;
int main(int argc,char *argv[]){
printf("修仙"); //理论上UTF-8是支持中文的,但是printf的中文不对
return 0; //输出 淇粰
}
//字符集改成GB2312 出现上面的输出
#include<bits/stdc++.h>
using namespace std;
int main(int argc,char *argv[]){
printf("淇�浠�"); //鐞嗚�轰笂UTF-8鏄�鏀�鎸佷腑鏂囩殑锛屼絾鏄痯rintf鐨勪腑鏂囦笉瀵�
//写入源文件的字符集是UTF-8,执行字符集可能根据的操作系统的字符集是GB2312
return 0;
}
1.1、通用字符集
ASCII
美国信息交换标准代码,等同于国际标准ISO/IEC 646。所以这是世界通用的编码,其他大部分字符集都兼容,所以不同字符集下的代码主体就不会有太大改变,而且编程语言都尽量避免使用地域特定的字符?
| Bin | Dec | Hex | 缩写/字符 | 解释 |
| 00000000 | 0 | 00 | NUL(null) | 空字符 |
| 00000001 | 1 | 01 | SOH(start of headling) | 标题开始 |
| 00000010 | 2 | 02 | STX (start of text) | 正文开始 |
| 00000011 | 3 | 03 | ETX (end of text) | 正文结束 |
| 00000100 | 4 | 04 | EOT (end of transmission) | 传输结束 |
| 00000101 | 5 | 05 | ENQ (enquiry) | 请求 |
| 00000110 | 6 | 06 | ACK (acknowledge) | 收到通知 |
| 00000111 | 7 | 07 | BEL (bell) | 响铃 |
| 00001000 | 8 | 08 | BS (backspace) | 退格 |
| 00001001 | 9 | 09 | HT (horizontal tab) | 水平制表符 |
| 00001010 | 10 | 0A | LF (NL line feed, new line) | 换行键 |
| 00001011 | 11 | 0B | VT (vertical tab) | 垂直制表符 |
| 00001100 | 12 | 0C | FF (NP form feed, new page) | 换页键 |
| 00001101 | 13 | 0D | CR (carriage return) | 回车键 |
| 00001110 | 14 | 0E | SO (shift out) | 不用切换 |
| 00001111 | 15 | 0F | SI (shift in) | 启用切换 |
| 00010000 | 16 | 10 | DLE (data link escape) | 数据链路转义 |
| 00010001 | 17 | 11 | DC1 (device control 1) | 设备控制1 |
| 00010010 | 18 | 12 | DC2 (device control 2) | 设备控制2 |
| 00010011 | 19 | 13 | DC3 (device control 3) | 设备控制3 |
| 00010100 | 20 | 14 | DC4 (device control 4) | 设备控制4 |
| 00010101 | 21 | 15 | NAK (negative acknowledge) | 拒绝接收 |
| 00010110 | 22 | 16 | SYN (synchronous idle) | 同步空闲 |
| 00010111 | 23 | 17 | ETB (end of trans. block) | 传输块结束 |
| 00011000 | 24 | 18 | CAN (cancel) | 取消 |
| 00011001 | 25 | 19 | EM (end of medium) | 介质中断 |
| 00011010 | 26 | 1A | SUB (substitute) | 替补 |
| 00011011 | 27 | 1B | ESC (escape) | 溢出 |
| 00011100 | 28 | 1C | FS (file separator) | 文件分割符 |
| 00011101 | 29 | 1D | GS (group separator) | 分组符 |
| 00011110 | 30 | 1E | RS (record separator) | 记录分离符 |
| 00011111 | 31 | 1F | US (unit separator) | 单元分隔符 |
| 00100000 | 32 | 20 | (space) | 空格 |
| 00100001 | 33 | 21 | ! | |
| 00100010 | 34 | 22 | " | |
| 00100011 | 35 | 23 | # | |
| 00100100 | 36 | 24 | $ | |
| 00100101 | 37 | 25 | % | |
| 00100110 | 38 | 26 | & | |
| 00100111 | 39 | 27 | ’ | |
| 00101000 | 40 | 28 | ( | |
| 00101001 | 41 | 29 | ) | |
| 00101010 | 42 | 2A | * | |
| 00101011 | 43 | 2B | + | |
| 00101100 | 44 | 2C | , | |
| 00101101 | 45 | 2D | - | |
| 00101110 | 46 | 2E | . | |
| 00101111 | 47 | 2F | / | |
| 00110000 | 48 | 30 | 0 | |
| 00110001 | 49 | 31 | 1 | |
| 00110010 | 50 | 32 | 2 | |
| 00110011 | 51 | 33 | 3 | |
| 00110100 | 52 | 34 | 4 | |
| 00110101 | 53 | 35 | 5 | |
| 00110110 | 54 | 36 | 6 | |
| 00110111 | 55 | 37 | 7 | |
| 00111000 | 56 | 38 | 8 | |
| 00111001 | 57 | 39 | 9 | |
| 00111010 | 58 | 3A | : | |
| 00111011 | 59 | 3B | ; | |
| 00111100 | 60 | 3C | < | |
| 00111101 | 61 | 3D | = | |
| 00111110 | 62 | 3E | > | |
| 00111111 | 63 | 3F | ? | |
| 01000000 | 64 | 40 | @ | |
| 01000001 | 65 | 41 | A | |
