







 本文详细介绍了在阿里云上部署Hadoop集群时遇到的问题及解决方法,包括配置内网名称、解决namenode启动错误、设置外网IP访问以及避免mapreduce作业卡顿等关键步骤。
本文详细介绍了在阿里云上部署Hadoop集群时遇到的问题及解决方法,包括配置内网名称、解决namenode启动错误、设置外网IP访问以及避免mapreduce作业卡顿等关键步骤。
在阿里云上部署完hadoop,必须要给内网指定名称,否则运行namenode和SecondaryNameNode会出错,运行不起来
FATAL org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.net.BindException: Problem binding to [node01:9000] java.net.BindException: Cannot assign requested address; For more details see: http://wiki.apache.org/hadoop/BindException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:720)
at org.apache.hadoop.ipc.Server.bind(Server.java:424)
at org.apache.hadoop.ipc.Server$Listener.<init>(Server.java:573)
at org.apache.hadoop.ipc.Server.<init>(Server.java:2206)
at org.apache.hadoop.ipc.RPC$Server.<init>(RPC.java:944)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server.<init>(ProtobufRpcEngine.java:537)
at org.apache.hadoop.ipc.ProtobufRpcEngine.getServer(ProtobufRpcEngine.java:512)
at org.apache.hadoop.ipc.RPC$Builder.build(RPC.java:789)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.<init>(NameNodeRpcServer.java:331)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createRpcServer(NameNode.java:627)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:600)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:765)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:749)
这时需要配置/etc/hosts
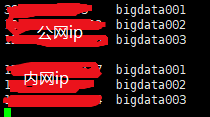
再删除logs和data格式化namenode即可
然而之后再运行mapreduce程序时,依旧会出问题,会一直卡再某个运行job上,查看日志可以发现
2020-05-23 23:05:43,145 INFO [Thread-56] org.apache.hadoop.hdfs.DFSClient: Exception in createBlockOutputStream java.io.IOException: Got error, status message , ack with firstBadLink as 172.xx.xx.xx:50010(我的内网ip) at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:140) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1363) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1266) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:449) 这是因为在运行mapreduce时,走的是内网ip,这样根本没法连接到其它服务器,因此要设置运行时走外网ip,在hdfs-site.xml中设置 <!-- 如果是通过公网IP访问阿里云上内网搭建的集群 --> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> <description>only cofig in clients</description> </property>
即:hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata003:50090</value>
</property>
<!-- 如果是通过公网IP访问阿里云上内网搭建的集群 -->
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
<description>only cofig in clients</description>
</property>
</configuration>
这样就设置好啦,在重启hadoop和yarn运行就不会报错了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









