




一、作业头
| 这个作业属于哪个课程 | 自然语言处理 |
|---|---|
| 这个作业要求在哪里 | https://bbs.youkuaiyun.com/topics/614556240 |
| 我在这个课程的目标是 | 学好这一门课程、保证期末顺利通过 |
| 这个作业在哪个具体方面帮助我实现目标 | 通过代码练习、以及从参考他人的资料来完善自己的不足 |
| 参考文献 | https://cloud.tencent.com/developer/article/2208137 |
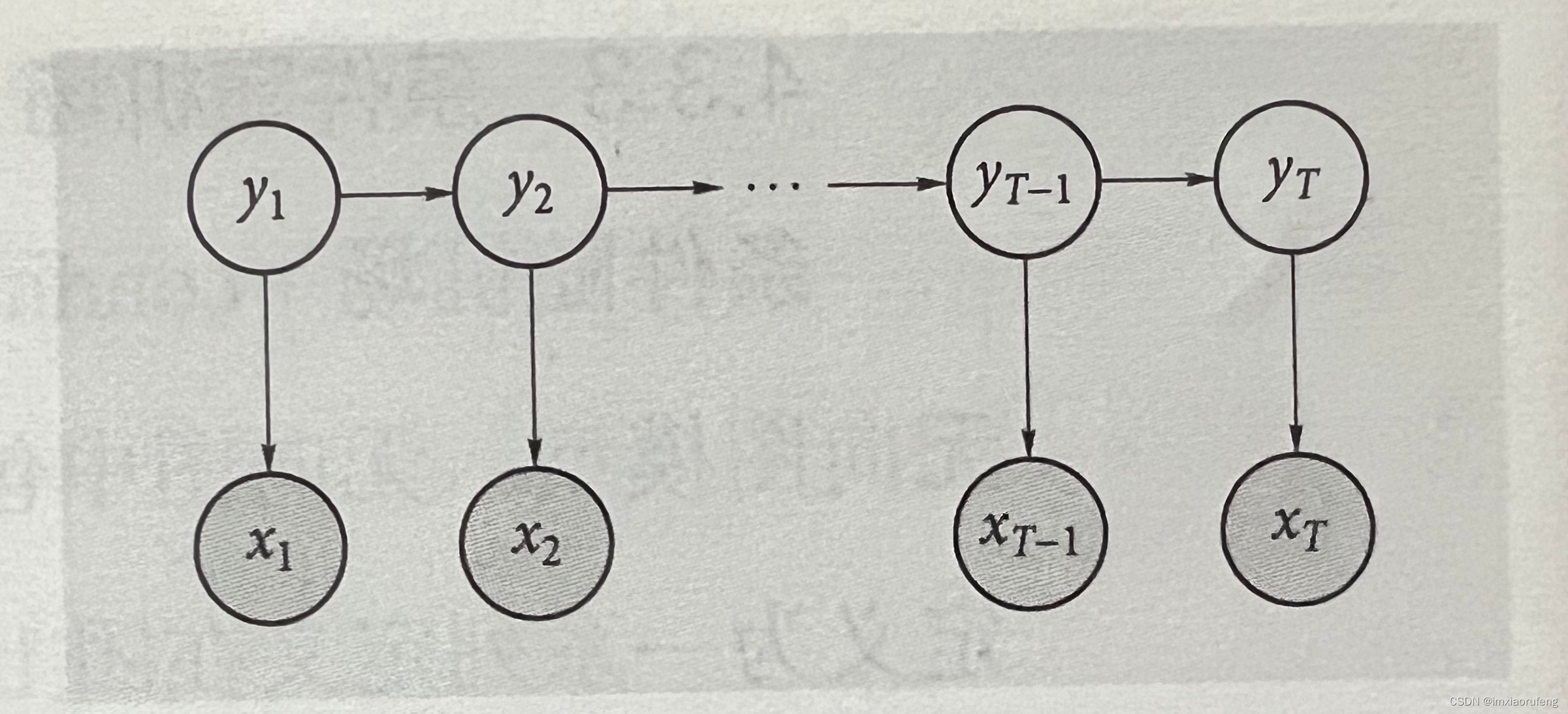
二、HMM模型
隐马尔可夫模型是一种用于序列标注问题的统计模型。它在语言识别,自然语言处理,模式识别等领域得到广泛的应用。它利用马尔可夫链建模隐含的状态转移关系,并通过概率分布描述状态之间的转移概率;同时,通过观测值与状态之间的条件概率分布,描述了状态生成观测值的过程。
三、HMM的模型参数

利用“1998人民日报词性标注语料库”进行模型的训练。
# 统计words和tags
words = set()
tags = set()
for words_with_tag in sentences:
for word_with_tag in words_with_tag:
word, tag = word_with_tag
words.add(word)
tags.add(tag)
words = list(words)
tags = list(tags)
# 统计 词性到词性转移矩阵A 词性到词转移矩阵B 初始向量pi
# 先初始化
A = {
tag: {
tag: 0 for tag in tags} for tag in tags}
B = {
tag: {
word: 0 for word in words} for tag in tags}
pi = {
tag: 0 for tag in tags}
# 统计A,B
for words_with_tag in sentences:
head_word, head_tag = words_with_tag[0]
pi[head_tag] += 1
B[head_tag][head_word] += 1
for i in range(1, len(words_with_tag)):
A[words_with_tag[i-1][1]] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