| 01000010 | 66 | 42 | B | |
| 01000011 | 67 | 43 | C | |
| 01000100 | 68 | 44 | D | |
| 01000101 | 69 | 45 | E | |
| 01000110 | 70 | 46 | F | |
| 01000111 | 71 | 47 | G | |
| 01001000 | 72 | 48 | H | |
| 01001001 | 73 | 49 | I | |
| 01001010 | 74 | 4A | J | |
| 01001011 | 75 | 4B | K | |
| 01001100 | 76 | 4C | L | |
| 01001101 | 77 | 4D | M | |
| 01001110 | 78 | 4E | N | |
| 01001111 | 79 | 4F | O | |
| 01010000 | 80 | 50 | P | |
| 01010001 | 81 | 51 | Q | |
| 01010010 | 82 | 52 | R | |
| 01010011 | 83 | 53 | S | |
| 01010100 | 84 | 54 | T | |
| 01010101 | 85 | 55 | U | |
| 01010110 | 86 | 56 | V | |
| 01010111 | 87 | 57 | W | |
| 01011000 | 88 | 58 | X | |
| 01011001 | 89 | 59 | Y | |
| 01011010 | 90 | 5A | Z | |
| 01011011 | 91 | 5B | [ | |
| 01011100 | 92 | 5C | | | |
| 01011101 | 93 | 5D | ] | |
| 01011110 | 94 | 5E | ^ | |
| 01011111 | 95 | 5F | _ | |
| 01100000 | 96 | 60 | ` | |
| 01100001 | 97 | 61 | a | |
| 01100010 | 98 | 62 | b | |
| 01100011 | 99 | 63 | c | |
| 01100100 | 100 | 64 | d | |
| 01100101 | 101 | 65 | e | |
| 01100110 | 102 | 66 | f | |
| 01100111 | 103 | 67 | g | |
| 01101000 | 104 | 68 | h | |
| 01101001 | 105 | 69 | i | |
| 01101010 | 106 | 6A | j | |
| 01101011 | 107 | 6B | k | |
| 01101100 | 108 | 6C | l | |
| 01101101 | 109 | 6D | m | |
| 01101110 | 110 | 6E | n | |
| 01101111 | 111 | 6F | o | |
| 01110000 | 112 | 70 | p | |
| 01110001 | 113 | 71 | q | |
| 01110010 | 114 | 72 | r | |
| 01110011 | 115 | 73 | s | |
| 01110100 | 116 | 74 | t | |
| 01110101 | 117 | 75 | u | |
| 01110110 | 118 | 76 | v | |
| 01110111 | 119 | 77 | w | |
| 01111000 | 120 | 78 | x | |
| 01111001 | 121 | 79 | y | |
| 01111010 | 122 | 7A | z | |
| 01111011 | 123 | 7B | { | |
| 01111100 | 124 | 7C | ||
| 01111101 | 125 | 7D | } | |
| 01111110 | 126 | 7E | ~ | |
| 01111111 | 127 | 7F | DEL (delete) | 删除 |
UTF-8
针对Unicode的一种可变长度字符编码,支持几乎所有字符。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部分修改后,便可继续使用
GB2312
适用于汉字处理、汉字通信等系统之间的信息交换,支持简体中文
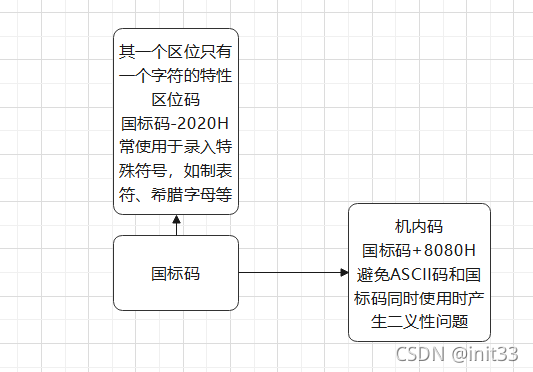
Unicode
它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求
1.2、C标准字符集
基本源文件字符集和基本执行字符集
| 基本源文件字符集和基本执行字符集必须存在 | |
|---|---|
| 26个大写字母 | A B C D E F G H I J K L M N O P Q R S T U V W X Y Z |
| 26个小写字母 | a b c d e f g h i j k l m n o p q r s t u v w x y z |
| 10个十进制数字字符 | 0 1 2 3 4 5 6 7 8 9 |
| 29个图形字符 | ! " # % & ’ ( ) * + , - . / : ; < = > ? [ \ ] ^ _ { 竖线 } ~ |
| 空格字符 | |
| 3个控制字符(横向制表\t、纵向制表\v、换页\f) |
-
0之后的数字字符的值比前一个大1
-
在字符常量或字符串常量中,执行字符集的成员应由源字符集的相应成员或由反斜杠\后跟一个或多个字符组成的转义序列表示
-
执行字符集还包括告警\a、退格\b、回车\r、新行\n、所有位为零的空字符\0(用于终止字符串)、源文件指示每行文本结尾的某种方式视为单个新行字符
-
Dos、Windows回车+换行(CR+LF)表示下一行
-
UNIX/Linux换行符(LF)表示下一行
-
苹果机(MAC OS系统)回车符(CR)表示下一行
若在源文卷(source file)中遇到其他字符,则其行为是未定义的。除非出现在字符常量(character constants)、串字面值(string literals)、前导文卷名(header names)、注释(comment)或永不被转换为词法元素(token)的预处理词法元素(token)中
ASCII != C字符集
多字节字符
源文件字符集中可包含多字节字符,用于表示扩展字符集的成员, 比如,UTF-8。执行字符集中也可以包含多字节字符,且它们的编码不一定要与源字符集中的多字节字符的编码相同, 比如,GB2312。
- 应存之前定义的单字节字符
- 任何其他成员的存在、意义和表示都是特定于语言环境的
- 多字节字符可以具有依赖于状态的编码,其中每个多字节字符序列以初始移位状态开始,并在序列中遇到特定多字节字符时进入其他实现定义的移位状态。在初始移位状态下,所有单字节字符保留其通常的解释,并且不会改变移位状态。序列中后续字节的解释是当前移位状态的函数?
- 所有位为零的字节应解释为与移位状态无关的空字符?
- 所有位为零的字节不得出现在多字节字符的第二个或后续字节中
- 源文件中注释、字符串、字符常量或头文件名应以初始移位状态开始和结束?
- 源文件中注释、字符串、字符常量或头文件名应由一系列有效的多字节字符组成?
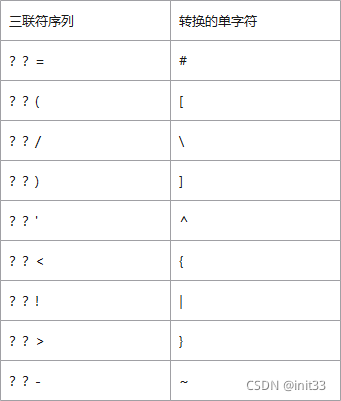
三联符序列
为了使代码能用任何非ASCII的字符集编写,但是有些字符集缺少这些字符。
2、字符输入?
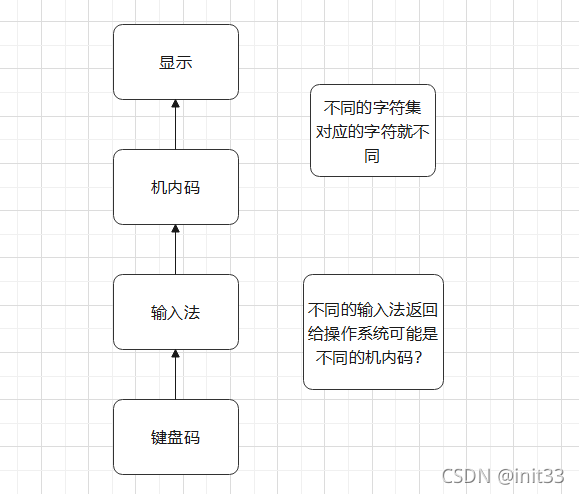
3、字符显示
活动位置是显示设备上输出的下一个字符的位置,将可打印字符(由isprint定义)写入显示设备的是在活动位置显示该字符的图形表示,然后将活动位置前进到当前行的下一个位置。打印方向是特定于区域设置的。如果活动位置位于直线的最终位置(如果有),则行为未指定。
| (警报)产生声音或可见警报 | 激活位置不得改变 |
| (退格)将活动位置移动到当前行上的上一个位置 | 如果激活位置位于直线的初始位置,则行为未指定 |
| (“表单馈送”)将活动位置移动到下一逻辑页开始处的初始位置 | |
| (“新行”)将活动位置移动到下一行的初始位置 | |
| (“回车”)将激活位置移动到当前行的初始位置 | |
| (“水平制表符”)将活动位置移动到当前行上的下一个水平制表位置 | 如果活动位置位于或超过上次定义的水平制表位置,则行为未指定。 |
| (“垂直选项卡”)将活动位置移动到下一个垂直制表位置的初始位置 | 如果活动位置位于或超过上次定义的垂直制表位置,则行为未指定。 |
以上纯属个人观点,欢迎大佬批评指正
https://blog.youkuaiyun.com/init33/article/details/121258745 ↩︎
https://blog.youkuaiyun.com/init33/article/details/121318734 ↩︎
https://blog.youkuaiyun.com/init33/article/details/121319873 ↩︎
https://blog.youkuaiyun.com/init33/article/details/121323883 ↩︎
https://blog.youkuaiyun.com/init33/article/details/121323943 ↩︎
https://blog.youkuaiyun.com/init33/article/details/121323932 ↩︎
https://blog.youkuaiyun.com/init33/article/details/121323958 ↩︎
https://editor.youkuaiyun.com/md/?articleId=121323994 ↩︎

















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









